前言
隨機森林非常像《機器學習實踐》裡面提到過的那個AdaBoost演算法,但區別在於它沒有迭代,還有就是森林裡的樹長度不限制。
因為它是沒有迭代過程的,不像AdaBoost那樣需要迭代,不斷更新每個樣本以及子分類器的權重。因此模型相對簡單點,不容易出現過擬合。
下面先來講講它的具體框架流程。
框架流程

隨機森林可以理解為Cart樹森林,它是由多個Cart樹分類器構成的整合學習模式。其中每個Cart樹可以理解為一個議員,它從樣本集裡面隨機有放回的抽取一部分進行訓練,這樣,多個樹分類器就構成了一個訓練模型矩陣,可以理解為形成了一個議會吧。
然後將要分類的樣本帶入這一個個樹分類器,然後以少數服從多數的原則,表決出這個樣本的最終分類型別。
設有N個樣本,M個變數(維度)個數,該演算法具體流程如下:
1. 確定一個值m,它用來表示每個樹分類器選取多少個變數。(注意這也是隨機的體現之一)
2. 從資料集中有放回的抽取 k 個樣本集,用它們建立 k 個樹分類器。另外還伴隨生成了 k 個袋外資料,用來後面做檢測。
3. 輸入待分類樣本之後,每個樹分類器都會對它進行分類,然後所有分類器按照少數服從多數原則,確定分類結果。
效能制約
1. 森林中的每個樹越茂盛,分類效果就越好。
2. 樹和樹的枝葉穿插越多,分類效果就越差。
重要引數
1. 預選變數個數 (即框架流程中的m);
2. 隨機森林中樹的個數。
這兩個引數的調優非常關鍵,尤其是在做分類或迴歸的時候。
構建隨機森林模型
函式名:randomForest(......);
函式重要引數說明:
- x,y引數自然是特徵矩陣和標籤向量;
- na.action:是否忽略有缺失值的樣本;
- ntree:樹分類器的個數。500-1000為佳;
- mtry:分枝的變數選擇數;
- importance:是否計算各個變數在模型中的重要性(後面會提到)。
構建好模型之後,帶入predict函式和待預測資料集就可得出預測結果。然而,R語言中對隨機森林這個機制的支援遠遠不止簡單的做分類這麼簡單。它還提供以下這幾個功能,在使用這些功能之前,都要先呼叫randomForest函式架構出模型。
使用隨機森林進行變數篩選
之前的文章提到過使用主成分分析法PCA,以及因子分析EFA,但是這兩種方法都有各自的缺點。它們都是屬於變數組合技術,會形成新的變數,之後一般還需要一個解釋的階段。
對於一些解釋起來比較麻煩,以及情況不是很複雜的情況,直接使用隨機森林進行特徵選擇就可以了,下面為具體步驟:

執行這個指令碼後:
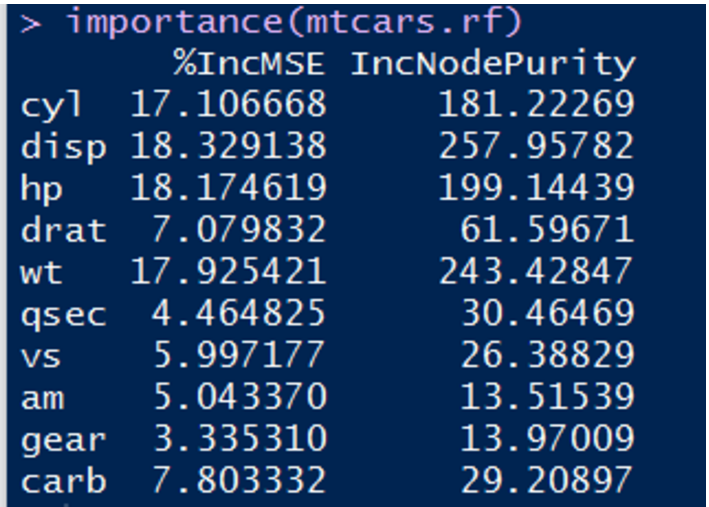
其中的兩列是衡量變數重要性的指標,越高表示該變數對分類的影響越大。第一列是根據精度平均減少值作為標準度量,而第二列則是採用節點不純度的平均減少值作為度量標準。
重要度的計量方法參考下圖(摘自百度文庫):

使用隨機森林繪製MDS二維圖
通過MDS圖我們能大致看出哪些類是比較容易搞混的:

生成下圖:
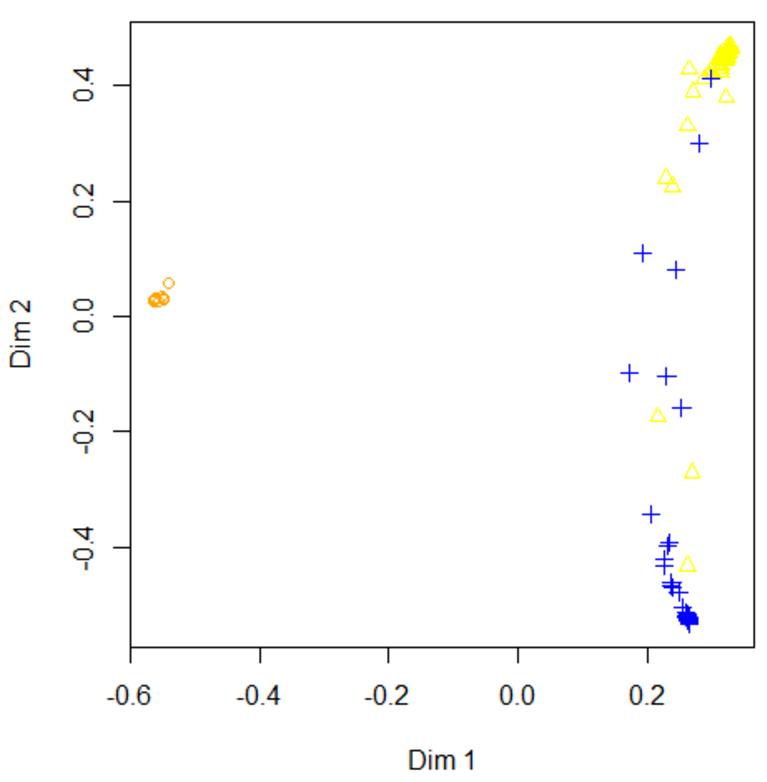
可以看出,第二列第三列存在著容易混淆的情況。
小結
R語言包中提供的隨機森林功能包還有很多,對於調優很有幫助,請務必查詢相關資料並掌握。
另外,部分變種的隨機森林演算法還可以用來做迴歸。