keepalived介紹
keepalived觀察其名可知,保持存活,在網路裡面就是保持線上了,也就是所謂的高可用或熱備,它叢集管理中保證叢集高可用的一個服務軟體,其功能類似於heartbeat,用來防止單點故障(單點故障是指一旦某一點出現故障就會導致整個系統架構的不可用)的發生。說到keepalived就不得不說VRRP協議,可以說這個協議就是keepalived實現的基礎,那麼首先我們來看看VRRP協議。
VRRP協議介紹
學過網路的朋友都知道,網路在設計的時候必須考慮到冗餘容災,包括線路冗餘,裝置冗餘等,防止網路存在單點故障,那在路由器或三層交換機處實現冗餘就顯得尤為重要。
在網路裡面有個協議就是來做這事的,這個協議就是VRRP協議,Keepalived就是巧用VRRP協議來實現高可用性(HA)的發生。
VRRP全稱Virtual Router Redundancy Protocol,即虛擬路由冗餘協議。對於VRRP,需要清楚知道的是:
1)VRRP是用來實現路由器冗餘的協議。
2)VRRP協議是為了消除在靜態預設路由環境下路由器單點故障引起的網路失效而設計的主備模式的協議,使得發生故障而進行設計裝置功能切換時可以不影響內外資料通訊,不需要再修改內部網路的網路引數。
3)VRRP協議需要具有IP備份,優先路由選擇,減少不必要的路由器通訊等功能。
4)VRRP協議將兩臺或多臺路由器裝置虛擬成一個裝置,對外提供虛擬路由器IP(一個或多個)。然而,在路由器組內部,如果實際擁有這個對外IP的路由器如果工作正常的話,就是master,或者是通過演算法選舉產生的,MASTER實現針對虛擬路由器IP的各種網路功能,如ARP請求,ICMP,以及資料的轉發等,其他裝置不具有該IP,狀態是BACKUP。除了接收MASTER的VRRP狀態通告資訊外,不執行對外的網路功能,當主級失效時,BACKUP將接管原先MASTER的網路功能。
5)VRRP協議配置時,需要配置每個路由器的虛擬路由ID(VRID)和優先權值,使用VRID將路由器進行分組,具有相同VRID值的路由器為同一個組,VRID是一個0-255的整整數,;同一個組中的路由器通過使用優先權值來選舉MASTER。,優先權大者為MASTER,優先權也是一個0-255的正整數。
keepalived工作原理
keepalived可提供vrrp以及health-check功能,可以只用它提供雙機浮動的vip(vrrp虛擬路由功能),這樣可以簡單實現一個雙機熱備高可用功能;keepalived是以VRRP虛擬路由冗餘協議為基礎實現高可用的,可以認為是實現路由器高可用的協議,即將N臺提供相同功能的路由器組成一個路由器組,這個組裡面有一個master和多個backup,master上面有一個對外提供服務的vip(該路由器所在區域網內其他機器的預設路由為該vip),master會發組播,當backup收不到VRRP包時就認為master宕掉了,這時就需要根據VRRP的優先順序來選舉一個backup當master。這樣的話就可以保證路由器的高可用了。
下圖是keepalived的元件圖
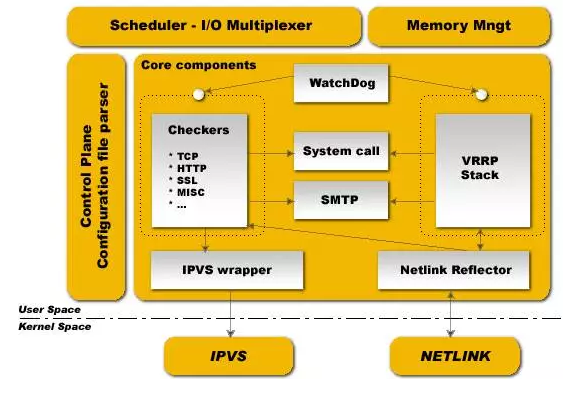
keepalived也是模組化設計,不同模組複雜不同的功能,它主要有三個模組,分別是core、check和VRRP,其中:
core模組:為keepalived的核心元件,負責主程式的啟動、維護以及全域性配置檔案的載入和解析;
check:負責健康檢查,包括常見的各種檢查方式;
VRRP模組:是來實現VRRP協議的。
system call:系統呼叫
watch dog:監控check和vrrp程式的看管者,check負責檢測器子程式的健康狀態,當其檢測到master上的服務不可用時則通告vrrp將其轉移至backup伺服器上。
除此之外,keepalived還有下面兩個元件:
libipfwc:iptables(ipchains)庫,配置LVS會用到
libipvs*:配置LVS會用到
注意,keepalived和LVS完全是兩碼事,只不過他們各負其責相互配合而已。
keepalived正常啟動的時候,共啟動3個程式:
一個是父程式,負責監控其子程式;一個是VRRP子程式,另外一個是checkers子程式;
兩個子程式都被系統watchlog看管,兩個子程式各自負責複雜自己的事。
Healthcheck子程式檢查各自伺服器的健康狀況,,例如http,lvs。如果healthchecks程式檢查到master上服務不可用了,就會通知本機上的VRRP子程式,讓他刪除通告,並且去掉虛擬IP,轉換為BACKUP狀態。
Keepalived作用
Keepalived主要用作RealServer的健康狀態檢查以及LoadBalance主機和BackUP主機之間failover的實現。Keepalived的作用是檢測web伺服器的狀態,如果有一臺web伺服器當機,或工作出現故障,Keepalived將檢測到,並將有故障的web伺服器從系統中剔除,當web伺服器工作正常後Keepalived自動將web伺服器加入到伺服器群中,這些工作全部自動完成,不需要人工干涉,需要人工做的只是修復故障的web伺服器。
----------------------------------------------------------------------------------------------------------------------------
