一、Memcache
Memcache是一套分散式的快取記憶體系統,由LiveJournal的Brad Fitzpatrick開發,但目前被許多網站使用以提升網站的訪問速度,尤其對於一些大型的、需要頻繁訪問資料庫的網站訪問速度提升效果十分顯著。
MemCache的工作流程如下:
先檢查客戶端請求資料是否在memcached中,如有,直接把請求資料返回,不再對資料庫進行任何操作;如果請求的資料不在memcached中,就去查資料庫,把從資料庫中獲取的資料返回給客戶端,同時把資料快取一份到memcached中(memcached客戶端不負責,需要程式明確實現);每次更新資料庫的同時更新memcached中的資料,保證一致性;當分配給memcached記憶體空間用完之後,會使用LRU(Least Recently Used,最近最少使用)策略加上到期失效策略,失效資料首先被替換,然後再替換掉最近未使用的資料。
Memcache是一個高效能的分散式的記憶體物件快取系統,通過在記憶體裡維護一個統一的巨大的hash表,它能夠用來儲存各種格式的資料,包括影象、視訊、檔案以及資料庫檢索的結果等。簡單的說就是將資料呼叫到記憶體中,然後從記憶體中讀取,從而大大提高讀取速度。
Memcached是以守護程式(監聽)方式執行於一個或多個伺服器中,隨時會接收客戶端的連線和操作,特性如下:
- 在Memcached中可以儲存的item資料量是沒有限制的,只要記憶體足夠 。
- Memcached單程式在32位系統中最大使用記憶體為2G,若在64位系統則沒有限制,這是由於32位系統限制單程式最多可使用2G記憶體,要使用更多記憶體,可以分多個埠開啟多個 Memcached程式 ,
- 最大30天的資料過期時間,設定為永久的也會在這個時間過期,常量REALTIME_MAXDELTA
- 60*60*24*30控制
- 最大鍵長為250位元組,大於該長度無法儲存,常量KEY_MAX_LENGTH 250控制
- 單個item最大資料是1MB,超過1MB資料不予儲存,常量POWER_BLOCK 1048576進行控制,
- 它是預設的slab大小
- 最大同時連線數是200,通過 conn_init()中的freetotal進行控制,最大軟連線數是1024,通過 settings.maxconns=1024 進行控制
- 跟空間佔用相關的引數:settings.factor=1.25, settings.chunk_size=48, 影響slab的資料佔用和步進方式
memcached是一種無阻塞的socket通訊方式服務,基於libevent庫,由於無阻塞通訊,對記憶體讀寫速度非常之快。
memcached分伺服器端和客戶端,可以配置多個伺服器端和客戶端,應用於分散式的服務非常廣泛。
memcached作為小規模的資料分散式平臺是十分有效果的。
memcached是鍵值一一對應,key預設最大不能超過128個字 節,value預設大小是1M,也就是一個slabs,如果要存2M的值(連續的),不能用兩個slabs,因為兩個slabs不是連續的,無法在記憶體中 儲存,故需要修改slabs的大小,多個key和value進行儲存時,即使這個slabs沒有利用完,那麼也不會存放別的資料。
memcached已經可以支援C/C++、Perl、PHP、Python、Ruby、Java、C#、Postgres、Chicken Scheme、Lua、MySQL和Protocol等語言客戶端。
Memcache的安裝
[root@linux-node1 ~]# yum install libevent-devel -y [root@linux-node1 ~]# yum install memcached -y
Memcache的 啟動
[root@linux-node1 ~]# memcached -d -m 10 -u root -l 192.168.56.11 -p 11211 -c 256 -P /tmp/memcached.pid [root@linux-node1 ~]# netstat -antlp|grep 11211 tcp 0 0 192.168.56.11:11211 0.0.0.0:* LISTEN 2251/memcached 引數說明 -d 是啟動一個守護程式 -m 是分配給Memcache使用的記憶體數量,單位是MB -u 是執行Memcache的使用者 -l 是監聽的伺服器IP地址 -p 是設定Memcache監聽的埠,最好是1024以上的埠 -c 選項是最大執行的併發連線數,預設是1024,按照你伺服器的負載量來設定 -P 是設定儲存Memcache的pid檔案
使用python操作Memcached
安裝API
[root@linux-node1 ~]# yum install -y python-memcached [root@linux-node1 ~]# python Python 2.7.5 (default, Jun 24 2015, 00:41:19) [GCC 4.8.3 20140911 (Red Hat 4.8.3-9)] on linux2 Type "help", "copyright", "credits" or "license" for more information. >>> import memcache >>> quit()
1)Memcache的第一次
