前言
MovieLens資料集包含多個使用者對多部電影的評級資料,也包括電影後設資料資訊和使用者屬性資訊。
這個資料集經常用來做推薦系統,機器學習演算法的測試資料集。尤其在推薦系統領域,很多著名論文都是基於這個資料集的。(PS: 它是某次具有歷史意義的推薦系統競賽所用的資料集)。
下載地址為:http://files.grouplens.org/datasets/movielens/,有好幾種版本,對應不同資料量,可任君選用。
本文下載資料量最小的100k版本,對該資料集進行探索:

環境
本人機器所用的作業系統為號稱國產作業系統的Ubuntu Kylin 14.04,美化後的介面還是蠻酷炫的:
spark版本為:v1.5.2,下面是整合了Ipython,pylab的python-shell:

初步預覽
1. 首先是使用者資訊:
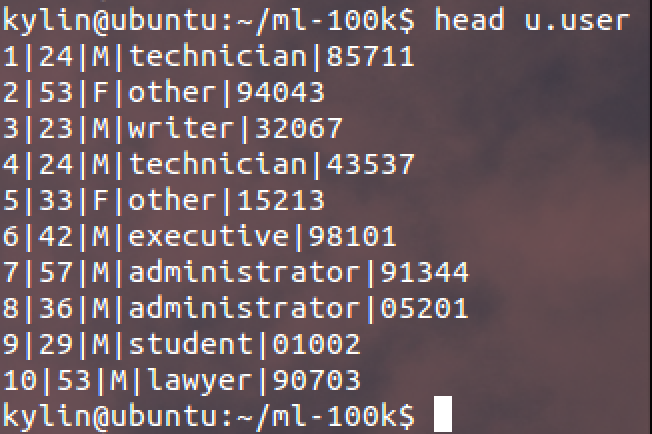
其中各列資料分別為:
使用者id | 使用者年齡 | 使用者性別 | 使用者職業 | 使用者郵政編碼
2. 然後是影片資訊:

其中前幾列資料分別為:
影片id | 影片名 | 影片發行日期 | 影片連結 | (後面幾列先不去管)
3. 最後是評分資料:
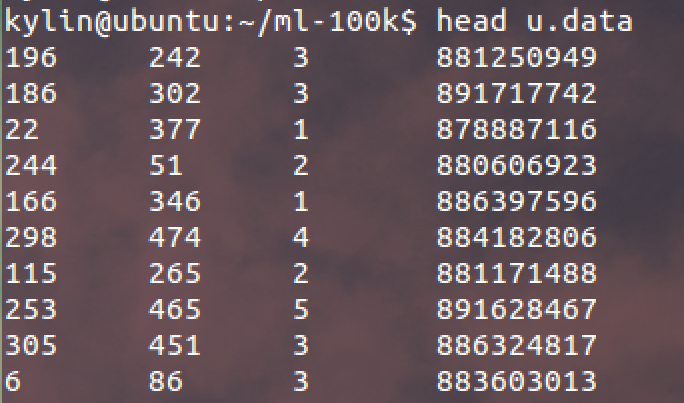
使用者id | 影片id | 評分值 | 時間戳(timestamp格式)
探索使用者資料
1. 開啟Spark的python-shell,執行以下程式碼載入資料集並列印首行記錄:
1 # 載入資料集 2 user_data = sc.textFile("/home/kylin/ml-100k/u.user") 3 # 展示首行記錄 4 user_data.first()
結果如下:

2. 分別統計使用者,性別,職業的個數:
1 # 以' | '切分每列,返回新的使用者RDD 2 user_fields = user_data.map(lambda line: line.split("|")) 3 # 統計使用者數 4 num_users = user_fields.map(lambda fields: fields[0]).count() 5 # 統計性別數 6 num_genders = user_fields.map(lambda fields: fields[2]).distinct().count() 7 # 統計職業數 8 num_occupations = user_fields.map(lambda fields: fields[3]).distinct().count() 9 # 統計郵編數 10 num_zipcodes = user_fields.map(lambda fields: fields[4]).distinct().count() 11 # 返回結果 12 print "使用者數: %d, 性別數: %d, 職業數: %d, 郵編數: %d" % (num_users, num_genders, num_occupations, num_zipcodes)
結果如下:

3. 檢視年齡分佈情況:
1 # 獲取使用者年齡RDD,並將其落地到驅動程式 2 ages = user_fields.map(lambda x: int(x[1])).collect() 3 # 繪製使用者年齡直方圖 4 hist(ages, bins=20, color='lightblue', normed=True)
結果如下:
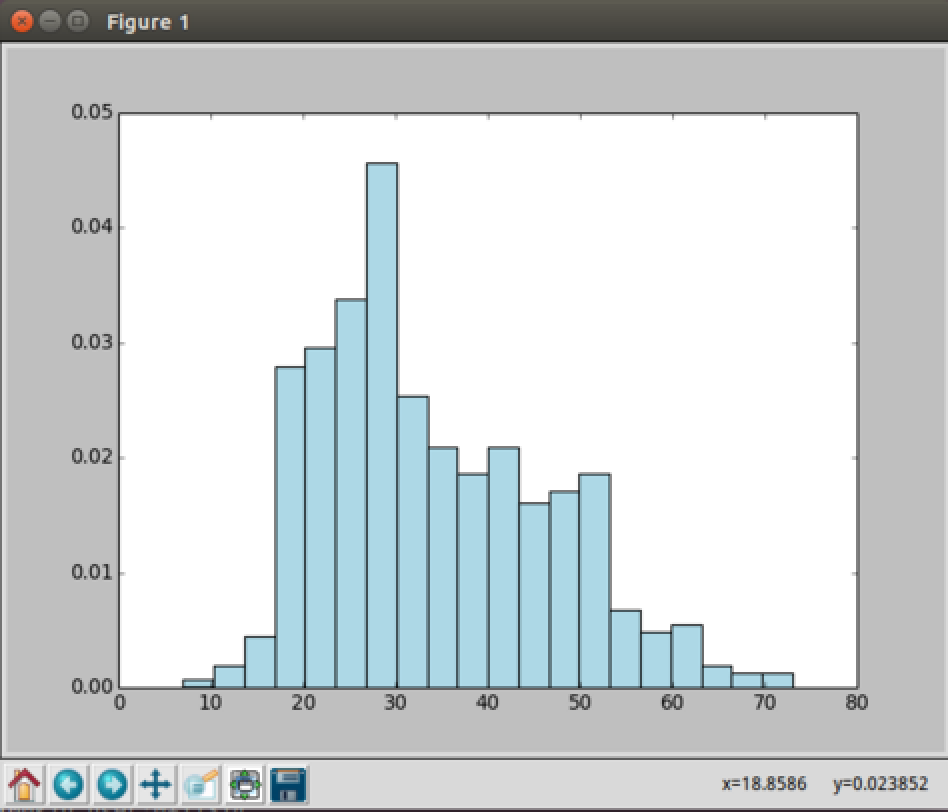
18歲以上觀看者人數激增,估計是“高考”完了時間多了?
20多歲的年輕人,我猜主要是大學生和剛工作不久的年輕人?觀看者最多。
然後50歲的觀看者也蠻多的,估計是快退休了,開始享受生活了。
4. 檢視職業分佈情況:
1 # 並行統計各職業人數的個數,返回職業統計RDD後落地 2 count_by_occupation = user_fields.map(lambda fields: (fields[3], 1)).reduceByKey(lambda x, y: x + y).collect() 3 4 # 生成x/y座標軸 5 x_axis1 = np.array([c[0] for c in count_by_occupation]) 6 y_axis1 = np.array([c[1] for c in count_by_occupation]) 7 x_axis = x_axis1[np.argsort(y_axis1)] 8 y_axis = y_axis1[np.argsort(y_axis1)] 9 10 # 生成x軸標籤 11 pos = np.arange(len(x_axis)) 12 width = 1.0 13 ax = plt.axes() 14 ax.set_xticks(pos + (width / 2)) 15 ax.set_xticklabels(x_axis) 16 17 # 繪製職業人數條狀圖 18 plt.xticks(rotation=30) 19 plt.bar(pos, y_axis, width, color='lightblue')
值得注意的是,統計各職業人數的時候,是將不同職業名記錄蒐集到不同節點,然後開始並行統計。
結果如下:
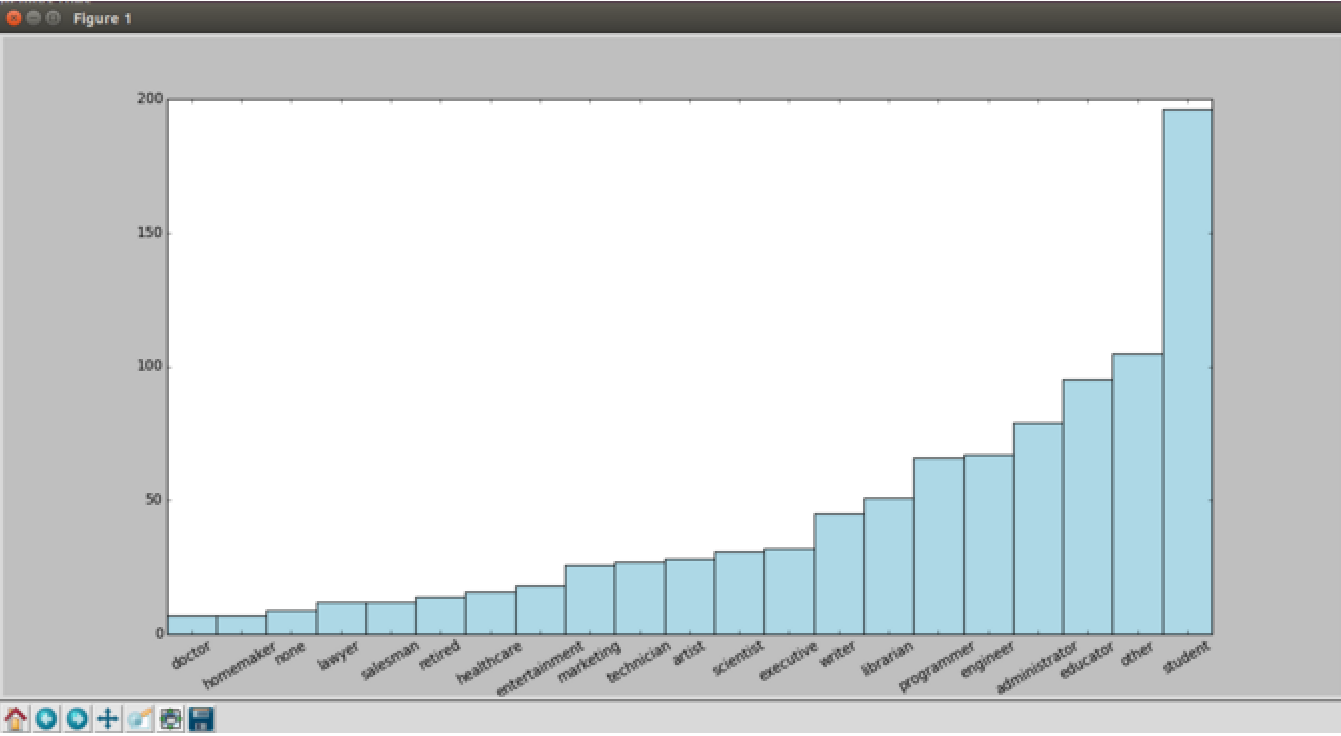
果然,是學生,教育工作者觀看影片的多。
不過程式猿觀眾也不少...... 醫生是最少看電影的。
這裡再給出一種統計各職業人數的解決方案:
1 count_by_occupation2 = user_fields.map(lambda fields: fields[3]).countByValue()
countByValue是Spark提供的便捷函式,它會自動統計每個Key下面的Value個數,並以字典的格式返回。
探索電影資料
1. 開啟Spark的python-shell,執行以下程式碼載入資料集並列印首行記錄:
1 # 載入資料集 2 movie_data = sc.textFile("/home/kylin/ml-100k/u.item") 3 # 展示首行記錄 4 print movie_data.first()
結果如下:

2. 檢視下有多少部電影吧:
1 num_movies = movie_data.count() 2 print num_movies
結果為:
3. 過濾掉沒有發行時間資訊的記錄:
1 # 輸入影片的發行時間欄位,若非法則返回1900 2 def convert_year(x): 3 try: 4 return int(x[-4:]) 5 except: 6 return 1900 7 8 # 以' | '切分每列,返回影片RDD 9 movie_fields = movie_data.map(lambda lines: lines.split("|")) 10 # 生成新的影片發行年份RDD,並將空/異常的年份置為1900, 11 years = movie_fields.map(lambda fields: fields[2]).map(lambda x: convert_year(x)) 12 # 過濾掉影片發行年份RDD中空/異常的記錄 13 years_filtered = years.filter(lambda x: x != 1900)
4. 統計影片的年齡分佈:
1 # 生成影片年齡RDD,然後統計不同年齡的影片數並落地 2 movie_ages = years_filtered.map(lambda yr: 1998-yr).countByValue() 3 # 獲得影片數 4 values = movie_ages.values() 5 # 獲得年齡 6 bins = movie_ages.keys() 7 # 繪製電影年齡分佈圖 8 hist(values, bins=bins, color='lightblue', normed=True)
因為這份資料集比較老,1998年提供的,所以就按當時的年齡來統計吧。另外這次使用了countByValue來統計個數,而它是執行函式,不需要再collect了。
結果為:
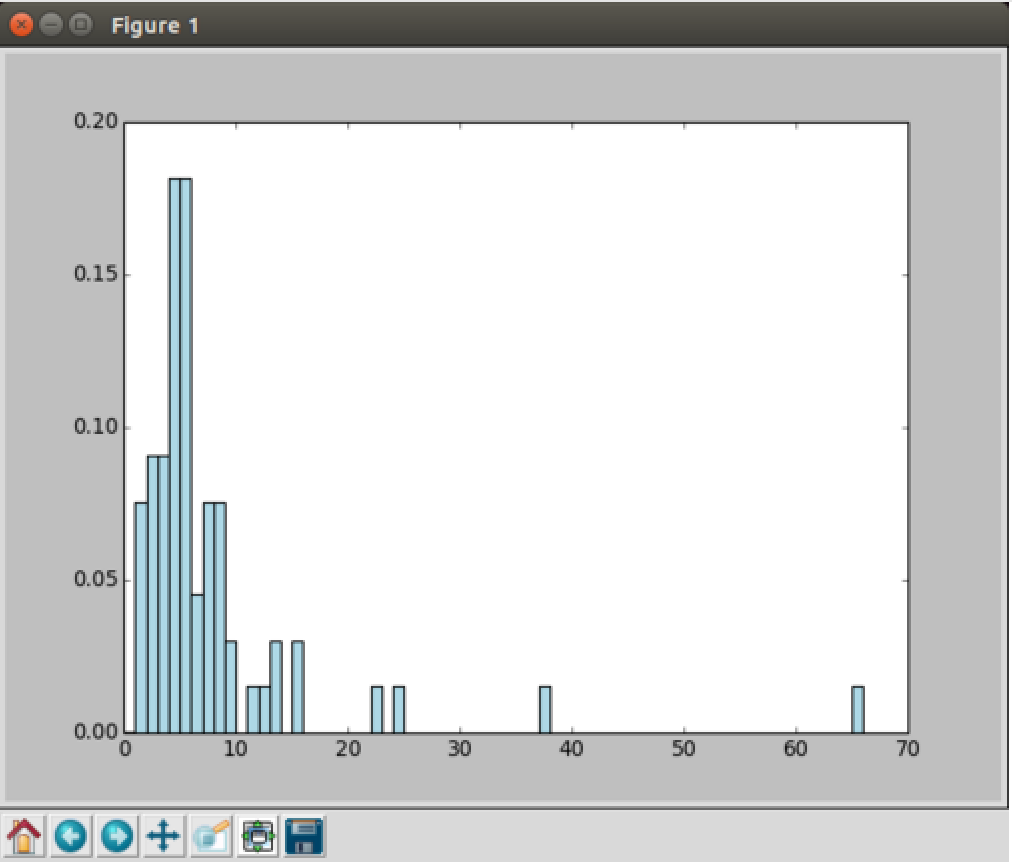
看得出電影庫中的電影大都還是比較新的。
探索評級資料
1. 開啟Spark的python-shell,執行以下程式碼載入資料集並列印首行記錄:
1 # 載入資料集 2 rating_data_raw = sc.textFile("/home/kylin/ml-100k/u.data") 3 # 展示首行記錄 4 print rating_data_raw.first()
結果為:

2. 先看看有多少評分記錄吧:
1 num_ratings = rating_data .count() 2 print num_ratings
結果為: 。果然共有10萬條記錄,沒下載錯版本。
。果然共有10萬條記錄,沒下載錯版本。
3. 統計最高評分,最低評分,平均評分,中位評分,平均每個使用者的評分次數,平均每部影片被評分次數:
1 # 獲取評分RDD 2 rating_data = rating_data_raw.map(lambda line: line.split("\t")) 3 ratings = rating_data.map(lambda fields: int(fields[2])) 4 # 計算最大/最小評分 5 max_rating = ratings.reduce(lambda x, y: max(x, y)) 6 min_rating = ratings.reduce(lambda x, y: min(x, y)) 7 # 計算平均/中位評分 8 mean_rating = ratings.reduce(lambda x, y: x + y) / float(num_ratings) 9 median_rating = np.median(ratings.collect()) 10 # 計算每個觀眾/每部電影平均打分/被打分次數 11 ratings_per_user = num_ratings / num_users 12 ratings_per_movie = num_ratings / num_movies 13 # 輸出結果 14 print "最低評分: %d" % min_rating 15 print "最高評分: %d" % max_rating 16 print "平均評分: %2.2f" % mean_rating 17 print "中位評分: %d" % median_rating 18 print "平均每個使用者打分(次數): %2.2f" % ratings_per_user 19 print "平均每部電影評分(次數): %2.2f" % ratings_per_movie
結果為:
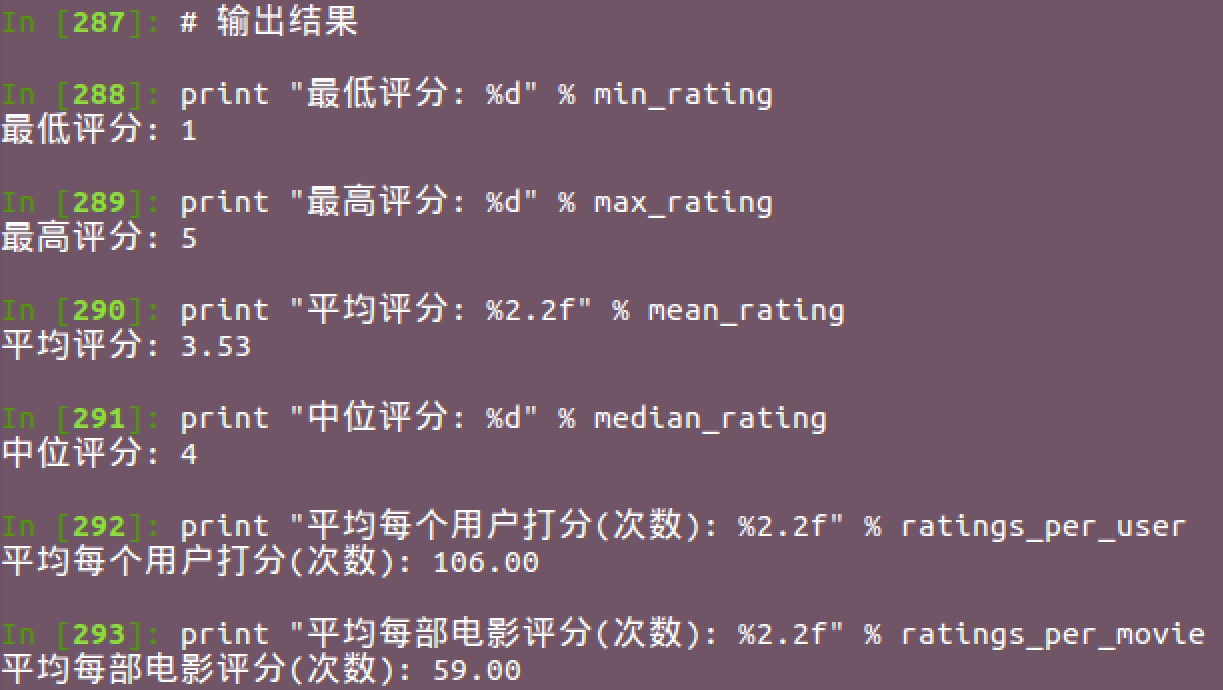
另外Spark有個挺實用的統計函式stats可直接獲取常用的統計資訊,類似R語言的summary函式:
ratings.stats()
結果為:

4. 統計評分分佈:
1 # 生成評分統計RDD,並落地 2 count_by_rating = ratings.countByValue() 3 # 生成x/y座標軸 4 x_axis = np.array(count_by_rating.keys()) 5 y_axis = np.array([float(c) for c in count_by_rating.values()]) 6 # 對人數做標準化 7 y_axis_normed = y_axis / y_axis.sum() 8 9 # 生成x軸標籤 10 pos = np.arange(len(x_axis)) 11 width = 1.0 12 ax = plt.axes() 13 ax.set_xticks(pos + (width / 2)) 14 ax.set_xticklabels(x_axis) 15 16 # 繪製評分分佈柱狀圖 17 plt.bar(pos, y_axis_normed, width, color='lightblue') 18 plt.xticks(rotation=30)
結果為:

評分分佈看來也應該挺滿足正態分佈的。
5. 統計不同使用者的評分次數:
1 # 首先將資料以使用者id為Key分發到各個節點 2 user_ratings_grouped = rating_data.map(lambda fields: (int(fields[0]), int(fields[2]))).groupByKey() 3 # 然後統計每個節點元素的個數,也即每個使用者的評論次數 4 user_ratings_byuser = user_ratings_grouped.map(lambda (k, v): (k, len(v))) 5 # 輸出前5條記錄 6 user_ratings_byuser.take(5)
注意到這次使用了groupyByKey方法,這個方法和reduceByKey功能有點相似,但是有區別。請讀者自行百度。
結果為:
