對於一個網站來說,在執行很長一段時間後,資料庫瓶頸問題會越來越暴露出來。作為運維人員,對資料庫做必要的優化十分重要!
下面總結以往查閱到的以及自己工作中的一些優化操作經驗,並根據OSI七層模型從下往上進行優化mysql資料庫記錄。
一:物理層面
1、cpu:2-16個 2*4雙四核,L1L2越大越好
2、記憶體:越大越好
3、磁碟:SAS或者固態 300G*12磁碟越多IO越高
raid 0>10>5>1
4、網路卡:千兆
5、slave的配置最好大於等於master
二、系統配置
如下,配置系統核心引數/etc/sysctl.conf(配置後,使用sysctl -p使之生效)
net.ipv4.tcp_fin_timeout = 2
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_keepalive_time =600
net.ipv4.ip_local_port_range = 4000 65000
net.ipv4.tcp_max_syn_backlog = 16384
net.ipv4.tcp_max_tw_buckets = 36000
net.ipv4.route.gc_timeout = 100
net.ipv4.tcp_syn_retries = 1
net.ipv4.tcp_synack_retries = 1
net.core.somaxconn = 16384
net.core.netdev_max_backlog = 16384
net.ipv4.tcp_max_orphans = 16384
vm.swappiness=0 //儘量不使用swap
vm.dirty_backgroud_ratio 5-10
vm.dirty_ratio //上面的值的兩倍 將作業系統的髒資料刷到磁碟
三:mysql的安裝
MySQL資料庫的線上環境安裝,建議採取編譯安裝的方式,這樣效能會有較大的提升。伺服器系統則建議CentOS6.7 X86_64,原始碼包的編譯引數會預設以Debug模式生成二進位制程式碼,而Debug模式給MySQL帶來的效能損失是比較大的,所以當我們編譯準備安裝的產品程式碼時,一定不要忘記使用--without-debug引數禁止Debug模式。如果把--with-mysqld-ldflags和--with-client-ld-flags兩個編譯引數設定為--all-static的話,可以告訴編譯器以靜態的方式編譯,編譯結果將得到最高的效能。使用靜態編譯和使用動態編譯的程式碼相比,效能差距可能會達到5%至10%之多。在後面我會跟大家分享我們線上MySQL資料庫的編譯引數,大家可以參考下,然後根據自己的線上環境自行修改內容。
下面是對mysql服務配置檔案my.cnf的詳解:
[client]
port = 3306
# 客戶端埠號為3306
socket = /data/3306/mysql.sock
default-character-set = utf8
# 客戶端字符集,(控制character_set_client、character_set_connection、character_set_results)
[mysql]
no-auto-rehash
# 僅僅允許使用鍵值的updates和deletes
[mysqld]
# 組包括了mysqld服務啟動的引數,它涉及的方面很多,其中有MySQL的目錄和檔案,通訊、網路、資訊保安,記憶體管理、優化、查詢快取區,還有MySQL日誌設定等。
user = mysql
# mysql_safe指令碼使用MySQL執行使用者(編譯時--user=mysql指定),推薦使用mysql使用者。
port = 3306
# MySQL服務執行時的埠號。建議更改預設埠,預設容易遭受攻擊。
socket = /data/3306/mysql.sock
# socket檔案是在Linux/Unix環境下特有的,使用者在Linux/Unix環境下客戶端連線可以不通過TCP/IP網路而直接使用unix socket連線MySQL。
basedir = /application/mysql
# mysql程式所存放路徑,常用於存放mysql啟動、配置檔案、日誌等
datadir = /data/3306/data
# MySQL資料存放檔案(極其重要)
character-set-server = utf8
# 資料庫和資料庫表的預設字符集。(推薦utf8,以免導致亂碼)
log-error=/data/3306/mysql.err
# mysql錯誤日誌存放路徑及名稱(啟動出現錯誤一定要看錯誤日誌,百分之百都能通過錯誤日誌排插解決。)
pid-file=/data/3306/mysql.pid
# MySQL_pid檔案記錄的是當前mysqld程式的pid,pid亦即ProcessID。
skip-locking
# 避免MySQL的外部鎖定,減少出錯機率,增強穩定性。
skip-name-resolv
# 禁止MySQL對外部連線進行DNS解析,使用這一選項可以消除MySQL進行DNS解析的時候。但是需要注意的是,如果開啟該選項,則所有遠端主機連線授權都要使用IP地址方式了,否則MySQL將無法正常處理連線請求!
skip-networking
# 開啟該選項可以徹底關閉MySQL的TCP/IP連線方式,如果Web伺服器是以遠端連線的方式訪問MySQL資料庫伺服器的,則不要開啟該選項,否則無法正常連線!
open_files_limit = 1024
# MySQLd能開啟檔案的最大個數,如果出現too mant open files之類的就需要調整該值了。
back_log = 384
# back_log引數是值指出在MySQL暫時停止響應新請求之前,短時間內的多少個請求可以被存在堆疊中。如果系統在短時間內有很多連線,則需要增加該引數的值,該引數值指定到來的TCP/IP連線的監聽佇列的大小。不同的作業系統在這個佇列的大小上有自己的限制。如果試圖將back_log設定得高於作業系統的限制將是無效的,其預設值為50.對於Linux系統而言,推薦設定為小於512的整數。
max_connections = 800
# 指定MySQL允許的最大連線程式數。如果在訪問部落格時經常出現 Too Many Connections的錯誤提示,則需要增大該引數值。
max_connect_errors = 6000
# 設定每個主機的連線請求異常中斷的最大次數,當超過該次數,MySQL伺服器將禁止host的連線請求,直到MySQL伺服器重啟或通過flush hosts命令清空此host的相關資訊。
wait_timeout = 120
# 指定一個請求的最大連線時間,對於4GB左右記憶體的伺服器來說,可以將其設定為5~10。
table_cache = 614K
# table_cache指示表高速緩衝區的大小。當MySQL訪問一個表時,如果在MySQL緩衝區還有空間,那麼這個表就被開啟並放入表緩衝區,這樣做的好處是可以更快速地訪問表中的內容。一般來說,可以檢視資料庫執行峰值時間的狀態值Open_tables和Open_tables,用以判斷是否需要增加table_cache的值,即如果Open_tables接近table_cache的時候,並且Opened_tables這個值在逐步增加,那就要考慮增加這個值的大小了。
external-locking = FALSE
# MySQL選項可以避免外部鎖定。True為開啟。
max_allowed_packet =16M
# 伺服器一次能處理最大的查詢包的值,也是伺服器程式能夠處理的最大查詢
sort_buffer_size = 1M
# 設定查詢排序時所能使用的緩衝區大小,系統預設大小為2MB。
# 注意:該引數對應的分配記憶體是每個連線獨佔的,如果有100個連線,那麼實際分配的總排序緩衝區大小為100 x6=600MB。所以,對於記憶體在4GB左右的伺服器來說,推薦將其設定為6MB~8MB
join_buffer_size = 8M
# 聯合查詢操作所能使用的緩衝區大小,和sort_buffer_size一樣,該引數對應的分配記憶體也是每個連線獨享。
thread_cache_size = 64
# 設定Thread Cache池中可以快取的連線執行緒最大數量,可設定為0~16384,預設為0.這個值表示可以重新利用儲存在快取中執行緒的數量,當斷開連線時如果快取中還有空間,那麼客戶端的執行緒將被放到快取中;如果執行緒重新被請求,那麼請求將從快取中讀取,如果快取中是空的或者是新的請求,那麼這個執行緒將被重新建立,如果有很多執行緒,增加這個值可以改善系統效能。通過比較Connections和Threads_created狀態的變數,可以看到這個變數的作用。我們可以根據實體記憶體設定規則如下:1GB記憶體我們配置為8,2GB記憶體我們配置為16,3GB我們配置為32,4GB或4GB以上我們給此值為64或更大的值。
thread_concurrency = 8
# 該引數取值為伺服器邏輯CPU數量x 2,在本例中,伺服器有兩個物理CPU,而每個物理CPU又支援H.T超執行緒,所以實際取值為4 x 2 = 8。這也是雙四核主流伺服器的配置。
query_cache_size = 64M
# 指定MySQL查詢緩衝區的大小。可以通過在MySQL控制檯觀察,如果Qcache_lowmem_prunes的值非常大,則表明經常出現緩衝不夠的情況;如果Qcache_hits的值非常大,則表明查詢緩衝使用得非常頻繁。另外如果改值較小反而會影響效率,那麼可以考慮不用查詢緩衝。對於Qcache_free_blocks,如果該值非常大,則表明緩衝區中碎片很多。
query_cache_limit = 2M
# 只有小於此設定值的結果才會被快取
query_cache_min_res_unit = 2k
# 設定查詢快取分配記憶體的最小單位,要適當第設定此引數,可以做到為減少記憶體快的申請和分配次數,但是設定過大可能導致記憶體碎片數值上升。預設值為4K,建議設定為1K~16K。
default_table_type = InnoDB
# 預設表的型別為InnoDB
thread_stack = 256K
# 設定MySQL每個執行緒的堆疊大小,預設值足夠大,可滿足普通操作。可設定範圍為128KB至4GB,預設為192KB
#transaction_isolation = Level
# 資料庫隔離級別 (READ UNCOMMITTED(讀取未提交內容) READ COMMITTED(讀取提交內容) REPEATABLE
READ(可重讀) SERIALIZABLE(可序列化))
tmp_table_size = 64M
# 設定記憶體臨時表最大值。如果超過該值,則會將臨時表寫入磁碟,其範圍1KB到4GB。
max_heap_table_size = 64M
# 獨立的記憶體表所允許的最大容量。
table_cache = 614
# 給經常訪問的表分配的記憶體,實體記憶體越大,設定就越大。調大這個值,一般情況下可以降低磁碟IO,但相應的會佔用更多的記憶體,這裡設定為614。
table_open_cache = 512
# 設定表快取記憶體的數目。每個連線進來,都會至少開啟一個表快取。因此, table_cache 的大小應與 max_connections 的設定有關。例如,對於 200 個並行執行的連線,應該讓表的快取至少有 200 × N ,這裡 N 是應用可以執行的查詢的一個聯接中表的最大數量。此外,還需要為臨時表和檔案保留一些額外的檔案描述符。
long_query_time = 1
# 慢查詢的執行用時上限,預設設定是10s,推薦(1s~2s)
log_long_format
# 沒有使用索引的查詢也會被記錄。(推薦,根據業務來調整)
log-slow-queries = /data/3306/slow.log
# 慢查詢日誌檔案路徑(如果開啟慢查詢,建議開啟此日誌)
log-bin = /data/3306/mysql-bin
# logbin資料庫的操作日誌,例如update、delete、create等都會儲存到binlog日誌,通過logbin可以實現增量恢復
relay-log = /data/3306/relay-bin
# relay-log日誌記錄的是從伺服器I/O執行緒將主伺服器的二進位制日誌讀取過來記錄到從伺服器本地檔案,然後SQL執行緒會讀取relay-log日誌的內容並應用到從伺服器
relay-log-info-file = /data/3306/relay-log.info
# 從伺服器用於記錄中繼日誌相關資訊的檔案,預設名為資料目錄中的relay-log.info。
binlog_cache_size = 4M
# 在一個事務中binlog為了記錄sql狀態所持有的cache大小,如果你經常使用大的,多宣告的事務,可以增加此值來獲取更大的效能,所有從事務來的狀態都被緩衝在binlog緩衝中,然後再提交後一次性寫入到binlog中,如果事務比此值大,會使用磁碟上的臨時檔案來替代,此緩衝在每個連結的事務第一次更新狀態時被建立。
max_binlog_cache_size = 8M
# 最大的二進位制Cache日誌緩衝尺寸。
max_binlog_size = 1G
# 二進位制日誌檔案的最大長度(預設設定1GB)一個二進位制檔案資訊超過了這個最大長度之前,MySQL伺服器會自動提供一個新的二進位制日誌檔案接續上。
expire_logs_days = 7
# 超過7天的binlog,mysql程式自動刪除(如果資料重要,建議不要開啟該選項)
key_buffer_size = 256M
# 指定用於索引的緩衝區大小,增加它可得到更好的索引處理效能。對於記憶體在4GB左右的伺服器來說,該引數可設定為256MB或384MB。
# 注意:如果該引數值設定得過大反而會使伺服器的整體效率降低!
read_buffer_size = 4M
# 讀查詢操作所能使用的緩衝區大小。和sort_buffer_size一樣,該引數對應的分配記憶體也是每個連線獨享。
read_rnd_buffer_size = 16M
# 設定進行隨機讀的時候所使用的緩衝區。此引數和read_buffer_size所設定的Buffer相反,一個是順序讀的時候使用,一個是隨機讀的時候使用。但是兩者都是針對與執行緒的設定,每個執行緒都可以產生兩種Buffer中的任何一個。預設值256KB,最大值4GB。
