前言
在MapReduce程式中,待處理的資料最開始是放在HDFS上的,這點無異議。
接下來,資料被會被送往一個個Map節點中去,這也無異議。
下面問題來了:資料在被Map節點處理完後,再何去何從呢?
這就是本文探討的話題。
Shuffle
在Map進行完計算後,將會讓資料經過一個名為Shuffle的過程交給Reduce節點;
然後Reduce節點在收到了資料並完成了自己的計算後,會將結果輸出到Hdfs。
那麼,什麼是Shuffle階段,它具體做什麼事情?
需要知道,這可是Hadoop最為核心的所在,也是號稱“奇蹟出現的地方“ = =#
Shuffle具體分析
首先,給出官方對於Shuffle流程的示意圖:
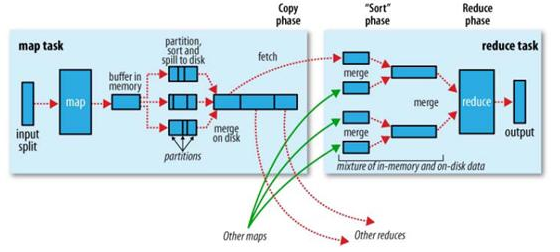
Shuffle過程植入於Map端和Reduce端兩邊
1. Map端工作:
a. 分割槽:根據鍵值對的Key值,選定鍵值對所屬的Partition區間(與Reduce節點對應)。
b. 排序:對各分割槽內的鍵值對根據鍵進行排序。
c. 分割:Map端的結果先是存放在緩衝區內的,如果超出,自然就要執行分割的處理,將一部分資料發往硬碟。
d. 合併:對於要傳送往同一個節點的鍵值對,我們需要對它進行合併。(這一步很可能針對硬碟,對於海量資料處理,緩衝區溢位是很正常的事情)
2. Reduce端工作:
a. Copy:以HTTP的方式從指定的Map端拉資料,注意是Map端的本地磁碟。
b. 合併:一個Reduce節點有可能從多個Map節點獲取資料,獲取到之後
c. 排序:對各分割槽內的鍵值對根據鍵進行排序。和Map端操作一樣。
小結
對於這部分的內容,以後有機會做Hadoop效能方面的工作時,會繼續學習研究。