[root@linux-node1 ~]# python
Python 2.7.5 (default, Jun 24 2015, 00:41:19)
[GCC 4.8.3 20140911 (Red Hat 4.8.3-9)] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import memcache
>>> mc =memcache.Client(['192.168.56.11:11211'],debug=True)
>>> mc.set("foo","bar")
True
>>> ret = mc.get('foo')
>>> print ret
溫馨提示:上面的debug=True;是表示執行出現錯誤的時候,顯示錯誤資訊,上線後,移除該引數。
2)Memcache和叢集是一對好基友
python-memcached模組原生支援叢集的操作,其原理是在記憶體維護一個主機列表
#!/usr/bin/env python
# coding:utf-8
import memcache
mc = memcache.Client([('192.168.56.11',1),('192.168.56.12',2)],debug=True)
# 主機列表:li = [192.168.56.11:11211,192.168.56.12:11211,192.168.56.13:11211,]
mc.set("foo","234")
# 1:將"foo"字串轉換成數字
# 2:將數字和主機列表長度求餘數
# 3:li[餘數],可以得到主機和IP
# 4:連線主機ip 將foo = 234 儲存到mem上
ret = mc.get('foo')
print ret
3)add
新增一條鍵值對,如果已經存在的key,重複執行add操作異常。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import memcache
mc = memcache.Client(['192.168.56.11:11211'],debug=True)
mc.add('k1','v1')
多次執行會報錯
[root@linux-node1 test]# python 1.py [root@linux-node1 test]# python 1.py MemCached: while expecting 'STORED', got unexpected response 'NOT_STORED'
4)replace
修改某個key的值,如果key值不存在,則異常
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import memcache
mc = memcache.Client(['192.168.56.11:11211'],debug=True)
# 如果存在k1,則替換成功;
mc.replace('k1','v1v1v1')
不存在則報錯
[root@linux-node1 test]# cat 2.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import memcache
mc = memcache.Client(['192.168.56.11:11211'],debug=True)
# 如果存在k1,則替換成功;
mc.replace('k1k1','v1v1v1')
[root@linux-node1 test]# python 2.py
MemCached: while expecting 'STORED', got unexpected response 'NOT_STORED'
5)set和set_multi
set 設定一個鍵值對,如果key不存在,則建立,如果key存在,則修改
set_multi 設定多個鍵值對,如果key不存在,則建立,如果key存在,則修改
[root@linux-node1 test]# cat 3.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import memcache
mc = memcache.Client(['192.168.56.11:11211'],debug=True)
mc.set('key1','ccccc')
# 一個鍵值對
mc.set_multi({'key2': 'ggggg','key3': 'tttt'})
[root@linux-node1 test]# python 3.py
6)delete和delete_multi
delete 在Memcached中刪除指定的一個鍵值對
delete_multi 在Memcached中刪除指定的多個鍵值對
[root@linux-node1 test]# cat 4.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import memcache
mc = memcache.Client(['192.168.56.11:11211'],debug=True)
mc.delete('key1')
# 一個鍵值對
mc.delete_multi(['key2','key3'])
[root@linux-node1 test]# python 4.py
7)get和get_multi
get 獲取一個鍵值對
get_multi 取多一個鍵值對
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import memcache
mc = memcache.Client(['192.168.56.11:11211], debug=True)
val = mc.get('key1')
item_dict = mc.get_multi(["key2", "key3"])
8)append和prepend
append 修改指定key的值,在該值 後面 追加內容
prepend 修改指定key的值,在該值 前面 插入內容
[root@linux-node1 test]# cat 5.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import memcache
mc = memcache.Client(['192.168.56.11:11211'],debug=True)
# 假設k1 = v1
mc.append('k1','after')
# 在v1的後面加after
mc.prepend('k1','before')
# 在v1的前面加before
9)decr和incr
incr 自增,將Memcached中的某一個值增加 N ( N預設為1 )
decr 自減,將Memcached中的某一個值減少 N ( N預設為1 )
#!/usr/bin/env python
# coding:utf-8
import memcache
mc = memcache.Client(['192.168.56.11',1],debug=True)
mc.set('k1','123')
# 預設變化的值為1
mc.incr('k1',10)
# k1的值會變成133
mc.decr('k1',23)
# k1的值會變成110
10)如果用終端,同時操作一組資料的話,會出現非正常資料,使用gets和cas來解決
#!/usr/bin/env python
# coding:utf-8
import memcache
mc = memcache.Client(['192.168.56.11',1],debug=True)
# 假設k1=1111
mc.gets('k1')
# 此時A使用者gets了資料。
# 進行了減法操作
# 來了B使用者,也對k1進行了操作,這時候,執行下面的操作就會報錯
mc.cas('product_count', "1110")
解析:
本質上每次執行gets時,會從memcache中獲取一個自增的數字,通過cas去修改gets的值時,會攜帶之前獲取的自增值和memcache中的自增值進行比較,如果相等,則可以提交,如果不想等,那表示在gets和cas執行之間,又有其他人執行了gets(獲取了緩衝的指定值), 如此一來有可能出現非正常資料,則不允許修改。
二、Redis
簡介:
Redis是一個key-value儲存系統。和Memcached類似,它支援儲存的value型別相對更多,包括string(字串)、list(連結串列)、set(集合)、zset(sorted set --有序集合)和hash(雜湊型別)。這些資料型別都支援push/pop、add/remove及取交集並集和差集及更豐富的操作,而且這些操作都是原子性的。在此基礎上,redis支援各種不同方式的排序。與memcached一樣,為了保證效率,資料都是快取在記憶體中。區別的是redis會週期性的把更新的資料寫入磁碟或者把修改操作寫入追加的記錄檔案,並且在此基礎上實現了master-slave(主從)同步。
Redis支援主從同步。資料可以從主伺服器向任意數量的從伺服器上同步,從伺服器可以是關聯其他從伺服器的主伺服器。這使得Redis可執行單層樹複製。存檔可以有意無意的對資料進行寫操作。由於完全實現了釋出/訂閱機制,使得從資料庫在任何地方同步樹時,可訂閱一個頻道並接收主伺服器完整的訊息釋出記錄。同步對讀取操作的可擴充套件性和資料冗餘很有幫助。
Redis與memcache的比較
Redis 是一個高效能的key-value資料庫。 redis的出現,很大程度補償了memcached這類key/value儲存的不足,在部 分場合可以對關聯式資料庫起到很好的補充作用。它提供了Java,C/C++,C#,PHP,JavaScript,Perl,Object-C,Python,Ruby,Erlang等客戶端,使用很方便。
資料模型:
Redis的外圍由一個鍵、值對映的字典構成。與其他非關係型資料庫主要不同在於:Redis中值的型別
不僅限於字串,還支援如下抽象資料型別:
- 字串列表
- 無序不重複的字串集合
- 有序不重複的字串集合
- 鍵、值都為字串的雜湊表
- 值的型別決定了值本身支援的操作。Redis支援不同無序、有序的列表,無序、有序的集合間的交集、並集等高階伺服器端原子操作。
資料結構:
redis提供五種資料型別:string,hash,list,set及zset(sorted set)。
儲存:
- redis使用了兩種檔案格式:全量資料和增量請求。
- 全量資料格式是把記憶體中的資料寫入磁碟,便於下次讀取檔案進行載入;