Keepalived和Heartbeat之間的對比
1)Keepalived使用更簡單:從安裝、配置、使用、維護等角度上對比,Keepalived都比Heartbeat要簡單得多,尤其是Heartbeat2.1.4後拆分成3個子專案,安裝、配置、使用都比較複雜,尤其是出問題的時候,都不知道具體是哪個子系統出問題了;而Keepalived只有1個安裝檔案、1個配置檔案,配置檔案也簡單很多;
2)Heartbeat功能更強大:Heartbeat雖然複雜,但功能更強大,配套工具更全,適合做大型叢集管理,而Keepalived主要用於叢集倒換,基本沒有管理功能;
3)協議不同:Keepalived使用VRRP協議進行通訊和選舉,Heartbeat使用心跳進行通訊和選舉;Heartbeat除了走網路外,還可以通過串列埠通訊,貌似更可靠;
Keepalived使用的vrrp協議方式,虛擬路由冗餘協議 ;Heartbeat是基於主機或網路的服務的高可用方式;
Keepalived的目的是模擬路由器的雙機;Heartbeat的目的是使用者service的雙機
4)使用方式基本類似:如果要基於兩者設計高可用方案,最終都要根據業務需要寫自定義的指令碼,Keepalived的指令碼沒有任何約束,隨便怎麼寫都可以;Heartbeat的指令碼有約束,即要支援service start/stop/restart這種方式,而且Heartbeart提供了很多預設指令碼,簡單的繫結ip,啟動apache等操作都已經有了;
使用建議:
優先使用Keepalived,當Keepalived不夠用的時候才選擇Heartbeat
lvs的高可用建議用Keepavlived
業務的高可用用Heartbeat
--------------------------------------------------------------------------------------------------------------------------
keepalived的配置檔案
keepalived只有一個配置檔案keepalived.conf,配置檔案裡面主要包括以下幾個配置項,分別是global_defs、static_ipaddress、static_routes、VRRP_script、VRRP_instance和virtual_server。
總的來說,keepalived主要有三類區域配置,注意不是三種配置檔案,是一個配置檔案裡面三種不同類別的配置區域:
1)全域性配置(Global Configuration)
2)VRRPD配置
3)LVS配置
下面就重點來說說這三類區域的配置:
1)全域性配置
全域性配置又包括兩個子配置:
全域性定義(global definition)
靜態路由配置(static ipaddress/routes)
1--全域性定義(global definition)配置範例:
global_defs {
notification_email {
admin@example.com
}
notification_email_from admin@example.com
smtp_server 127.0.0.1
stmp_connect_timeout 30
router_id node1
}
全域性配置解析
global_defs全域性配置標識,表面這個區域{}是全域性配置
notification_email {
admin@example.com
admin@ywlm.net
}
表示keepalived在發生諸如切換操作時需要傳送email通知,以及email傳送給哪些郵件地址,郵件地址可以多個,每行一個
notification_email_from admin@example.com
表示傳送通知郵件時郵件源地址是誰
smtp_server 127.0.0.1
表示傳送email時使用的smtp伺服器地址,這裡可以用本地的sendmail來實現
smtp_connect_timeout 30
連線smtp連線超時時間
router_id node1
機器標識
2--靜態地址和路由配置範例
static_ipaddress {
192.168.1.1/24 brd + dev eth0 scope global
192.168.1.2/24 brd + dev eth1 scope global
}
static_routes {
src $SRC_IP to $DST_IP dev $SRC_DEVICE
src $SRC_IP to $DST_IP via $GW dev $SRC_DEVICE
}
這裡實際上和系統裡面用命令配置IP地址和路由的曹一樣,例如:
192.168.1.1/24 brd + dev eth0 scope global 相當於: ip addr add 192.168.1.1/24 brd + dev eth0 scope global
就是給eth0配置IP地址
路由同理
一般這個區域不需要配置
這裡實際上就是給伺服器配置真實的IP地址和路由的,在複雜的環境下可能需要配置,一般不會用這個來配置,我們可以直接用vi /etc/sysconfig/network-script/ifcfg-eth1來配置,切記這裡可不是VIP哦,不要搞混淆了,切記切記!
