0.前言
文章較長,而且內容相對來說比較枯燥,希望對C++物件的記憶體佈局、虛表指標、虛基類指標等有深入瞭解的朋友可以慢慢看。本文的結論都在VS2013上得到驗證。不同的編譯器在記憶體佈局的細節上可能有所不同。
文章如果有解釋不清、解釋不通或疏漏的地方,懇請指出。
1.何為C++物件模型?
引用《深度探索C++物件模型》這本書中的話:
有兩個概念可以解釋C++物件模型:
- 語言中直接支援物件導向程式設計的部分。
- 對於各種支援的底層實現機制。
直接支援物件導向程式設計,包括了建構函式、解構函式、多型、虛擬函式等等,這些內容在很多書籍上都有討論,也是C++最被人熟知的地方(特性)。而物件模型的底層實現機制卻是很少有書籍討論的。物件模型的底層實現機制並未標準化,不同的編譯器有一定的自由來設計物件模型的實現細節。在我看來,物件模型研究的是物件在儲存上的空間與時間上的更優,並對C++物件導向技術加以支援,如以虛指標、虛表機制支援多型特性。
2.文章內容簡介
這篇文章主要來討論C++物件在記憶體中的佈局,屬於第二個概念的研究範疇。而C++直接支援物件導向程式設計部分則不多講。文章主要內容如下:
- 虛擬函式表解析。含有虛擬函式或其父類含有虛擬函式的類,編譯器都會為其新增一個虛擬函式表,vptr,先了解虛擬函式表的構成,有助對C++物件模型的理解。
- 虛基類表解析。虛繼承產生虛基類表(vbptr),虛基類表的內容與虛擬函式表完全不同,我們將在講解虛繼承時介紹虛擬函式表。
- 物件模型概述:介紹簡單物件模型、表格驅動物件模型,以及非繼承情況下的C++物件模型。
- 繼承下的C++物件模型。分析C++類物件在下面情形中的記憶體佈局:
- 單繼承:子類單一繼承自父類,分析了子類重寫父類虛擬函式、子類定義了新的虛擬函式情況下子類物件記憶體佈局。
- 多繼承:子類繼承於多個父類,分析了子類重寫父類虛擬函式、子類定義了新的虛擬函式情況下子類物件記憶體佈局,同時分析了非虛繼承下的菱形繼承。
- 虛繼承:分析了單一繼承下的虛繼承、多重基層下的虛繼承、重複繼承下的虛繼承。
- 理解物件的記憶體佈局之後,我們可以分析一些問題:
- C++封裝帶來的佈局成本是多大?
- 由空類組成的繼承層次中,每個類物件的大小是多大?
至於其他與記憶體有關的知識,我假設大家都有一定的瞭解,如記憶體對齊,指標操作等。本文初看可能晦澀難懂,要求讀者有一定的C++基礎,對概念一有一定的掌握。
3.理解虛擬函式表
3.1.多型與虛表
C++中虛擬函式的作用主要是為了實現多型機制。多型,簡單來說,是指在繼承層次中,父類的指標可以具有多種形態——當它指向某個子類物件時,通過它能夠呼叫到子類的函式,而非父類的函式。
|
1 2 3 |
class Base { virtual void print(void); } class Drive1 :public Base{ virtual void print(void); } class Drive2 :public Base{ virtual void print(void); } |
|
1 2 3 |
Base * ptr1 = new Base; Base * ptr2 = new Drive1; Base * ptr3 = new Drive2; |
|
1 2 3 |
ptr1->print(); //呼叫Base::print() prt2->print();//呼叫Drive1::print() prt3->print();//呼叫Drive2::print() |

這是一種執行期多型,即父類指標唯有在程式執行時才能知道所指的真正型別是什麼。這種執行期決議,是通過虛擬函式表來實現的。
3.2.使用指標訪問虛表
如果我們豐富我們的Base類,使其擁有多個virtual函式:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
class Base { public: Base(int i) :baseI(i){}; virtual void print(void){ cout << "呼叫了虛擬函式Base::print()"; } virtual void setI(){cout<<"呼叫了虛擬函式Base::setI()";} virtual ~Base(){} private: int baseI; }; |