- 增量請求檔案則是把記憶體中的資料序列化為操作請求,用於讀取檔案進行replay得到資料,序列化的操作包括SET、RPUSH、SADD、ZADD。
- redis的儲存分為記憶體儲存、磁碟儲存和log檔案三部分,配置檔案中有三個引數對其進行配置。
- save seconds updates,save配置,指出在多長時間內,有多少次更新操作,就將資料同步到資料檔案。這個可以多個條件配合,比如預設配置檔案中的設定,就設定了三個條件。
- appendonly yes/no ,appendonly配置,指出是否在每次更新操作後進行日誌記錄,如果不開啟,可能會在斷電時導致一段時間內的資料丟失。因為redis本身同步資料檔案是按上面的save條件來同步的,所以有的資料會在一段時間內只存在於記憶體中。
- appendfsync no/always/everysec ,appendfsync配置,no表示等作業系統進行資料快取同步到磁碟,always表示每次更新操作後手動呼叫fsync()將資料寫到磁碟,everysec表示每秒同步一次。
安裝啟動:
直接yum安裝:
[root@linux-node1 ~]# yum -y install redis [root@linux-node1 ~]# systemctl start redis [root@linux-node1 ~]# ps -ef |grep redis redis 16359 1 0 16:55 ? 00:00:00 /usr/bin/redis-server 127.0.0.1:6379 root 16363 16335 0 16:56 pts/0 00:00:00 grep --color=auto redis
啟動客戶端:
[root@linux-node1 ~]# redis-cli 127.0.0.1:6379> set foo bar OK 127.0.0.1:6379> get foo "bar"
使用python操作redis
首先安裝元件:
[root@linux-node1 ~]# yum -y install python-pip [root@linux-node1 ~]# pip install redis
常用操作
1)操作模式
redis-py提供兩個類Redis和StictRedis用於實現Redis命令,StrictRedis用於實現大部分官方的功能,並使用官方的語法和命令,Redis是StricRedis的子類,用於向後相容舊版本的redis-py。
[root@linux-node1 test]# cat 6.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import redis
r = redis.Redis(host='127.0.0.1',port=6379)
r.set('foo','bar')
print r.get('foo')
[root@linux-node1 test]# python 6.py
bar
2)連線池
redis-py使用connection pool來管理對一個redis server的所有連線,避免每次建立、釋放連線的開銷。預設,每個Redis例項都會維護一個自己的連線池。可以直接建立一個連線池,然後作為引數Redis,這樣就可以實現多個Redis例項共享一個連線池。
[root@linux-node1 test]# cat 6.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import redis
pool = redis.ConnectionPool(host='127.0.0.1',port=6379)
r=redis.Redis(connection_pool=pool)
r.set('foo','bar')
print r.get('foo')
[root@linux-node1 test]# python 6.py
bar
3)管道
redis-py預設在執行每次請求都會建立(連線池申請連線)和斷開(歸還連線池)一次連線操作,如果想要在一次請求中指定多個命令,則可以使用pipline實現一次請求指定多個命令,並且預設情況下一次pipline 是原子性操作。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import redis
pool = redis.ConnectionPool(host='127.0.0.1',port=6379)
r=redis.Redis(connection_pool=pool)
#pipe = r.pipeline(transaction=False)
pipe = r.pipeline(transaction=True)
r.set('foo','bar')
r.set('foo111','bar111')
ret = pipe.execute()
4)釋出訂閱

頻道:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import redis
class RedisHelper:
def __init__(self):
self.__conn = redis.Redis(host='10.211.55.4')
self.chan_sub = 'fm104.5'
self.chan_pub = 'fm104.5'