2)VRRPD配置
VRRPD配置包括三個類:
VRRP同步組(synchroization group)
VRRP例項(VRRP Instance)
VRRP指令碼
1--VRRP同步組(synchroization group)配置範例
vrrp_sync_group VG_1 {
group {
http
mysql
}
notify_master /path/to/to_master.sh
notify_backup /path_to/to_backup.sh
notify_fault “/path/fault.sh VG_1”
notify /path/to/notify.sh
smtp_alert
}
其中:
group {
http
mysql
}
http和mysql是例項名和下面的例項名一致
notify_master /path/to/to_master.sh:表示當切換到master狀態時,要執行的指令碼
notify_backup /path_to/to_backup.sh:表示當切換到backup狀態時,要執行的指令碼
notify_fault “/path/fault.sh VG_1”
notify /path/to/notify.sh:
smtp alter表示切換時給global defs中定義的郵件地址傳送右鍵通知
2--VRRP例項(instance)配置範例
vrrp_instance http {
state MASTER
interface eth0
dont_track_primary
track_interface {
eth0
eth1
}
mcast_src_ip <IPADDR>
garp_master_delay 10
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
autp_pass 1234
}
virtual_ipaddress {
#<IPADDR>/<MASK> brd <IPADDR> dev <STRING> scope <SCOPT> label <LABEL>
192.168.200.17/24 dev eth1
192.168.200.18/24 dev eth2 label eth2:1
}
virtual_routes {
# src <IPADDR> [to] <IPADDR>/<MASK> via|gw <IPADDR> dev <STRING> scope <SCOPE> tab
src 192.168.100.1 to 192.168.109.0/24 via 192.168.200.254 dev eth1
192.168.110.0/24 via 192.168.200.254 dev eth1
192.168.111.0/24 dev eth2
192.168.112.0/24 via 192.168.100.254
}
nopreempt
preemtp_delay 300
debug
}
state:state指定instance(Initial)的初始狀態,就是說在配置好後,這臺伺服器的初始狀態就是這裡指定的,但這裡指定的不算,還是得要通過競選通過優先順序來確定,裡如果這裡設定為master,但如若他的優先順序不及另外一臺,那麼這臺在傳送通告時,會傳送自己的優先順序,另外一臺發現優先順序不如自己的高,那麼他會就回搶佔為master
interface:例項繫結的網路卡,因為在配置虛擬IP的時候必須是在已有的網路卡上新增的
dont track primary:忽略VRRP的interface錯誤
track interface:跟蹤介面,設定額外的監控,裡面任意一塊網路卡出現問題,都會進入故障(FAULT)狀態,例如,用nginx做均衡器的時候,內網必須正常工作,如果內網出問題了,這個均衡器也就無法運作了,所以必須對內外網同時做健康檢查
mcast src ip:傳送多播資料包時的源IP地址,這裡注意了,這裡實際上就是在那個地址上傳送VRRP通告,這個非常重要,一定要選擇穩定的網路卡埠來傳送,這裡相當於heartbeat的心跳埠,如果沒有設定那麼就用預設的繫結的網路卡的IP,也就是interface指定的IP地址
garp master delay:在切換到master狀態後,延遲進行免費的ARP(gratuitous ARP)請求
virtual router id:這裡設定VRID,這裡非常重要,相同的VRID為一個組,他將決定多播的MAC地址
priority 100:設定本節點的優先順序,優先順序高的為master
advert int:檢查間隔,預設為1秒
virtual ipaddress:這裡設定的就是VIP,也就是虛擬IP地址,他隨著state的變化而增加刪除,當state為master的時候就新增,當state為backup的時候刪除,這裡主要是有優先順序來決定的,和state設定的值沒有多大關係,這裡可以設定多個IP地址
virtual routes:原理和virtual ipaddress一樣,只不過這裡是增加和刪除路由
lvs sync daemon interface:lvs syncd繫結的網路卡
authentication:這裡設定認證
auth type:認證方式,可以是PASS或AH兩種認證方式
auth pass:認證密碼
nopreempt:設定不搶佔,這裡只能設定在state為backup的節點上,而且這個節點的優先順序必須別另外的高
preempt delay:搶佔延遲
debug:debug級別
notify master:和sync group這裡設定的含義一樣,可以單獨設定,例如不同的例項通知不同的管理人員,http例項發給網站管理員,mysql的就發郵件給DBA
3--VRRP指令碼範例
vrrp_script check_running {
script “/usr/local/bin/check_running”
interval 10
weight 10
}
vrrp_instance http {
state BACKUP
smtp_alert
interface eth0
virtual_router_id 101
priority 90
advert_int 3
authentication {
auth_type PASS
auth_pass whatever
}
virtual_ipaddress {
1.1.1.1
}
track_script {
check_running weight 20
}
}