bulk_insert_buffer_size = 8M
# 如果經常性的需要使用批量插入的特殊語句來插入資料,可以適當調整引數至16MB~32MB,建議8MB。
myisam_sort_buffer_size = 8M
# 設定在REPAIR Table或用Create index建立索引或 Alter table的過程中排序索引所分配的緩衝區大小,可設定範圍4Bytes至4GB,預設為8MB
lower_case_table_names = 1
# 實現MySQL不區分大小。(發開需求-建議開啟)
slave-skip-errors = 1032,1062
# 從庫可以跳過的錯誤數字值(mysql錯誤以數字程式碼反饋,全的mysql錯誤程式碼大全,以後會發布至部落格)。
replicate-ignore-db=mysql
# 在做主從的情況下,設定不需要同步的庫。
server-id = 1
# 表示本機的序列號為1,如果做主從,或者多例項,serverid一定不能相同。
myisam_sort_buffer_size = 128M
# 當需要對於執行REPAIR, OPTIMIZE, ALTER 語句重建索引時,MySQL會分配這個快取,以及LOAD DATA INFILE會載入到一個新表,它會根據最大的配置認真的分配的每個執行緒。
myisam_max_sort_file_size = 10G
# 當重新建索引(REPAIR,ALTER,TABLE,或者LOAD,DATA,TNFILE)時,MySQL被允許使用臨時檔案的最大值。
myisam_repair_threads = 1
# 如果一個表擁有超過一個索引, MyISAM 可以通過並行排序使用超過一個執行緒去修復他們.
myisam_recover
# 自動檢查和修復沒有適當關閉的 MyISAM 表.
innodb_additional_mem_pool_size = 4M
# 用來設定InnoDB儲存的資料目錄資訊和其他內部資料結構的記憶體池大小。應用程式裡的表越多,你需要在這裡面分配越多的記憶體。對於一個相對穩定的應用,這個引數的大小也是相對穩定的,也沒有必要預留非常大的值。如果InnoDB用廣了這個池內的記憶體,InnoDB開始從作業系統分配記憶體,並且往MySQL錯誤日誌寫警告資訊。預設為1MB,當發現錯誤日誌中已經有相關的警告資訊時,就應該適當的增加該引數的大小。
innodb_buffer_pool_size = 64M
# InnoDB使用一個緩衝池來儲存索引和原始資料,設定越大,在存取表裡面資料時所需要的磁碟I/O越少。強烈建議不要武斷地將InnoDB的Buffer Pool值配置為實體記憶體的50%~80%,應根據具體環境而定。
innodb_data_file_path = ibdata1:128M:autoextend
# 設定配置一個可擴充套件大小的尺寸為128MB的單獨檔案,名為ibdata1.沒有給出檔案的位置,所以預設的是在MySQL的資料目錄內。
innodb_file_io_threads = 4
# InnoDB中的檔案I/O執行緒。通常設定為4,如果是windows可以設定更大的值以提高磁碟I/O
innodb_thread_concurrency = 8
# 你的伺服器有幾個CPU就設定為幾,建議用預設設定,一般設為8。
innodb_flush_log_at_trx_commit = 1
# 設定為0就等於innodb_log_buffer_size佇列滿後在統一儲存,預設為1,也是最安全的設定。
innodb_log_buffer_size = 2M
# 預設為1MB,通常設定為8~16MB就足夠了。
innodb_log_file_size = 32M
# 確定日誌檔案的大小,更大的設定可以提高效能,但也會增加恢復資料庫的時間。
innodb_log_files_in_group = 3
# 為提高效能,MySQL可以以迴圈方式將日誌檔案寫到多個檔案。推薦設定為3。
innodb_max_dirty_pages_pct = 90
# InnoDB主執行緒重新整理快取池中的資料。
innodb_lock_wait_timeout = 120
# InnoDB事務被回滾之前可以等待一個鎖定的超時秒數。InnoDB在它自己的鎖定表中自動檢測事務死鎖並且回滾事務。InnoDB用locak tables 語句注意到鎖定設定。預設值是50秒。
innodb_file_per_table = 0
# InnoDB為獨立表空間模式,每個資料庫的每個表都會生成一個資料空間。0關閉,1開啟。
# 獨立表空間優點:
# 1、每個表都有自己獨立的表空間。
# 2 、每個表的資料和索引都會存在自己的表空間中。
# 3、可以實現單表在不同的資料庫中移動。
# 4、空間可以回收(除drop table操作處,表空不能自己回收。)
[mysqldump]
quick
max_allowed_packet = 2M
# 設定在網路傳輸中一次訊息傳輸量的最大值。系統預設值為1MB,最大值是1GB,必須設定為1024的倍數。單位為位元組。
一些建議:
強烈建議不要武斷地將InnoDB的Buffer Pool值配置為實體記憶體的50%~80%,應根據具體環境而定。
如果key_reads太大,則應該把my.cnf中的key_buffer_size變大,保持key_reads/key_read_re-quests至少在1/100以上,越小越好。
如果qcache_lowmem_prunes很大,就要增加query_cache_size的值。
不過很多時候需要具體情況具體分析,其他引數的變更我們可以等MySQL上線穩定一段時間後在根據status值進行調整。
配置範例
一份電子商務網站MySQL資料庫調整後所執行的配置檔案/etc/my.cnf(伺服器為DELL R710、16GB記憶體、RAID10),大家可以根據實際的MySQL資料庫硬體情況進行調整配置檔案如下:
[client]
port = 3306
socket = /data/3306/mysql.sock
default-character-set = utf8
[mysqld]
user = mysql
port = 3306
character-set-server = utf8
socket = /data/3306/mysql.sock
basedir = /application/mysql
datadir = /data/3306/data
log-error=/data/3306/mysql_err.log
pid-file=/data/3306/mysql.pid
log_slave_updates = 1
log-bin = /data/3306/mysql-bin
binlog_format = mixed
binlog_cache_size = 4M
max_binlog_cache_size = 8M
max_binlog_size = 1G
expire_logs_days = 90
binlog-ignore - db = mysql
binlog-ignore - db = information_schema