def public(self, msg):
self.__conn.publish(self.chan_pub, msg)
return True
def subscribe(self):
pub = self.__conn.pubsub()
pub.subscribe(self.chan_sub)
pub.parse_response()
return pub
訂閱者
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from monitor.RedisHelper import RedisHelper
obj = RedisHelper()
redis_sub = obj.subscribe()
while True:
msg= redis_sub.parse_response()
print msg
釋出者
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from monitor.RedisHelper import RedisHelpe
obj = RedisHelper()
obj.public('hello')
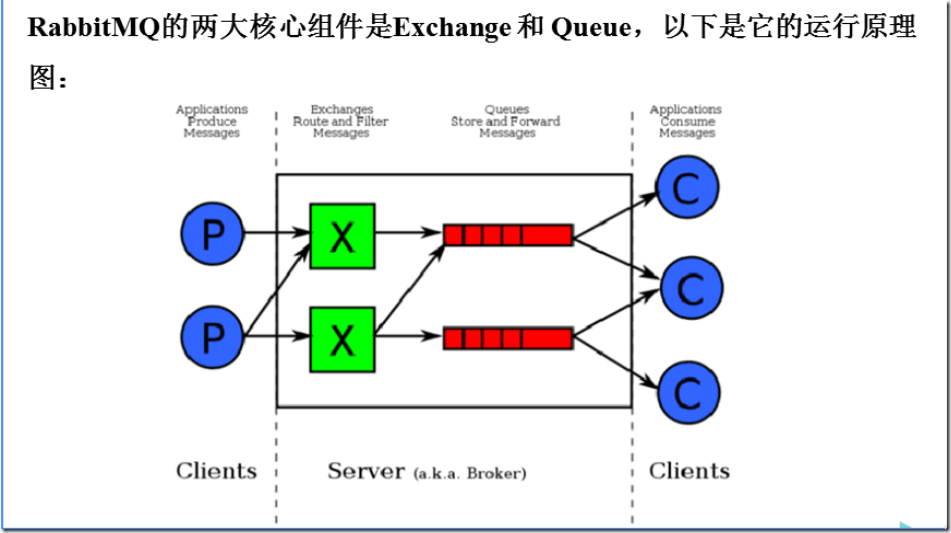
三、RabbitMQ
RabbitMQ是一個在AMQP基礎上完整的,可複用的企業訊息系統。他遵循Mozilla Public License開源協議。
MQ全稱為Message Queue, 訊息佇列(MQ)是一種應用程式對應用程式的通訊方法。應用程式通過讀寫出入佇列的訊息(針對應用程式的資料)來通訊,而無需專用連線來連結它們。消 息傳遞指的是程式之間通過在訊息中傳送資料進行通訊,而不是通過直接呼叫彼此來通訊,直接呼叫通常是用於諸如遠端過程呼叫的技術。排隊指的是應用程式通過 佇列來通訊。佇列的使用除去了接收和傳送應用程式同時執行的要求。
RabbitMQ的安裝
### 安裝配置epel源,如果你是centos7,請換epel源 $ rpm -ivh http://dl.fedoraproject.org/pub/epel/6/i386/epel-release-6-8.noarch.rpm ### 安裝erlang $ yum -y install erlang ### 安裝RabbitMQ $ yum -y install rabbitmq-server ### 啟動 [root@linux-node1 test]# /usr/sbin/rabbitmq-server start [root@linux-node1 test]# ps -ef |grep rabbitmq-server root 17096 16335 0 18:36 pts/0 00:00:00 /bin/sh /usr/sbin/rabbitmq-server start root 17105 17096 0 18:36 pts/0 00:00:00 su rabbitmq -s /bin/sh -c /usr/lib/rabbitmq/bin/rabbitmq-server "start" root 17181 16510 0 18:36 pts/3 00:00:00 grep --color=auto rabbitmq-server
安裝API
[root@linux-node1 test]# pip install pika
使用API操作RabbitMQ
基於Queue實現生產者消費者模型
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import Queue
import threading
message = Queue.Queue(10)
def producer(i):
while True:
message.put(i)
def consumer(i):
while True:
msg = message.get()
for i in range(12):
t = threading.Thread(target=producer, args=(i,))
t.start()
for i in range(10):
t = threading.Thread(target=consumer, args=(i,))
t.start()
對於RabbitMQ來說,生產和消費不再針對記憶體裡的一個Queue物件,而是某臺伺服器上的RabbitMQ Server實現的訊息佇列。
生產者:
#!/usr/bin/env python
# coding:utf-8
import pika
# 建立一個連線
connection = pika.BlockingConnection(pika.ConnectionParameters(host='127.0.0.1'))
# 開啟一個通道
channel = connection.channel()
# 佇列宣告叫hello
channel.queue_declare(queue='hello')
# 向佇列中插入資料,往hello對佇列中插入hello world
channel.basic_publish(exchange='',
routing_key='hello',
body='Hello World!')
print(" [x] Sent 'Hello World!'")
connection.close()
消費者:
#!/usr/bin/env python
# coding:utf-8
import pika
# 建立一個連線
connection = pika.BlockingConnection(pika.ConnectionParameters(host='127.0.0.1'))
# 開啟一個通道,建立頻道
channel = connection.channel()
# 佇列宣告叫hello
channel.queue_declare(queue='hello')
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
# 消費佇列中的內容,同時執行callback函式,callback函式中的body就是拿取到的內容
channel.basic_consume(callback,
queue='hello',
no_ack=True) # 出現斷開的情況,資料就會丟失;這種方式釋出者和聽眾是沒有相互應答的
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
1)acknowledgment 訊息不丟失(消費者失聯)
no-ack = False,如果生產者遇到情況(its channel is closed, connection is closed, or TCP connection is lost)掛掉了,那麼,RabbitMQ會重新將該任務新增到佇列中。在消費者中操作
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(host='127.0.0.1'))
channel = connection.channel()
channel.queue_declare(queue='hello')
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
import time
time.sleep(10)
print 'ok'
ch.basic_ack(delivery_tag = method.delivery_tag)
channel.basic_consume(callback,
queue='hello',
no_ack=False)
# 這裡使用False
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
2)durable訊息不丟失
如果是生產者掛掉了呢,你說你咋整?訊息佇列可以做持久化,哈哈哈
生產者
#!/usr/bin/env python
# coding:utf-8
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(host='127.0.0.1'))
channel = connection.channel()
# 宣告這個訊息佇列的時候就要使用durable來宣告持久化
channel.queue_declare(queue='hello', durable=True)
channel.basic_publish(exchange='',
routing_key='hello',
body='Hello World!',
properties=pika.BasicProperties(
delivery_mode=2, # make message persistent
)) # 指定訊息的時候,也是要持久化
print(" [x] Sent 'Hello World!'")
connection.close()
消費者
#!/usr/bin/env python
# coding:utf-8
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(host='127.0.0.1'))
channel = connection.channel()
# 這個可有可無
channel.queue_declare(queue='hello', durable=True)
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
import time
time.sleep(10)
print 'ok'
ch.basic_ack(delivery_tag = method.delivery_tag)
channel.basic_consume(callback,
queue='hello',
no_ack=False)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
已經存在的訊息佇列,無法進行持久化,只能重新生成佇列才行。
3)訊息獲取順序
預設訊息佇列裡的資料是按照順序被消費者拿走,例如:消費者1 去佇列中獲取 奇數 序列的任務,消費者1去佇列中獲取 偶數 序列的任務。
channel.basic_qos(prefetch_count=1) 表示誰來誰取,不再按照奇偶數排列。這個需要在消費者上來操作。
#!/usr/bin/env python
# coding:utf-8
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(host='127.0.0.1'))
channel = connection.channel()
channel.queue_declare(queue='hello')
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
import time
time.sleep(10)
print 'ok'
ch.basic_ack(delivery_tag = method.delivery_tag)
# 誰來誰取
channel.basic_qos(prefetch_count=1)
channel.basic_consume(callback,
queue='hello',
no_ack=False)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
4)釋出訂閱
釋出訂閱和簡單的訊息佇列區別在於,釋出訂閱會將訊息傳送給所有的訂閱者,而訊息佇列中的資料被消費一次便消失。所以,RabbitMQ實現釋出和訂閱時,會為每一個訂閱者建立一個佇列,而釋出者釋出訊息時,會將訊息放置在所有相關佇列中。
exchange type = fanout 表示可以給多個佇列發資料,可以理解為廣播
釋出者
#!/usr/bin/env python
# coding:utf-8
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
host=((‘
127.0.0.1
'))
channel = connection.channel()
channel.exchange_declare(exchange='logs', # logs隨便起名字
type='fanout') # 可以給多個佇列發資料
message = ' '.join(sys.argv[1:]) or "info: Hello World!"