首先在vrrp_script區域定義指令碼名字和指令碼執行的間隔和指令碼執行的優先順序變更vrrp_script check_running {
script “/usr/local/bin/check_running” interval 10 #指令碼執行間隔 weight 10 #指令碼結果導致的優先順序變更:10表示優先順序+10;-10則表示優先順序-10 }
然後在例項(vrrp_instance)裡面引用,有點類似指令碼里面的函式引用一樣:先定義,後引用函式名
track_script {
check_running weight 20
}
注意:VRRP指令碼(vrrp_script)和VRRP例項(vrrp_instance)屬於同一個級別
3)LVS配置
如果你沒有配置LVS+keepalived,那麼無需配置這段區域,如果你用的是nginx來代替LVS,這無需配置這款,這裡的LVS配置是專門為keepalived+LVS整合準備的。
注意了,這裡LVS配置並不是指真的安裝LVS然後用ipvsadm來配置它,而是用keepalived的配置檔案來代替ipvsadm來配置LVS,這樣會方便很多,一個配置檔案搞定這些,維護方便,配置方便是也!
這裡LVS配置也有兩個配置
一個是虛擬主機組配置
一個是虛擬主機配置
1--虛擬主機組配置檔案詳解
這個配置是可選的,根據需求來配置吧,這裡配置主要是為了讓一臺realserver上的某個服務可以屬於多個Virtual Server,並且只做一次健康檢查:
virtual_server_group <STRING> { # VIP port <IPADDR> <PORT> <IPADDR> <PORT> fwmark <INT> }
2--虛擬主機配置
virtual server可以以下面三種的任意一種來配置:
a)virtual server IP port
b)virtual server fwmark int
c)virtual server group string
下面以第一種比較常用的方式來配詳細解說一下:
virtual_server 192.168.1.2 80 { #設定一個virtual server: VIP:Vport
delay_loop 3 # service polling的delay時間,即服務輪詢的時間間隔
lb_algo rr|wrr|lc|wlc|lblc|sh|dh #LVS排程演算法
lb_kind NAT|DR|TUN #LVS叢集模式
persistence_timeout 120 #會話保持時間(秒為單位),即以使用者在120秒內被分配到同一個後端realserver
persistence_granularity <NETMASK> #LVS會話保持粒度,ipvsadm中的-M引數,預設是0xffffffff,即每個客戶端都做會話保持
protocol TCP #健康檢查用的是TCP還是UDP
ha_suspend #suspendhealthchecker’s activity
virtualhost <string> #HTTP_GET做健康檢查時,檢查的web伺服器的虛擬主機(即host:頭)
sorry_server <IPADDR> <PORT> #備用機,就是當所有後端realserver節點都不可用時,就用這裡設定的,也就是臨時把所有的請求都傳送到這裡啦
real_server <IPADDR> <PORT> #後端真實節點主機的權重等設定,主要,後端有幾臺這裡就要設定幾個
{
weight 1 #給每臺的權重,0表示失效(不知給他轉發請求知道他恢復正常),預設是1
inhibit_on_failure #表示在節點失敗後,把他權重設定成0,而不是衝IPVS中刪除
notify_up <STRING> | <QUOTED-STRING> #檢查伺服器正常(UP)後,要執行的指令碼
notify_down <STRING> | <QUOTED-STRING> #檢查伺服器失敗(down)後,要執行的指令碼
HTTP_GET #健康檢查方式
{
url { #要堅持的URL,可以有多個
path / #具體路徑
digest <STRING>
status_code 200 #返回狀態碼
}
connect_port 80 #監控檢查的埠
bindto <IPADD> #健康檢查的IP地址
connect_timeout 3 #連線超時時間
nb_get_retry 3 #重連次數
delay_before_retry 2 #重連間隔
} # END OF HTTP_GET|SSL_GET
#下面是常用的健康檢查方式,健康檢查方式一共有HTTP_GET|SSL_GET|TCP_CHECK|SMTP_CHECK|MISC_CHECK這些
#TCP方式
TCP_CHECK {
connect_port 80
bindto 192.168.1.1
connect_timeout 4
} # TCP_CHECK
# SMTP方式,這個可以用來給郵件伺服器做叢集
SMTP_CHECK
host {
connect_ip <IP ADDRESS>
connect_port <PORT> #預設檢查25埠
14 KEEPALIVED
bindto <IP ADDRESS>
}
connect_timeout <INTEGER>
retry <INTEGER>
delay_before_retry <INTEGER>
# “smtp HELO”ž|·-ë꧌à”
helo_name <STRING>|<QUOTED-STRING>
} #SMTP_CHECK
#MISC方式,這個可以用來檢查很多伺服器只需要自己會些指令碼即可
MISC_CHECK
{
misc_path <STRING>|<QUOTED-STRING> #外部程式或指令碼
misc_timeout <INT> #指令碼或程式執行超時時間
misc_dynamic #這個就很好用了,可以非常精確的來調整權重,是後端每天伺服器的壓力都能均衡調配,這個主要是通過執行的程式或指令碼返回的狀態程式碼來動態調整weight值,使權重根據真實的後端壓力來適當調整,不過這需要有過硬的指令碼功夫才行哦
#返回0:健康檢查沒問題,不修改權重
#返回1:健康檢查失敗,權重設定為0
#返回2-255:健康檢查沒問題,但是權重卻要根據返回程式碼修改為返回碼-2,例如如果程式或指令碼執行後返回的程式碼為200,#那麼權重這回被修改為 200-2
}
} # Realserver
} # Virtual Server
================================小案例 分享=============================
172.16.60.205 作為web-master主節點, 172.16.60.206 作為web-slave從節點, 兩節點上都部署nginx.
現在在兩節點上部署keepalived, 只做節點故障時vip轉移功能, 不做負載均衡功能.
vip為: 172.16.60.129
1) 主從兩節點部署nginx, 安裝和配置過程省略. 配置一樣, 訪問內容一致!
yum安裝的nginx, 啟動命令: /etc/init.d/nginx start
http://172.16.60.205/ 和 http://172.16.60.205/ 均可以正常訪問.
2) 主從兩節點安裝keepalived (兩個節點都要安裝)
[root@web-master ~]# yum install -y openssl-devel
[root@web-master ~]# cd /usr/local/src/
[root@web-master src]# wget http://www.keepalived.org/software/keepalived-1.3.5.tar.gz
[root@web-master src]# tar -zvxf keepalived-1.3.5.tar.gz
[root@web-master src]# cd keepalived-1.3.5
[root@web-master keepalived-1.3.5]# ./configure --prefix=/usr/local/keepalived
[root@web-master keepalived-1.3.5]# make && make install
[root@web-master keepalived-1.3.5]# cp /usr/local/src/keepalived-1.3.5/keepalived/etc/init.d/keepalived /etc/rc.d/init.d/
[root@web-master keepalived-1.3.5]# cp /usr/local/keepalived/etc/sysconfig/keepalived /etc/sysconfig/
[root@web-master keepalived-1.3.5]# mkdir /etc/keepalived/
[root@web-master keepalived-1.3.5]# cp /usr/local/keepalived/etc/keepalived/keepalived.conf /etc/keepalived/
[root@web-master keepalived-1.3.5]# cp /usr/local/keepalived/sbin/keepalived /usr/sbin/
[root@web-master keepalived-1.3.5]# echo "/etc/init.d/keepalived start" >> /etc/rc.local
[root@web-master keepalived-1.3.5]# chmod +x /etc/rc.d/init.d/keepalived
[root@web-master keepalived-1.3.5]# chkconfig keepalived on
3) keepalived配置
==========web-master 主節點的配置==========
[root@web-master ~]# cd /etc/keepalived/
[root@web-master keepalived]# cp keepalived.conf keepalived.conf.bak
[root@web-master keepalived]# >keepalived.conf
[root@web-master keepalived]# vim keepalived.conf
! Configuration File for keepalived
global_defs {
router_id LVS_Master
}
vrrp_instance VI_1 {
state MASTER #指定instance初始狀態,實際根據優先順序決定.backup節點不一樣
interface eth0 #虛擬IP所在網
virtual_router_id 51 #VRID,相同VRID為一個組,決定多播MAC地址
priority 100 #優先順序,另一臺改為90.backup節點不一樣
advert_int 1 #檢查間隔
authentication {
auth_type PASS #認證方式,可以是pass或ha
auth_pass 1111 #認證密碼
}
virtual_ipaddress {
172.16.60.129 #VIP地址
}
}
==========web-slave 從節點的配置==========
[root@web-slave ~]# cd /etc/keepalived/
[root@web-slave keepalived]# cp keepalived.conf keepalived.conf.bak
[root@web-slave keepalived]# >keepalived.conf
[root@web-slave keepalived]# vim keepalived.conf
! Configuration File for keepalived
global_defs {
router_id LVS_Backup
}
vrrp_instance VI_1 {
state BACKUP
interface eth0
virtual_router_id 51
priority 90
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
172.16.60.129
}
}
4) 分別啟動主從節點的keepalived服務
啟動主節點keepalived服務
[root@web-master keepalived]# /etc/init.d/keepalived start
Starting keepalived: [ OK ]
[root@web-master keepalived]# ps -ef|grep keepalived
root 13529 1 0 16:36 ? 00:00:00 keepalived -D
root 13530 13529 0 16:36 ? 00:00:00 keepalived -D