key_buffer_size = 384M
sort_buffer_size = 2M
read_buffer_size = 2M
read_rnd_buffer_size = 16M
join_buffer_size = 2M
thread_cache_size = 8
query_cache_size = 32M
query_cache_limit = 2M
query_cache_min_res_unit = 2k
thread_concurrency = 32
table_cache = 614
table_open_cache = 512
open_files_limit = 10240
back_log = 600
max_connections = 5000
max_connect_errors = 6000
external-locking = FALSE
max_allowed_packet =16M
thread_stack = 192K
transaction_isolation = READ-COMMITTED
tmp_table_size = 256M
max_heap_table_size = 512M
bulk_insert_buffer_size = 64M
myisam_sort_buffer_size = 64M
myisam_max_sort_file_size = 10G
myisam_repair_threads = 1
myisam_recover
long_query_time = 2
slow_query_log
slow_query_log_file = /data/3306/slow.log
skip-name-resolv
skip-locking
skip-networking
server-id = 1
innodb_additional_mem_pool_size = 16M
innodb_buffer_pool_size = 512M
innodb_data_file_path = ibdata1:256M:autoextend
innodb_file_io_threads = 4
innodb_thread_concurrency = 8
innodb_flush_log_at_trx_commit = 2
innodb_log_buffer_size = 16M
innodb_log_file_size = 128M
innodb_log_files_in_group = 3
innodb_max_dirty_pages_pct = 90
innodb_lock_wait_timeout = 120
innodb_file_per_table = 0
[mysqldump]
quick
max_allowed_packet = 64M
[mysql]
no – auto - rehash
四:儲存引擎的選擇
關於儲存引擎的選擇請看部落格:MySQL儲存引擎之Myisam和Innodb總結性梳理
五:線上優化調整
MySQL資料庫上線後,可以等其穩定執行一段時間後再根據伺服器的status狀態進行適當優化,我們可以用如下命令列出MySQL伺服器執行的各種狀態值。通過命令:show global status; 也可以通過 show status like '查詢%';
1、慢查詢
有時我們為了定位系統中效率比較低下的Query語法,需要開啟慢查詢日誌,也就是Slow Query log。開啟慢查詢日誌的相關命令如下:
mysql>show variables like '%slow%';
+---------------------+-----------------------------------------+
|
Variable_name | Value |
+---------------------+-----------------------------------------+
|
log_slow_queries | ON |
|
slow_launch_time | 2 |
+---------------------+-----------------------------------------+
mysql>show global status like '%slow%';
+---------------------+-------+
|
Variable_name | Value |
+---------------------+-------+
|
Slow_launch_threads | 0 |
|
Slow_queries | 2128 |
+---------------------+-------+
開啟慢查詢日誌可能會對系統效能有一點點影響,如果你的MySQL是主從結構,可以考慮開啟其中一臺從伺服器的慢查詢日誌,這樣既可以監控慢查詢,對系統效能影響也會很小。另外,可以用MySQL自帶的命令mysqldumpslow進行查詢。比如:下面的命令可以查出訪問次數最多的20個SQL語句:
mysqldumpslow -s c -t 20 host-slow.log
2、連線數
我們如果經常遇見MySQL:ERROR1040:Too many connections的情況,一種情況是訪問量確實很高,MySQL伺服器扛不住了,這個時候就要考慮增加從伺服器分散讀壓力,從架構層面。另外一種情況是MySQL配置檔案中max_connections的值過小。來看一個例子。
mysql> show variables like 'max_connections';
+-----------------+-------+
|
Variable_name | Value |
+-----------------+-------+
|
max_connections | 800 |
+-----------------+-------+
#### 這臺伺服器最大連線數是256,然後查詢一下該伺服器響應的最大連線數;
mysql> show global status like 'Max_used_connections';
+----------------------+-------+
|
Variable_name | Value |
+----------------------+-------+
|
Max_used_connections | 245 |
+----------------------+-------+
#### MySQL伺服器過去的最大連線數是245,沒有達到伺服器連線數的上線800,不會出現1040錯誤。
#### Max_used_connections /max_connections * 100% = 85%
#### 最大連線數占上限連線數的85%左右,如果發現比例在10%以下,則說明MySQL伺服器連線數的上限設定得過高了。
3.key_buffer_size
key_buffer_size是設定MyISAM表索引快取空間的大小,此引數對MyISAM表效能影響最大。下面是一臺MyISAM為主要儲存引擎伺服器的配置:
mysql> show variables like 'key_buffer_size';
+-----------------+-----------+
|
Variable_name | Value |
+-----------------+-----------+
|
key_buffer_size | 536870912 |
+-----------------+-----------+
#### 從上面可以看出,分配了512MB記憶體給key_buffer_size。再來看key_buffer_size的使用情況:
mysql> show global status like 'key_read%';
+-------------------+--------------+
|
Variable_name | Value |
+-------------------+-------+
|
Key_read_requests | 27813678766 |
|
Key_reads | 6798830|
+-------------------+--------------+
一共有27813678766個索引讀取請求,有6798830個請求在記憶體中沒有找到,直接從硬碟讀取索引。
key_cache_miss_rate = key_reads / key_read_requests * 100%
比如上面的資料,key_cache_miss_rate為0.0244%,4000%個索引讀取請求才有一個直接讀硬碟,效果已經很好了,key_cache_miss_rate在0.1%以下都很好,如果key_cache_miss_rate在0.01%以下的話,則說明key_buffer_size分配得過多,可以適當減少。
4.臨時表
當執行語句時,關於已經被建立了隱含臨時表的數量,我們可以用如下命令查詢其具體情況:
mysql> show global status like 'created_tmp%';
+-------------------------+----------+
|
Variable_name | Value |
+-------------------------+----------+
|
Created_tmp_disk_tables | 21119 |
|
Created_tmp_files | 6 |
|
Created_tmp_tables | 17715532 |
+-------------------------+----------+
#### MySQL伺服器對臨時表的配置:
mysql> show variables where Variable_name in ('tmp_table_size','max_heap_table_size');
+---------------------+---------+
|
Variable_name | Value |
+---------------------+---------+
|
max_heap_table_size | 2097152 |
|
tmp_table_size | 2097152 |
+---------------------+---------+
每次建立臨時表時,Created_tmp_table都會增加,如果磁碟上建立臨時表,Created_tmp_disk_tables也會增加。Created_tmp_files表示MySQL服務建立的臨時檔案數,比較理想的配置是:
Created_tmp_disk_tables / Created_tmp_files *100% <= 25%
比如上面的伺服器:
Created_tmp_disk_tables / Created_tmp_files *100% =1.20%,這個值就很棒了。
5.開啟表的情況
Open_tables表示開啟表的數量,Opened_tables表示開啟過的表數量,我們可以用如下命令檢視其具體情況:
mysql> show global status like 'open%tables%';
+---------------+-------+
|
Variable_name | Value |
+---------------+-------+
|
Open_tables | 351 |
|
Opened_tables | 1455 |
#### 查詢下伺服器table_open_cache;
mysql> show variables like 'table_open_cache';
+------------------+-------+
|
Variable_name | Value |
+------------------+-------+
|
table_open_cache | 2048 |
+------------------+-------+
如果Opened_tables數量過大,說明配置中table_open_cache的值可能太小。
比較合適的值為:
open_tables / opened_tables* 100% > = 85%
open_tables / table_open_cache* 100% < = 95%
6.程式使用情況
如果我們在MySQL伺服器的配置檔案中設定了thread_cache_size,當客戶端斷開時,伺服器處理此客戶請求的執行緒將會快取起來以響應一下客戶而不是銷燬(前提是快取數未達上線)Thread_created表示建立過的執行緒數,我們可以用如下命令檢視:
mysql> show global status like 'thread%';
+-------------------+-------+
|
Variable_name | Value |
+-------------------+-------+
|
Threads_cached | 40|
|
Threads_connected | 1 |
|
Threads_created | 330 |
|
Threads_running | 1 |
+-------------------+-------+
#### 查詢伺服器thread_cache_size配置如下:
mysql> show variables like 'thread_cache_size';
+-------------------+-------+
|
Variable_name | Value |
+-------------------+-------+
|
thread_cache_size | 100 |
+-------------------+-------+
如果發現Threads_created的值過大的話,表明MySQL伺服器一直在建立執行緒,這也是比較耗費資源的,可以適當增大配置檔案中thread_cache_size的值。
7.查詢快取(query cache)
它主要涉及兩個引數,query_cache_size是設定MySQL的Query Cache大小,query_cache_type是設定使用查詢快取的型別,我們可以用如下命令檢視其具體情況:
mysql> show global status like 'qcache%';
+-------------------------+-----------+
|
Variable_name | Value |
+-------------------------+-----------+
|
Qcache_free_blocks | 22756 |
|
Qcache_free_memory | 76764704 |
|
Qcache_hits | 213028692 |
|
Qcache_inserts | 208894227 |
|
Qcache_lowmem_prunes | 4010916 |
|
Qcache_not_cached | 13385031 |
|
Qcache_queries_in_cache | 43560 |
|
Qcache_total_blocks | 111212 |
+-------------------------+-----------+
MySQL查詢快取變數的相關解釋如下:
Qcache_free_blocks: 快取中相領記憶體快的個數。數目大說明可能有碎片。flush query cache會對快取中的碎片進行整理,從而得到一個空間塊。
Qcache_free_memory:快取中的空閒空間。
Qcache_hits:多少次命中。通過這個引數可以檢視到Query Cache的基本效果。
Qcache_inserts:插入次數,沒插入一次查詢時就增加1。命中次數除以插入次數就是命中比率。
Qcache_lowmem_prunes:多少條Query因為記憶體不足而被清楚出Query Cache。通過Qcache_lowmem_prunes和Query_free_memory相互結合,能 夠更清楚地瞭解到系統中Query Cache的記憶體大小是否真的足夠,是否非常頻繁地出現因為記憶體不足而有Query被換出的情況。
Qcache_not_cached:不適合進行快取的查詢數量,通常是由於這些查詢不是select語句或用了now()之類的函式。
Qcache_queries_in_cache:當前快取的查詢和響應數量。
Qcache_total_blocks:快取中塊的數量。
query_cache的配置命令:
mysql> show variables like 'query_cache%';
+------------------------------+---------+
|
Variable_name | Value |
+------------------------------+---------+
|
query_cache_limit | 1048576 |
|
query_cache_min_res_unit | 2048 |
|
query_cache_size | 2097152 |
|
query_cache_type | ON |
|
query_cache_wlock_invalidate | OFF |
+------------------------------+---------+
欄位解釋如下:
query_cache_limit:超過此大小的查詢將不快取。
query_cache_min_res_unit:快取塊的最小值。
query_cache_size:查詢快取大小。
query_cache_type:快取型別,決定快取什麼樣的查詢,示例中表示不快取select sql_no_cache查詢。
query_cache_wlock_invalidat:表示當有其他客戶端正在對MyISAM表進行寫操作,讀請求是要等WRITE LOCK釋放資源後再查詢還是允許直接從Query Cache中讀取結果,預設為OFF(可以直接從Query Cache中取得結果。)
query_cache_min_res_unit的配置是一柄雙刃劍,預設是4KB,設定值大對大資料查詢有好處,但如果你的查詢都是小資料查詢,就容易造成記憶體碎片和浪費。
查詢快取碎片率 = Qcache_free_blocks /Qcache_total_blocks * 100%
如果查詢碎片率超過20%,可以用 flush query cache 整理快取碎片,或者試試減少query_cache_min_res_unit,如果你查詢都是小資料庫的話。
查詢快取利用率 = (Qcache_free_size – Qcache_free_memory)/query_cache_size * 100%
查詢快取利用率在25%一下的話說明query_cache_size設定得過大,可適當減少;查詢快取利用率在80%以上而且Qcache_lowmem_prunes > 50的話則說明query_cache_size可能有點小,不然就是碎片太多。
查詢命中率 = (Qcache_hits - Qcache_insert)/Qcache)hits * 100%
示例伺服器中的查詢快取碎片率等於20%左右,查詢快取利用率在50%,查詢命中率在2%,說明命中率很差,可能寫操作比較頻繁,而且可能有些碎片。
8.排序使用情況
它表示系統中對資料進行排序時所用的Buffer,我們可以用如下命令檢視:
mysql> show global status like 'sort%';
+-------------------+----------+
|
Variable_name | Value |
+-------------------+----------+
|
Sort_merge_passes | 10 |
|
Sort_range | 37431240 |
|
Sort_rows | 6738691532 |
|
Sort_scan | 1823485 |
+-------------------+----------+
Sort_merge_passes包括如下步驟:MySQL首先會嘗試在記憶體中做排序,使用的記憶體大小由系統變數sort_buffer_size來決定,如果它不夠大則把所有的記錄都讀在記憶體中,而MySQL則會把每次在記憶體中排序的結果存到臨時檔案中,等MySQL找到所有記錄之後,再把臨時檔案中的記錄做一次排序。這次再排序就會增加sort_merge_passes。實際上,MySQL會用另外一個臨時檔案來儲存再次排序的結果,所以我們通常會看sort_merge_passes增加的數值是建臨時檔案數的兩倍。因為用到了臨時檔案,所以速度可能會比較慢,增大sort_buffer_size會減少sort_merge_passes和建立臨時檔案的次數,但盲目地增大sort_buffer_size並不一定能提高速度。
9.檔案開啟數(open_files)
我們現在處理MySQL故障時,發現當Open_files大於open_files_limit值時,MySQL資料庫就會發生卡住的現象,導致Nginx伺服器打不開相應頁面。這個問題大家在工作中應注意,我們可以用如下命令檢視其具體情況:
show global status like 'open_files';
+---------------+-------+
|
Variable_name | Value |