當一個類本身定義了虛擬函式,或其父類有虛擬函式時,為了支援多型機制,編譯器將為該類新增一個虛擬函式指標(vptr)。虛擬函式指標一般都放在物件記憶體佈局的第一個位置上,這是為了保證在多層繼承或多重繼承的情況下能以最高效率取到虛擬函式表。
當vprt位於物件記憶體最前面時,物件的地址即為虛擬函式指標地址。我們可以取得虛擬函式指標的地址:
|
1 2 3 |
Base b(1000); int * vptrAdree = (int *)(&b); cout << "虛擬函式指標(vprt)的地址是:\t"<<vptrAdree << endl; |
我們執行程式碼出結果:

我們強行把類物件的地址轉換為 int* 型別,取得了虛擬函式指標的地址。虛擬函式指標指向虛擬函式表,虛擬函式表中儲存的是一系列虛擬函式的地址,虛擬函式地址出現的順序與類中虛擬函式宣告的順序一致。對虛擬函式指標地址值,可以得到虛擬函式表的地址,也即是虛擬函式表第一個虛擬函式的地址:
|
1 2 3 4 5 |
typedef void(*Fun)(void); Fun vfunc = (Fun)*( (int *)*(int*)(&b)); cout << "第一個虛擬函式的地址是:" << (int *)*(int*)(&b) << endl; cout << "通過地址,呼叫虛擬函式Base::print():"; vfunc(); |
- 我們把虛表指標的值取出來: *(int*)(&b),它是一個地址,虛擬函式表的地址
- 把虛擬函式表的地址強制轉換成 int* : ( int *) *( int* )( &b )
- 再把它轉化成我們Fun指標型別 : (Fun )*(int *)*(int*)(&b)
這樣,我們就取得了類中的第一個虛擬函式,我們可以通過函式指標訪問它。
執行結果:

同理,第二個虛擬函式setI()的地址為:
|
1 |
(int * )(*(int*)(&b)+1) |
同樣可以通過函式指標訪問它,這裡留給讀者自己試驗。
到目前為止,我們知道了類中虛表指標vprt的由來,知道了虛擬函式表中的內容,以及如何通過指標訪問虛擬函式表。下面的文章中將常使用指標訪問物件記憶體來驗證我們的C++物件模型,以及討論在各種繼承情況下虛表指標的變化,先把這部分的內容消化完再接著看下面的內容。
4.物件模型概述
在C++中,有兩種資料成員(class data members):static 和nonstatic,以及三種類成員函式(class member functions):static、nonstatic和virtual:

現在我們有一個類Base,它包含了上面這5中型別的資料或函式:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
class Base { public: Base(int i) :baseI(i){}; int getI(){ return baseI; } static void countI(){}; virtual void print(void){ cout << "Base::print()"; } virtual ~Base(){} private: int baseI; static int baseS; }; |

那麼,這個類在記憶體中將被如何表示?5種資料都是連續存放的嗎?如何佈局才能支援C++多型? 我們的C++標準與編譯器將如何塑造出各種資料成員與成員函式呢?
4.1.簡單物件模型
說明:在下面出現的圖中,用藍色邊框框起來的內容在記憶體上是連續的。
這個模型非常地簡單粗暴。在該模型下,物件由一系列的指標組成,每一個指標都指向一個資料成員或成員函式,也即是說,每個資料成員和成員函式在類中所佔的大小是相同的,都為一個指標的大小。這樣有個好處——很容易算出物件的大小,不過賠上的是空間和執行期效率。想象一下,如果我們的Point3d類是這種模型,將會比C語言的struct多了許多空間來存放指向函式的指標,而且每次讀取類的資料成員,都需要通過再一次定址——又是時間上的消耗。
所以這種物件模型並沒有被用於實際產品上。

4.2.表格驅動模型
這個模型在簡單物件模型的基礎上又新增一個間接層,它把類中的資料分成了兩個部分:資料部分與函式部分,並使用兩張表格,一張存放資料本身,一張存放函式的地址(也即函式比成員多一次定址),而類物件僅僅含有兩個指標,分別指向上面這兩個表。這樣看來,物件的大小是固定為兩個指標大小。這個模型也沒有用於實際應用於真正的C++編譯器上。
4.3.非繼承下的C++物件模型
概述:在此模型下,nonstatic 資料成員被置於每一個類物件中,而static資料成員被置於類物件之外。static與nonstatic函式也都放在類物件之外,而對於virtual 函式,則通過虛擬函式表+虛指標來支援,具體如下:
- 每個類生成一個表格,稱為虛表(virtual table,簡稱vtbl)。虛表中存放著一堆指標,這些指標指向該類每一個虛擬函式。虛表中的函式地址將按宣告時的順序排列,不過當子類有多個過載函式時例外,後面會討論。
- 每個類物件都擁有一個虛表指標(vptr),由編譯器為其生成。虛表指標的設定與重置皆由類的複製控制(也即是建構函式、解構函式、賦值操作符)來完成。vptr的位置為編譯器決定,傳統上它被放在所有顯示宣告的成員之後,不過現在許多編譯器把vptr放在一個類物件的最前端。關於資料成員佈局的內容,在後面會詳細分析。
另外,虛擬函式表的前面設定了一個指向type_info的指標,用以支援RTTI(Run Time Type Identification,執行時型別識別)。RTTI是為多型而生成的資訊,包括物件繼承關係,物件本身的描述等,只有具有虛擬函式的物件在會生成。
在此模型下,Base的物件模型如圖:

先在VS上驗證類物件的佈局:
|
1 |
Base b(1000); |

可見物件b含有一個vfptr,即vprt。並且只有nonstatic資料成員被放置於物件內。我們展開vfprt:

vfptr中有兩個指標型別的資料(地址),第一個指向了Base類的解構函式,第二個指向了Base的虛擬函式print,順序與宣告順序相同。
這與上述的C++物件模型相符合。也可以通過程式碼來進行驗證:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
void testBase( Base&p) { cout << "物件的記憶體起始地址:" << &p << endl; cout << "type_info資訊:" << endl; RTTICompleteObjectLocator str = *((RTTICompleteObjectLocator*)*((int*)*(int*)(&p) - 1)); string classname(str.pTypeDescriptor->name); classname = classname.substr(4, classname.find("@@") - 4); cout << "根據type_info資訊輸出類名:"<< classname << endl; cout << "虛擬函式表地址:" << (int *)(&p) << endl; //驗證虛表 cout << "虛擬函式表第一個函式的地址:" << (int *)*((int*)(&p)) << endl; cout << "解構函式的地址:" << (int* )*(int *)*((int*)(&p)) << endl; cout << "虛擬函式表中,第二個虛擬函式即print()的地址:" << ((int*)*(int*)(&p) + 1) << endl; //通過地址呼叫虛擬函式print() typedef void(*Fun)(void); Fun IsPrint=(Fun)* ((int*)*(int*)(&p) + 1); cout << endl; cout<<"呼叫了虛擬函式"; IsPrint(); //若地址正確,則呼叫了Base類的虛擬函式print() cout << endl; //輸入static函式的地址 p.countI();//先呼叫函式以產生一個例項 cout << "static函式countI()的地址:" << p.countI << endl; //驗證nonstatic資料成員 cout << "推測nonstatic資料成員baseI的地址:" << (int *)(&p) + 1 << endl; cout << "根據推測出的地址,輸出該地址的值:" << *((int *)(&p) + 1) << endl; cout << "Base::getI():" << p.getI() << endl; } |
|
1 2 |
Base b(1000); testBase(b); |

結果分析:
- 通過 (int *)(&p)取得虛擬函式表的地址
- type_info資訊的確存在於虛表的前一個位置。通過((int)(int*)(&p) – 1))取得type_infn資訊,併成功獲得類的名稱的Base
- 虛擬函式表的第一個函式是解構函式。
- 虛擬函式表的第二個函式是虛擬函式print(),取得地址後通過地址呼叫它(而非通過物件),驗證正確
- 虛表指標的下一個位置為nonstatic資料成員baseI。
- 可以看到,static成員函式的地址段位與虛表指標、baseI的地址段位不同。
好的,至此我們瞭解了非繼承下類物件五種資料在記憶體上的佈局,也知道了在每一個虛擬函式表前都有一個指標指向type_info,負責對RTTI的支援。而加入繼承後類物件在記憶體中該如何表示呢?
5.繼承下的C++物件模型
5.1.單繼承
如果我們定義了派生類
|
1 2 3 4 5 6 7 8 9 10 11 12 |
class Derive : public Base { public: Derive(int d) :Base(1000), DeriveI(d){}; //overwrite父類虛擬函式 virtual void print(void){ cout << "Drive::Drive_print()" ; } // Derive宣告的新的虛擬函式 virtual void Drive_print(){ cout << "Drive::Drive_print()" ; } virtual ~Derive(){} private: int DeriveI; }; |
繼承類圖為:

一個派生類如何在機器層面上塑造其父類的例項呢?在簡單物件模型中,可以在子類物件中為每個類子物件分配一個指標。如下圖:

簡單物件模型的缺點就是因間接性導致的空間存取時間上的額外負擔,優點則是類的大小是固定的,基類的改動不會影響子類物件的大小。
在表格驅動物件模型中,我們可以為子類物件增加第三個指標:基類指標(bptr),基類指標指向指向一個基類表(base class table),同樣的,由於間接性導致了空間和存取時間上的額外負擔,優點則是無須改變子類物件本身就可以更改基類。表格驅動模型的圖就不再貼出來了。
在C++物件模型中,對於一般繼承(這個一般是相對於虛擬繼承而言),若子類重寫(overwrite)了父類的虛擬函式,則子類虛擬函式將覆蓋虛表中對應的父類虛擬函式(注意子類與父類擁有各自的一個虛擬函式表);若子類並無overwrite父類虛擬函式,而是宣告瞭自己新的虛擬函式,則該虛擬函式地址將擴充到虛擬函式表最後(在vs中無法通過監視看到擴充的結果,不過我們通過取地址的方法可以做到,子類新的虛擬函式確實在父類子物體的虛擬函式表末端)。而對於虛繼承,若子類overwrite父類虛擬函式,同樣地將覆蓋父類子物體中的虛擬函式表對應位置,而若子類宣告瞭自己新的虛擬函式,則編譯器將為子類增加一個新的虛表指標vptr,這與一般繼承不同,在後面再討論。

我們使用程式碼來驗證以上模型
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
typedef void(*Fun)(void); int main() { Derive d(2000); //[0] cout << "[0]Base::vptr"; cout << "\t地址:" << (int *)(&d) << endl; //vprt[0] cout << " [0]"; Fun fun1 = (Fun)*((int *)*((int *)(&d))); fun1(); cout << "\t地址:\t" << *((int *)*((int *)(&d))) << endl; //vprt[1]解構函式無法通過地址呼叫,故手動輸出 cout << " [1]" << "Derive::~Derive" << endl; //vprt[2] cout << " [2]"; Fun fun2 = (Fun)*((int *)*((int *)(&d)) + 2); fun2(); cout << "\t地址:\t" << *((int *)*((int *)(&d)) + 2) << endl; //[1] cout << "[2]Base::baseI=" << *(int*)((int *)(&d) + 1); cout << "\t地址:" << (int *)(&d) + 1; cout << endl; //[2] cout << "[2]Derive::DeriveI=" << *(int*)((int *)(&d) + 2); cout << "\t地址:" << (int *)(&d) + 2; cout << endl; getchar(); } |
執行結果:

這個結果與我們的物件模型符合。
5.2.多繼承
5.2.1一般的多重繼承(非菱形繼承)
單繼承中(一般繼承),子類會擴充套件父類的虛擬函式表。在多繼承中,子類含有多個父類的子物件,該往哪個父類的虛擬函式表擴充套件呢?當子類overwrite了父類的函式,需要覆蓋多個父類的虛擬函式表嗎?
- 子類的虛擬函式被放在宣告的第一個基類的虛擬函式表中。
- overwrite時,所有基類的print()函式都被子類的print()函式覆蓋。
- 記憶體佈局中,父類按照其宣告順序排列。
其中第二點保證了父類指標指向子類物件時,總是能夠呼叫到真正的函式。
為了方便檢視,我們把程式碼都貼上過來
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 |
class Base { public: Base(int i) :baseI(i){}; virtual ~Base(){} int getI(){ return baseI; } static void countI(){}; virtual void print(void){ cout << "Base::print()"; } private: int baseI; static int baseS; }; class Base_2 { public: Base_2(int i) :base2I(i){}; virtual ~Base_2(){} int getI(){ return base2I; } static void countI(){}; virtual void print(void){ cout << "Base_2::print()"; } private: int base2I; static int base2S; }; class Drive_multyBase :public Base, public Base_2 { public: Drive_multyBase(int d) :Base(1000), Base_2(2000) ,Drive_multyBaseI(d){}; virtual void print(void){ cout << "Drive_multyBase::print" ; } virtual void Drive_print(){ cout << "Drive_multyBase::Drive_print" ; } private: int Drive_multyBaseI; }; |
繼承類圖為:

此時Drive_multyBase 的物件模型是這樣的:

我們使用程式碼驗證:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 |
typedef void(*Fun)(void); int main() { Drive_multyBase d(3000); //[0] cout << "[0]Base::vptr"; cout << "\t地址:" << (int *)(&d) << endl; //vprt[0]解構函式無法通過地址呼叫,故手動輸出 cout << " [0]" << "Derive::~Derive" << endl; //vprt[1] cout << " [1]"; Fun fun1 = (Fun)*((int *)*((int *)(&d))+1); fun1(); cout << "\t地址:\t" << *((int *)*((int *)(&d))+1) << endl; //vprt[2] cout << " [2]"; Fun fun2 = (Fun)*((int *)*((int *)(&d)) + 2); fun2(); cout << "\t地址:\t" << *((int *)*((int *)(&d)) + 2) << endl; //[1] cout << "[1]Base::baseI=" << *(int*)((int *)(&d) + 1); cout << "\t地址:" << (int *)(&d) + 1; cout << endl; //[2] cout << "[2]Base_::vptr"; cout << "\t地址:" << (int *)(&d)+2 << endl; //vprt[0]解構函式無法通過地址呼叫,故手動輸出 cout << " [0]" << "Drive_multyBase::~Derive" << endl; //vprt[1] cout << " [1]"; Fun fun4 = (Fun)*((int *)*((int *)(&d))+1); fun4(); cout << "\t地址:\t" << *((int *)*((int *)(&d))+1) << endl; //[3] cout << "[3]Base_2::base2I=" << *(int*)((int *)(&d) + 3); cout << "\t地址:" << (int *)(&d) + 3; cout << endl; //[4] cout << "[4]Drive_multyBase::Drive_multyBaseI=" << *(int*)((int *)(&d) + 4); cout << "\t地址:" << (int *)(&d) + 4; cout << endl; getchar(); } |
執行結果:

5.2.2 菱形繼承
菱形繼承也稱為鑽石型繼承或重複繼承,它指的是基類被某個派生類簡單重複繼承了多次。這樣,派生類物件中擁有多份基類例項(這會帶來一些問題)。為了方便敘述,我們不使用上面的程式碼了,而重新寫一個重複繼承的繼承層次:

|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 |
class B { public: int ib; public: B(int i=1) :ib(i){} virtual void f() { cout << "B::f()" << endl; } virtual void Bf() { cout << "B::Bf()" << endl; } }; class B1 : public B { public: int ib1; public: B1(int i = 100 ) :ib1(i) {} virtual void f() { cout << "B1::f()" << endl; } virtual void f1() { cout << "B1::f1()" << endl; } virtual void Bf1() { cout << "B1::Bf1()" << endl; } }; class B2 : public B { public: int ib2; public: B2(int i = 1000) :ib2(i) {} virtual void f() { cout << "B2::f()" << endl; } virtual void f2() { cout << "B2::f2()" << endl; } virtual void Bf2() { cout << "B2::Bf2()" << endl; } }; class D : public B1, public B2 { public: int id; public: D(int i= 10000) :id(i){} virtual void f() { cout << "D::f()" << endl; } virtual void f1() { cout << "D::f1()" << endl; } virtual void f2() { cout << "D::f2()" << endl; } virtual void Df() { cout << "D::Df()" << endl; } }; |
這時,根據單繼承,我們可以分析出B1,B2類繼承於B類時的記憶體佈局。又根據一般多繼承,我們可以分析出D類的記憶體佈局。我們可以得出D類子物件的記憶體佈局如下圖:

D類物件記憶體佈局中,圖中青色表示b1類子物件例項,黃色表示b2類子物件例項,灰色表示D類子物件例項。從圖中可以看到,由於D類間接繼承了B類兩次,導致D類物件中含有兩個B類的資料成員ib,一個屬於來源B1類,一個來源B2類。這樣不僅增大了空間,更重要的是引起了程式歧義:
|
1 2 3 4 5 6 7 |
D d; d.ib =1 ; //二義性錯誤,呼叫的是B1的ib還是B2的ib? d.B1::ib = 1; //正確 d.B2::ib = 1; //正確 |
儘管我們可以通過明確指明呼叫路徑以消除二義性,但二義性的潛在性還沒有消除,我們可以通過虛繼承來使D類只擁有一個ib實體。
6.虛繼承
虛繼承解決了菱形繼承中最派生類擁有多個間接父類例項的情況。虛繼承的派生類的記憶體佈局與普通繼承很多不同,主要體現在:
- 虛繼承的子類,如果本身定義了新的虛擬函式,則編譯器為其生成一個虛擬函式指標(vptr)以及一張虛擬函式表。該vptr位於物件記憶體最前面。
- vs非虛繼承:直接擴充套件父類虛擬函式表。
- 虛繼承的子類也單獨保留了父類的vprt與虛擬函式表。這部分內容接與子類內容以一個四位元組的0來分界。
- 虛繼承的子類物件中,含有四位元組的虛表指標偏移值。
為了分析最後的菱形繼承,我們還是先從單虛繼承繼承開始。
6.1.虛基類表解析
在C++物件模型中,虛繼承而來的子類會生成一個隱藏的虛基類指標(vbptr),在Microsoft Visual C++中,虛基類表指標總是在虛擬函式表指標之後,因而,對某個類例項來說,如果它有虛基類指標,那麼虛基類指標可能在例項的0位元組偏移處(該類沒有vptr時,vbptr就處於類例項記憶體佈局的最前面,否則vptr處於類例項記憶體佈局的最前面),也可能在類例項的4位元組偏移處。
一個類的虛基類指標指向的虛基類表,與虛擬函式表一樣,虛基類表也由多個條目組成,條目中存放的是偏移值。第一個條目存放虛基類表指標(vbptr)所在地址到該類記憶體首地址的偏移值,由第一段的分析我們知道,這個偏移值為0(類沒有vptr)或者-4(類有虛擬函式,此時有vptr)。我們通過一張圖來更好地理解。


虛基類表的第二、第三…個條目依次為該類的最左虛繼承父類、次左虛繼承父類…的記憶體地址相對於虛基類表指標的偏移值,這點我們在下面會驗證。
6.2.簡單虛繼承
如果我們的B1類虛繼承於B類:
|
1 2 3 |
//類的內容與前面相同 class B{...} class B1 : virtual public B |

根據我們前面對虛繼承的派生類的記憶體佈局的分析,B1類的物件模型應該是這樣的:

我們通過指標訪問B1類物件的記憶體,以驗證上面的C++物件模型:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 |
int main() { B1 a; cout <<"B1物件記憶體大小為:"<< sizeof(a) << endl; //取得B1的虛擬函式表 cout << "[0]B1::vptr"; cout << "\t地址:" << (int *)(&a)<< endl; //輸出虛表B1::vptr中的函式 for (int i = 0; i<2;++ i) { cout << " [" << i << "]"; Fun fun1 = (Fun)*((int *)*(int *)(&a) + i); fun1(); cout << "\t地址:\t" << *((int *)*(int *)(&a) + i) << endl; } //[1] cout << "[1]vbptr " ; cout<<"\t地址:" << (int *)(&a) + 1<<endl; //虛表指標的地址 //輸出虛基類指標條目所指的內容 for (int i = 0; i < 2; i++) { cout << " [" << i << "]"; cout << *(int *)((int *)*((int *)(&a) + 1) + i); cout << endl; } //[2] cout << "[2]B1::ib1=" << *(int*)((int *)(&a) + 2); cout << "\t地址:" << (int *)(&a) + 2; cout << endl; //[3] cout << "[3]值=" << *(int*)((int *)(&a) + 3); cout << "\t\t地址:" << (int *)(&a) + 3; cout << endl; //[4] cout << "[4]B::vptr"; cout << "\t地址:" << (int *)(&a) +3<< endl; //輸出B::vptr中的虛擬函式 for (int i = 0; i<2; ++i) { cout << " [" << i << "]"; Fun fun1 = (Fun)*((int *)*((int *)(&a) + 4) + i); fun1(); cout << "\t地址:\t" << *((int *)*((int *)(&a) + 4) + i) << endl; } //[5] cout << "[5]B::ib=" << *(int*)((int *)(&a) + 5); cout << "\t地址: " << (int *)(&a) + 5; cout << endl; |
執行結果:

這個結果與我們的C++物件模型圖完全符合。這時我們可以來分析一下虛表指標的第二個條目值12的具體來源了,回憶上文講到的:
第二、第三…個條目依次為該類的最左虛繼承父類、次左虛繼承父類…的記憶體地址相對於虛基類表指標的偏移值。
在我們的例子中,也就是B類例項記憶體地址相對於vbptr的偏移值,也即是:[4]-[1]的偏移值,結果即為12,從地址上也可以計算出來:007CFDFC-007CFDF4結果的十進位制數正是12。現在,我們對虛基類表的構成應該有了一個更好的理解。
6.3.虛擬菱形繼承
如果我們有如下繼承層次:
|
1 2 3 4 |
class B{...} class B1: virtual public B{...} class B2: virtual public B{...} class D : public B1,public B2{...} |
類圖如下所示:

菱形虛擬繼承下,最派生類D類的物件模型又有不同的構成了。在D類物件的記憶體構成上,有以下幾點:
- 在D類物件記憶體中,基類出現的順序是:先是B1(最左父類),然後是B2(次左父類),最後是B(虛祖父類)
- D類物件的資料成員id放在B類前面,兩部分資料依舊以0來分隔。
- 編譯器沒有為D類生成一個它自己的vptr,而是覆蓋並擴充套件了最左父類的虛基類表,與簡單繼承的物件模型相同。
- 超類B的內容放到了D類物件記憶體佈局的最後。
菱形虛擬繼承下的C++物件模型為:

下面使用程式碼加以驗證:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 |
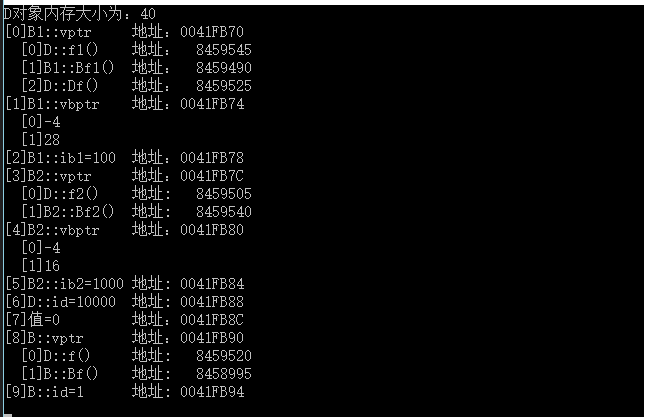
int main() { D d; cout << "D物件記憶體大小為:" << sizeof(d) << endl; //取得B1的虛擬函式表 cout << "[0]B1::vptr"; cout << "\t地址:" << (int *)(&d) << endl; //輸出虛表B1::vptr中的函式 for (int i = 0; i<3; ++i) { cout << " [" << i << "]"; Fun fun1 = (Fun)*((int *)*(int *)(&d) + i); fun1(); cout << "\t地址:\t" << *((int *)*(int *)(&d) + i) << endl; } //[1] cout << "[1]B1::vbptr "; cout << "\t地址:" << (int *)(&d) + 1 << endl; //虛表指標的地址 //輸出虛基類指標條目所指的內容 for (int i = 0; i < 2; i++) { cout << " [" << i << "]"; cout << *(int *)((int *)*((int *)(&d) + 1) + i); cout << endl; } //[2] cout << "[2]B1::ib1=" << *(int*)((int *)(&d) + 2); cout << "\t地址:" << (int *)(&d) + 2; cout << endl; //[3] cout << "[3]B2::vptr"; cout << "\t地址:" << (int *)(&d) + 3 << endl; //輸出B2::vptr中的虛擬函式 for (int i = 0; i<2; ++i) { cout << " [" << i << "]"; Fun fun1 = (Fun)*((int *)*((int *)(&d) + 3) + i); fun1(); cout << "\t地址:\t" << *((int *)*((int *)(&d) + 3) + i) << endl; } //[4] cout << "[4]B2::vbptr "; cout << "\t地址:" << (int *)(&d) + 4 << endl; //虛表指標的地址 //輸出虛基類指標條目所指的內容 for (int i = 0; i < 2; i++) { cout << " [" << i << "]"; cout << *(int *)((int *)*((int *)(&d) + 4) + i); cout << endl; } //[5] cout << "[5]B2::ib2=" << *(int*)((int *)(&d) + 5); cout << "\t地址: " << (int *)(&d) + 5; cout << endl; //[6] cout << "[6]D::id=" << *(int*)((int *)(&d) + 6); cout << "\t地址: " << (int *)(&d) + 6; cout << endl; //[7] cout << "[7]值=" << *(int*)((int *)(&d) + 7); cout << "\t\t地址:" << (int *)(&d) + 7; cout << endl; //間接父類 //[8] cout << "[8]B::vptr"; cout << "\t地址:" << (int *)(&d) + 8 << endl; //輸出B::vptr中的虛擬函式 for (int i = 0; i<2; ++i) { cout << " [" << i << "]"; Fun fun1 = (Fun)*((int *)*((int *)(&d) + 8) + i); fun1(); cout << "\t地址:\t" << *((int *)*((int *)(&d) + 8) + i) << endl; } //[9] cout << "[9]B::id=" << *(int*)((int *)(&d) + 9); cout << "\t地址: " << (int *)(&d) +9; cout << endl; getchar(); } |
檢視執行結果:
7.一些問題解答
7.1.C++封裝帶來的佈局成本是多大?
在C語言中,“資料”和“處理資料的操作(函式)”是分開來宣告的,也就是說,語言本身並沒有支援“資料和函式”之間的關聯性。
在C++中,我們通過類來將屬性與操作繫結在一起,稱為ADT,抽象資料結構。
C語言中使用struct(結構體)來封裝資料,使用函式來處理資料。舉個例子,如果我們定義了一個struct Point3如下:
|
1 2 3 4 5 6 |
typedef struct Point3 { float x; float y; float z; } Point3; |
為了列印這個Point3d,我們可以定義一個函式:
|
1 2 3 4 |
void Point3d_print(const Point3d *pd) { printf("(%f,%f,%f)",pd->x,pd->y,pd_z); } |
而在C++中,我們更傾向於定義一個Point3d類,以ADT來實現上面的操作:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
class Point3d { public: point3d (float x = 0.0,float y = 0.0,float z = 0.0) : _x(x), _y(y), _z(z){} float x() const {return _x;} float y() const {return _y;} float z() const {return _z;} private: float _x; float _y; float _z; }; inline ostream& operator<<(ostream &os, const Point3d &pt) { os<<"("<<pr.x()<<"," <<pt.y()<<","<<pt.z()<<")"; } |
看到這段程式碼,很多人第一個疑問可能是:加上了封裝,佈局成本增加了多少?答案是class Point3d並沒有增加成本。學過了C++物件模型,我們知道,Point3d類物件的記憶體中,只有三個資料成員。
上面的類宣告中,三個資料成員直接內含在每一個Point3d物件中,而成員函式雖然在類中宣告,卻不出現在類物件(object)之中,這些函式(non-inline)屬於類而不屬於類物件,只會為類產生唯一的函式例項。
所以,Point3d的封裝並沒有帶來任何空間或執行期的效率影響。而在下面這種情況下,C++的封裝額外成本才會顯示出來:
- 虛擬函式機制(virtual function) , 用以支援執行期繫結,實現多型。
- 虛基類 (virtual base class) ,虛繼承關係產生虛基類,用於在多重繼承下保證基類在子類中擁有唯一例項。
不僅如此,Point3d類資料成員的記憶體佈局與c語言的結構體Point3d成員記憶體佈局是相同的。C++中處在同一個訪問識別符號(指public、private、protected)下的宣告的資料成員,在記憶體中必定保證以其宣告順序出現。而處於不同訪問識別符號宣告下的成員則無此規定。對於Point3類來說,它的三個資料成員都處於private下,在記憶體中一起宣告順序出現。我們可以做下實驗:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
void TestPoint3Member(const Point3d& p) { cout << "推測_x的地址是:" << (float *) (&p) << endl; cout << "推測_y的地址是:" << (float *) (&p) + 1 << endl; cout << "推測_z的地址是:" << (float *) (&p) + 2 << endl; cout << "根據推測出的地址輸出_x的值:" << *((float *)(&p)) << endl; cout << "根據推測出的地址輸出_y的值:" << *((float *)(&p)+1) << endl; cout << "根據推測出的地址輸出_z的值:" << *((float *)(&p)+2) << endl; } |
|
1 2 3 |
//測試程式碼 Point3d a(1,2,3); TestPoint3Member(a); |
執行結果:

從結果可以看到,_x,_y,_z三個資料成員在記憶體中緊挨著。
總結一下:
不考慮虛擬函式與虛繼承,當資料都在同一個訪問識別符號下,C++的類與C語言的結構體在物件大小和記憶體佈局上是一致的,C++的封裝並沒有帶來空間時間上的影響。
7.2.下面這個空類構成的繼承層次中,每個類的大小是多少?
今有類如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
class B{}; class B1 :public virtual B{}; class B2 :public virtual B{}; class D : public B1, public B2{}; int main() { B b; B1 b1; B2 b2; D d; cout << "sizeof(b)=" << sizeof(b)<<endl; cout << "sizeof(b1)=" << sizeof(b1) << endl; cout << "sizeof(b2)=" << sizeof(b2) << endl; cout << "sizeof(d)=" << sizeof(d) << endl; getchar(); } |
輸出結果是:

解析:
- 編譯器為空類安插1位元組的char,以使該類物件在記憶體得以配置一個地址。
- b1虛繼承於b,編譯器為其安插一個4位元組的虛基類表指標(32為機器),此時b1已不為空,編譯器不再為其安插1位元組的char(優化)。
- b2同理。
- d含有來自b1與b2兩個父類的兩個虛基類表指標。大小為8位元組。
打賞支援我寫出更多好文章,謝謝!
打賞作者
打賞支援我寫出更多好文章,謝謝!
任選一種支付方式