channel.basic_publish(exchange='logs',
routing_key='',
body=message)
print(" [x] Sent %r" % message)
connection.close()
訂閱者一
#!/usr/bin/env python
# coding:utf-8
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='127.0.0.1'))
channel = connection.channel()
# 定義宣告,為logs
channel.exchange_declare(exchange='logs',
type='fanout')
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue
# 生成了一個隨機名稱
# 讓佇列和exchange進行繫結,以後生產者傳送來資料,exchange就會往queue中轉發資料
channel.queue_bind(exchange='logs',
queue=queue_name)
print(' [*] Waiting for logs. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] %r" % body)
# 一直去取資料
channel.basic_consume(callback,
queue=queue_name,
no_ack=True)
channel.start_consuming()
訂閱者二
#!/usr/bin/env python
# coding:utf-8
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='127.0.0.1'))
channel = connection.channel()
# 定義宣告,為logs
channel.exchange_declare(exchange='logs',
type='fanout')
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue
# 生成了一個隨機名稱
# 讓佇列和exchange進行繫結,以後生產者傳送來資料,exchange就會往queue中轉發資料
channel.queue_bind(exchange='logs',
queue=queue_name)
print(' [*] Waiting for logs. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] %r" % body)
# 一直去取資料
channel.basic_consume(callback,
queue=queue_name,
no_ack=True)
channel.start_consuming()
可以同時使用兩個來測試,同時都能接收到資料
5)關鍵字傳送
exchange type = direct
之前事例,傳送訊息時明確指定某個佇列並向其中傳送訊息,RabbitMQ還支援根據關鍵字傳送,即:佇列繫結關鍵字,傳送者將資料根據關鍵字傳送到訊息exchange,exchange根據 關鍵字 判定應該將資料傳送至指定佇列。
訂閱者一:
#!/usr/bin/env python
# coding:utf-8
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='127.0.0.1'))
channel = connection.channel()
channel.exchange_declare(exchange='direct_logs',
type='direct')
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue
channel.queue_bind(exchange='direct_logs',
queue=queue_name,
routing_key='aaa')
channel.queue_bind(exchange='direct_logs', queue=queue_name, routing_key='bbb')
print(' [*] Waiting for logs. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] %r:%r" % (method.routing_key, body))
channel.basic_consume(callback,
queue=queue_name,
no_ack=True)
channel.start_consuming()
訂閱者二
#!/usr/bin/env python
# coding:utf-8
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='127.0.0.1'))
channel = connection.channel()
channel.exchange_declare(exchange='direct_logs',
type='direct')
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue
channel.queue_bind(exchange='direct_logs',
queue=queue_name,
routing_key='bbb')
channel.queue_bind(exchange='direct_logs', queue=queue_name, routing_key='ccc')
print(' [*] Waiting for logs. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] %r:%r" % (method.routing_key, body))
channel.basic_consume(callback,
queue=queue_name,
no_ack=True)
channel.start_consuming()
生產者
#!/usr/bin/env python
# coding:utf-8
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='127.0.0.1'))
channel = connection.channel()
channel.exchange_declare(exchange='direct_logs',
type='direct')
message = 'Hello World!'
channel.basic_publish(exchange='direct_logs',
routing_key='ccc', # 指定訂閱者的佇列關鍵字是ccc
body=message)
print(" [x] Sent %r" % (message))
此時,只有訂閱者二符合,會有資料收到
6)模糊匹配
exchange type = topic
在topic型別下,可以讓佇列繫結幾個模糊的關鍵字,之後傳送者將資料傳送到exchange,exchange將傳入”路由值“和 ”關鍵字“進行匹配,匹配成功,則將資料傳送到指定佇列。
# 表示可以匹配 0 個 或 多個 單詞
* 表示只能匹配 一個 單詞
訂閱者1
#!/usr/bin/env python
# coding:utf-8
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='127.0.0.1'))
channel = connection.channel()
channel.exchange_declare(exchange='topic_logs',
type='topic')
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue
channel.queue_bind(exchange='topic_logs',
queue=queue_name,
routing_key='cgt.*')
print(' [*] Waiting for logs. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] %r:%r" % (method.routing_key, body))
channel.basic_consume(callback,
queue=queue_name,
no_ack=True)
channel.start_consuming()
訂閱者2
#!/usr/bin/env python
# coding:utf-8
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='127.0.0.1'))
channel = connection.channel()
channel.exchange_declare(exchange='topic_logs',
type='topic')
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue
channel.queue_bind(exchange='topic_logs',
queue=queue_name,
routing_key='cgt.#')
print(' [*] Waiting for logs. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] %r:%r" % (method.routing_key, body))
channel.basic_consume(callback,
queue=queue_name,
no_ack=True)
channel.start_consuming()
生產者
#!/usr/bin/env python
# coding:utf-8
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='127.0.0.1'))
channel = connection.channel()
channel.exchange_declare(exchange='topic_logs',
type='topic')
message = 'Hello World!'
channel.basic_publish(exchange='topic_logs',
routing_key='cgt.caoxiaojian.com',
body=message)
print(" [x] Sent %r:%r" % (message))
connection.close()
這樣測試,只有訂閱者2收到,因為他是#