root 13532 13529 0 16:36 ? 00:00:00 keepalived -D
root 13536 9799 0 16:36 pts/1 00:00:00 grep keepalived
啟動從節點keepalived服務
[root@web-slave keepalived]# /etc/init.d/keepalived start
Starting keepalived: [ OK ]
[root@web-slave keepalived]# ps -ef|grep keepalived
root 3120 1 0 16:37 ? 00:00:00 keepalived -D
root 3121 3120 0 16:37 ? 00:00:00 keepalived -D
root 3123 3120 0 16:37 ? 00:00:00 keepalived -D
root 3128 27457 0 16:37 pts/2 00:00:00 grep keepalived
檢視vip資源情況 (預設vip是在主節點上的)
[root@web-master keepalived]# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP qlen 1000
link/ether 00:50:56:88:43:f8 brd ff:ff:ff:ff:ff:ff
inet 172.16.60.205/24 brd 172.16.60.255 scope global eth0
inet 172.16.60.129/32 scope global eth0
inet6 fe80::250:56ff:fe88:43f8/64 scope link
valid_lft forever preferred_lft forever
從節點沒有vip資源
[root@web-slave keepalived]# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP qlen 1000
link/ether 00:50:56:ac:50:9b brd ff:ff:ff:ff:ff:ff
inet 172.16.60.206/24 brd 172.16.60.255 scope global eth0
inet6 fe80::250:56ff:feac:509b/64 scope link
valid_lft forever preferred_lft forever
5) keepalived 實現故障轉移 (轉移vip資源)
假設主節點當機或keepalived服務掛掉, 則vip資源就會自動轉移到從節點
[root@web-master keepalived]# /etc/init.d/keepalived stop
Stopping keepalived: [ OK ]
[root@web-master keepalived]# ps -ef|grep keepalived
root 13566 9799 0 16:40 pts/1 00:00:00 grep keepalived
[root@web-master keepalived]# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP qlen 1000
link/ether 00:50:56:88:43:f8 brd ff:ff:ff:ff:ff:ff
inet 172.16.60.205/24 brd 172.16.60.255 scope global eth0
inet6 fe80::250:56ff:fe88:43f8/64 scope link
valid_lft forever preferred_lft forever
則從節點這邊就會接管vip
[root@web-slave keepalived]# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP qlen 1000
link/ether 00:50:56:ac:50:9b brd ff:ff:ff:ff:ff:ff
inet 172.16.60.206/24 brd 172.16.60.255 scope global eth0
inet 172.16.60.129/32 scope global eth0
inet6 fe80::250:56ff:feac:509b/64 scope link
valid_lft forever preferred_lft forever
接著再重啟主節點的keepalived服務, 即主節點故障恢復後, 就會重新搶回vip (根據配置裡的優先順序決定的)
[root@web-master keepalived]# /etc/init.d/keepalived start
Starting keepalived: [ OK ]
[root@web-master keepalived]# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP qlen 1000
link/ether 00:50:56:88:43:f8 brd ff:ff:ff:ff:ff:ff
inet 172.16.60.205/24 brd 172.16.60.255 scope global eth0
inet 172.16.60.129/32 scope global eth0
inet6 fe80::250:56ff:fe88:43f8/64 scope link
valid_lft forever preferred_lft forever
這時候, 從節點的vip就消失了
[root@web-slave keepalived]# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP qlen 1000
link/ether 00:50:56:ac:50:9b brd ff:ff:ff:ff:ff:ff
inet 172.16.60.206/24 brd 172.16.60.255 scope global eth0
inet6 fe80::250:56ff:feac:509b/64 scope link
valid_lft forever preferred_lft forever
以上操作, keepalived僅僅實現了兩臺機器的vip的故障轉移功能, 即實現了雙機熱備, 避免了單點故障.
即keepalived配置裡僅僅只是在當機(或keepalived服務掛掉)後才實現vip轉移, 並沒有實現所監控應用故障時的vip轉移.
比如案例中兩臺機器的nginx, 可以監控nginx, 當nginx掛掉後,實現自啟動, 如果強啟失敗, 則將vip轉移到對方節點.
這種情況的配置可以參考另一篇博文: https://www.cnblogs.com/kevingrace/p/6138185.html
============下面是曾經使用過的一個案例: 三臺節點機器,配置三個VIP,實行相互之間的"兩主兩從"模式=============
server1:第一臺節點的keepalived.conf配置. 其中VIP:192.168.20.187
[root@keepalived-node01 ~]# cat /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
notification_email {
kevin@bobo.com
}
smtp_server 192.168.200.1
smtp_connect_timeout 30
router_id innodb_cluster #區域網中需要共享該vip的伺服器,該配置要一致
vrrp_skip_check_adv_addr
vrrp_garp_interval 0
vrrp_gna_interval 0
}
vrrp_instance VI_1 {
state MASTER #狀態為master,表明 keepalived 啟動後會搶佔IP, 但,下面的優先順序值201要高於 從庫的優先順序 101
interface eth0 #viP 繫結的網路卡
virtual_router_id 191 #這個組隊標誌,同一個vrrp 下的 值一致,主從一致
priority 201 # 主庫為201,高於從庫101
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.20.187 #這是VIP 值
}
}
vrrp_instance VI_2 {
state BACKUP #狀態為 BACKUP,表明 keepalived 啟動後不搶佔IP
interface eth0 #VIP 繫結的介面
virtual_router_id 193 #組隊標識,同一個vrrp 下的值一致
priority 101 #設定優先順序小於另一個節點的priority 上值。
advert_int 1
authentication {
auth_type PASS
auth_pass 3333
}
virtual_ipaddress {
192.168.20.189
}
}
啟動keepalived
[root@keepalived-node01 ~]# /etc/init.d/keepalived start
[root@keepalived-node01 ~]# ps -ef|grep keepalived
root 13746 1 0 16:31 ? 00:00:00 /usr/sbin/keepalived -D
root 13747 13746 0 16:31 ? 00:00:00 /usr/sbin/keepalived -D
root 13748 13746 0 16:31 ? 00:00:00 /usr/sbin/keepalived -D
root 14089 13983 0 16:36 pts/1 00:00:00 grep --color=auto keepalived
啟動keepalived服務後,檢視ip
[root@keepalived-node01 ~]# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 2e:ab:68:68:ee:90 brd ff:ff:ff:ff:ff:ff
inet 192.168.20.191/24 brd 192.168.20.255 scope global noprefixroute eth0
valid_lft forever preferred_lft forever
inet 192.168.20.187/32 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::2cab:68ff:fe68:ee90/64 scope link
valid_lft forever preferred_lft forever
==========================================================================================
server2:第二臺節點的keepalived.conf配置. 其中VIP:192.168.20.188
[root@keepalived-node02 ~]# cat /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
notification_email {
kevin@bobo.com
}
smtp_server 192.168.200.1
smtp_connect_timeout 30
router_id innodb_cluster #區域網中需要共享該vip的伺服器,該配置要一致
vrrp_skip_check_adv_addr
vrrp_garp_interval 0
vrrp_gna_interval 0
}
vrrp_instance VI_1 {
state MASTER #狀態為master,表明 keepalived 啟動後會搶佔IP, 但,下面的優先順序值201要高於 從庫的優先順序 101
interface eth0 #viP 繫結的網路卡
virtual_router_id 192 #這個組隊標誌,同一個vrrp 下的 值一致,主從一致
priority 201 # 主庫為201,高於從庫101
advert_int 1
authentication {
auth_type PASS
auth_pass 2222
}
virtual_ipaddress {
192.168.20.188 #這是VIP 值
}
}
vrrp_instance VI_2 {
state BACKUP #狀態為 BACKUP,表明 keepalived 啟動後不搶佔IP
interface eth0 #VIP 繫結的介面