+---------------+-------+
|
Open_files | 1481 |
+---------------+-------+
mysql> show global status like 'open_files_limit';
+------------------+-------+
|
Variable_name | Value |
+------------------+--------+
|
Open_files_limit | 4509 |
+------------------+--------+
比較合適的設定是:Open_files / Open_files_limit * 100% < = 75%
10.InnoDB_buffer_pool_cache合理設定
InnoDB儲存引擎的快取機制和MyISAM的最大區別就在於,InnoDB不僅僅快取索引,同時還會快取實際的資料。此引數用來設定InnoDB最主要的Buffer的大小,也就是快取使用者表及索引資料的最主要快取空間,對InnoDB整體效能影響也最大。
無論是MySQL官方手冊還是網路上許多人分享的InnoDB優化建議,都是簡單地建議將此值設定為整個系統實體記憶體的50%~80%。這種做法其實不妥,我們應根據實際的執行場景來正確設定此項引數。
很多時候我們會發現,通過引數設定進行效能優化所帶來的效能提升,並不如許多人想象的那樣會產生質的飛躍,除非是之前的設定存在嚴重不合理的情況。我們不能將效能調優完全依託與通過DBA在資料庫上線後進行引數調整,而應該在系統設計和開發階段就儘可能減少效能問題。(重點在於前期架構合理的設計及開發的程式合理)
六:MySQL資料庫的可擴充套件架構方案(即高可用方案) 可參考:mysql高可用方案總結性說明
如果憑藉MySQL的優化任無法頂住壓力,這個時候我們就必須考慮MySQL的可擴充套件性架構了(有人稱為MySQL叢集)它有以下明顯的優勢:
1)成本低,很容易通過價格低廉Pc server搭建出一個處理能力非常強大的計算機叢集。
2)不太容易遇到瓶頸,因為很容易通過新增主機來增加處理能力。
3)單節點故障對系統的整體影響較小。
1、主從複製解決方案
這是MySQL自身提供的一種高可用解決方案,資料同步方法採用的是MySQL replication技術。MySQL replication就是從伺服器到主伺服器拉取二進位制日誌檔案,然後再將日誌檔案解析成相應的SQL在從伺服器上重新執行一遍主伺服器的操作,通過這種方式保證資料的一致性。
為了達到更高的可用性,在實際的應用環境中,一般都是採用MySQL replication技術配合高可用叢集軟體keepalived來實現自動failover,這種方式可以實現95.000%的SLA。
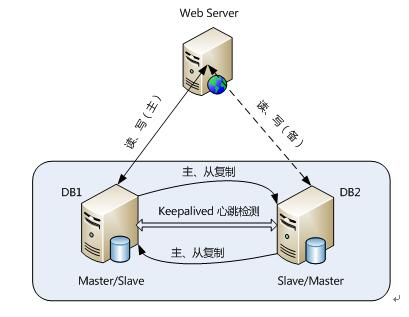
在實際應用場景中,MySQL Replication是使用最為廣泛的一種提高系統擴充套件性的設計手段。眾多的MySQL使用者通過Replication功能提升系統的擴充套件性後,通過 簡單的增加價格低廉的硬體裝置成倍 甚至成數量級地提高了原有系統的效能,是廣大MySQL中低端使用者非常喜歡的功能之一,也是許多MySQL使用者選擇MySQL最為重要的原因。
比較常規的MySQL Replication架構也有好幾種,這裡分別簡單說明下:
MySQL Replication架構一:常規復制架構–Master-slaves
是由一個Master複製到一個或多個Salve的架構模式,主要用於讀壓力大的應用資料庫端廉價擴充套件解決方案,讀寫分離,Master主要負責寫方面的壓力。
MySQL Replication架構二:級聯複製架構
即Master-Slaves-Slaves,這個也是為了防止Slaves的讀壓力過大,而配置一層二級 Slaves,很容易解決Master端因為附屬slave太多而成為瓶勁的風險。
MySQL Replication架構三:Dual Master與級聯複製結合架構
即Master-Master-Slaves,最大的好處是既可以避免主Master的寫操作受到Slave叢集的複製帶來的影響,而且保證了主Master的單點故障。
MySQL Replication的不足:
如果Master主機硬體故障無法恢復,則可能造成部分未傳送到slave端的資料丟失。所以大家應該根據自己目前的網路 規劃,選擇自己合理的Mysql架構方案,跟自己的MySQL DBA和程式設計師多溝湧,多備份(備份我至少會做到本地和異地雙備份),多測試,資料的事是最大的事,出不得半點差錯,切記切記
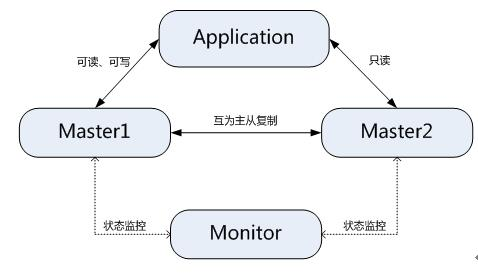
2、MMM/MHA高可用解決方案
MMM提供了MySQL主主複製配置的監控、故障轉移和管理的一套可伸縮的指令碼套件。在MMM高可用方案中,典型的應用是雙主多從架構,通過MySQL replication技術可以實現兩個伺服器互為主從,且在任何時候只有一個節點可以被寫入,避免了多點寫入的資料衝突。同時,當可寫的主節點故障時,MMM套件可以立刻監控到,然後將服務自動切換到另一個主節點,繼續提供服務,從而實現MySQL的高可用。
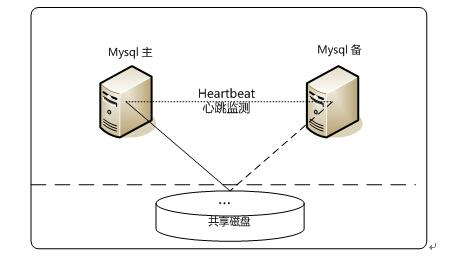
3、Heartbeat/SAN高可用解決方案
在這個方案中,處理failover的方式是高可用叢集軟體Heartbeat,它監控和管理各個節點間連線的網路,並監控叢集服務,當節點出現故障或者服務不可用時,自動在其他節點啟動叢集服務。在資料共享方面,通過SAN(Storage Area Network)儲存來共享資料,這種方案可以實現99.990%的SLA。
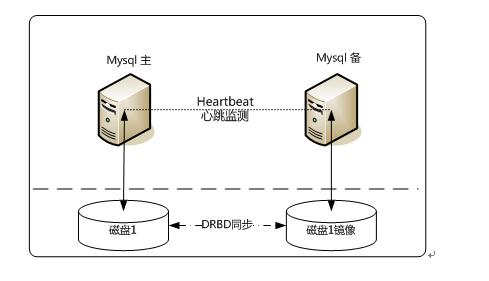
4、Heartbeat/DRBD高可用解決方案
此方案處理failover的方式上依舊採用Heartbeat,不同的是,在資料共享方面,採用了基於塊級別的資料同步軟體DRBD來實現。
DRBD是一個用軟體實現的、無共享的、伺服器之間映象塊裝置內容的儲存複製解決方案。和SAN網路不同,它並不共享儲存,而是通過伺服器之間的網路複製資料。
5、percona xtradb cluster
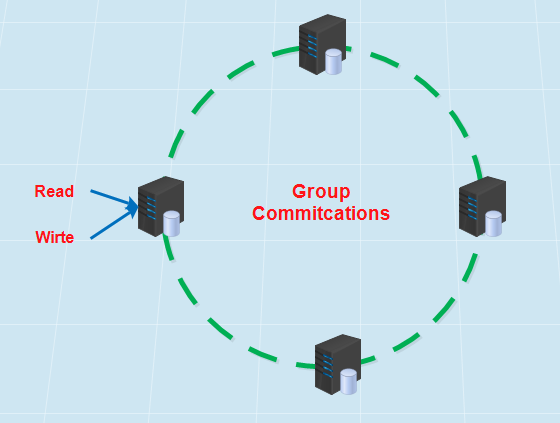
Percona XtraDB Cluster(簡稱PXC叢集)提供了MySQL高可用的一種實現方法。
1)叢集是有節點組成的,推薦配置至少3個節點,但是也可以執行在2個節點上。
2)每個節點都是普通的mysql/percona伺服器,可以將現有的資料庫伺服器組成叢集,反之,也可以將叢集拆分成單獨的伺服器。
3)每個節點都包含完整的資料副本。
PXC叢集主要由兩部分組成:Percona Server with XtraDB和Write Set Replication patches(使用了Galera library,一個通用的用於事務型應用的同步、多主複製外掛)。
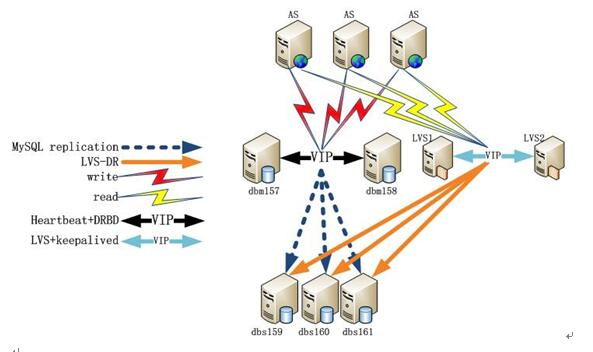
MYSQL經典應用架構