前言
在對資料有了大致的瞭解以後,就需要對獲取到的資料進行一個預處理了。預處理的過程並不簡單,大致來說分成缺失值處理,異常值處理,資料歸約等等 (可根據實際情況對這些階段進行科學的取捨)。
下面將對這幾個階段一個個講解。(本文中測試資料集nhanes2來自包lattice)
缺失值處理
1. 首先要了解到資料集的缺失情況。
下面兩行命令分別獲取到缺失的欄位數和完整樣本數:

顯然缺失欄位個數為27,完整樣本數為13。
2. 使用mice包的md.pattern函式來獲取具體的缺失情況:

第一行第一列表示完整樣本數(缺失/非缺失欄位描述參考2-4列,1表示沒缺失,0表示缺失);最後一列表示該種描述中缺失的欄位數。
第二行至第五行情況類似。
最後一行中,2-4列表示對應的欄位缺失數,最後一列表示總的欄位缺失數。
3. 缺失值的處理:
a) 刪除法

b) 插補法(均值插補為例)
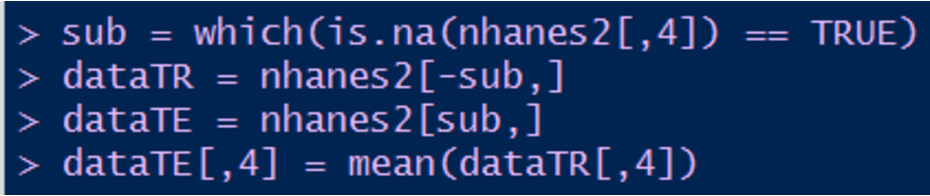
上述程式碼首先將資料分為有缺失欄位樣本集和無缺失欄位樣本集,然後將有缺失欄位的樣本集的第四個欄位進行均值補全。其他欄位的補全同理。
小結
R語言中提供的缺失值處理方案遠不止於此。
在何種條件下選擇何種插補策略是個很有挑戰的問題,本文不展開探討。