virtual_router_id 191 #組隊標識,同一個vrrp 下的值一致
priority 101 #設定優先順序小於另一個節點的priority 上值。
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.20.187
}
}
啟動keepalived
[root@keepalived-node02 ~]# /etc/init.d/keepalived start
[root@keepalived-node02 ~]# ps -ef|grep keepalived
root 13327 1 0 16:32 ? 00:00:00 /usr/sbin/keepalived -D
root 13328 13327 0 16:32 ? 00:00:00 /usr/sbin/keepalived -D
root 13329 13327 0 16:32 ? 00:00:00 /usr/sbin/keepalived -D
root 13570 13529 0 16:39 pts/1 00:00:00 grep --color=auto keepalived
啟動keepalived服務後檢視ip
[root@keepalived-node02 ~]# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 76:6d:74:97:03:15 brd ff:ff:ff:ff:ff:ff
inet 192.168.20.192/24 brd 192.168.20.255 scope global noprefixroute eth0
valid_lft forever preferred_lft forever
inet 192.168.20.188/32 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::746d:74ff:fe97:315/64 scope link
valid_lft forever preferred_lft forever
==========================================================================================
server3:第三臺節點的keepalived.conf配置. 其中VIP:192.168.20.189
[root@keepalived-node03 ~]# cat /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
notification_email {
kevin@bobo.com
}
smtp_server 192.168.200.1
smtp_connect_timeout 30
router_id innodb_cluster #和server1 一致全域性唯一
vrrp_skip_check_adv_addr
# vrrp_strict
vrrp_garp_interval 0
vrrp_gna_interval 0
}
vrrp_instance VI_1 {
state BACKUP #主是master,從就是backup
interface eth0
virtual_router_id 192 # 組隊標識,同一個vrrp 下一致
priority 101 #優先順序也變小
advert_int 1
authentication {
auth_type PASS
auth_pass 2222
}
virtual_ipaddress {
192.168.20.188
}
}
vrrp_instance VI_2 {
state MASTER #主變成MASTER
interface eth0 #繫結網路卡
virtual_router_id 193 #組隊標誌,同一個vip 下一致
priority 201 #優先順序提升
advert_int 1
authentication {
auth_type PASS
auth_pass 3333
}
virtual_ipaddress {
192.168.20.189
}
}
啟動keepalived
[root@keepalived-node03 ~]# /etc/init.d/keepalived start
[root@keepalived-node03 ~]# ps -ef|grep keepalived
root 13134 1 0 16:33 ? 00:00:00 /usr/sbin/keepalived -D
root 13135 13134 0 16:33 ? 00:00:00 /usr/sbin/keepalived -D
root 13136 13134 0 16:33 ? 00:00:00 /usr/sbin/keepalived -D
root 13526 13460 0 16:41 pts/1 00:00:00 grep --color=auto keepalived
啟動keepalived服務後檢視ip
[root@keepalived-node03 ~]# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 22:ee:46:41:f0:e6 brd ff:ff:ff:ff:ff:ff
inet 192.168.20.193/24 brd 192.168.20.255 scope global noprefixroute eth0
valid_lft forever preferred_lft forever
inet 192.168.20.189/32 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::20ee:46ff:fe41:f0e6/64 scope link
valid_lft forever preferred_lft forever
溫馨提示:
如上,keepalived.conf配置後,重啟keepalived服務,重啟成功並且vip地址已經有了,但是死活ping不通vip地址!!
這是因為keepalived.conf檔案中的vrrp_strict引數引起的,將該引數註釋掉就可以了!!!
vrrp_strict 表示嚴格執行VRRP協議規範,此模式不支援節點單播
VIP地址ping不通,需要註釋vrrp_strict引數配置即可!