需求
計算出檔案中每個單詞的頻數。要求輸出結果按照單詞的字母順序進行排序。每個單詞和其頻數佔一行,單詞和頻數之間有間隔。
比如,輸入兩個檔案,其一內容如下:
hello world
hello hadoop
hello mapreduce
另一內容如下:
bye world
bye hadoop
bye mapreduce
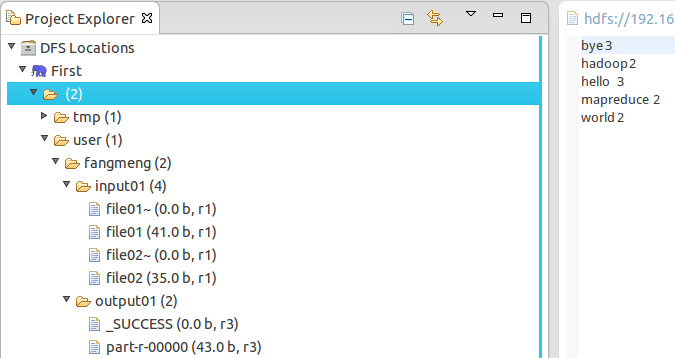
對應上面給出的輸入樣例,其輸出樣例為:
bye 3
hadoop 2
hello 3
mapreduce 2
world 2
方案制定
對該案例,可設計出如下的MapReduce方案:
1. Map階段各節點完成由輸入資料到單詞切分再到單詞蒐集的工作
2. shuffle階段完成相同單詞的聚集再到分發到各個Reduce節點的工作 (shuffle階段是MapReduce的預設過程)
3. Reduce階段負責接收所有單詞並計算各自頻數
程式碼示例
1 /** 2 * Licensed under the Apache License, Version 2.0 (the "License"); 3 * you may not use this file except in compliance with the License. 4 * You may obtain a copy of the License at 5 * 6 * http://www.apache.org/licenses/LICENSE-2.0 7 * 8 * Unless required by applicable law or agreed to in writing, software 9 * distributed under the License is distributed on an "AS IS" BASIS, 10 * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. 11 * See the License for the specific language governing permissions and 12 * limitations under the License. 13 */ 14 15 16 package org.apache.hadoop.examples; 17 18 import java.io.IOException; 19 import java.util.StringTokenizer; 20 21 //匯入各種Hadoop包 22 import org.apache.hadoop.conf.Configuration; 23 import org.apache.hadoop.fs.Path; 24 import org.apache.hadoop.io.IntWritable; 25 import org.apache.hadoop.io.Text; 26 import org.apache.hadoop.mapreduce.Job; 27 import org.apache.hadoop.mapreduce.Mapper; 28 import org.apache.hadoop.mapreduce.Reducer; 29 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 30 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 31 import org.apache.hadoop.util.GenericOptionsParser; 32 33 // 主類 34 public class WordCount { 35 36 // Mapper類 37 public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>{ 38 39 // new一個值為1的整數物件 40 private final static IntWritable one = new IntWritable(1); 41 // new一個空的Text物件 42 private Text word = new Text(); 43 44 // 實現map函式 45 public void map(Object key, Text value, Context context) throws IOException, InterruptedException { 46 47 // 建立value的字串迭代器 48 StringTokenizer itr = new StringTokenizer(value.toString()); 49 50 // 對資料進行再次分割並輸出map結果。初始格式為<位元組偏移量,單詞> 目標格式為<單詞,頻率> 51 while (itr.hasMoreTokens()) { 52 word.set(itr.nextToken()); 53 context.write(word, one); 54 } 55 } 56 } 57 58 // Reducer類 59 public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable> { 60 61 // new一個值為空的整數物件 62 private IntWritable result = new IntWritable(); 63 64 // 實現reduce函式 65 public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { 66 67 int sum = 0; 68 for (IntWritable val : values) { 69 sum += val.get(); 70 } 71 72 // 得到本次計算的單詞的頻數 73 result.set(sum); 74 75 // 輸出reduce結果 76 context.write(key, result); 77 } 78 } 79 80 // 主函式 81 public static void main(String[] args) throws Exception { 82 83 // 獲取配置引數 84 Configuration conf = new Configuration(); 85 String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs(); 86 87 // 檢查命令語法 88 if (otherArgs.length != 2) { 89 System.err.println("Usage: wordcount <in> <out>"); 90 System.exit(2); 91 } 92 93 // 定義作業物件 94 Job job = new Job(conf, "word count"); 95 // 註冊分散式類 96 job.setJarByClass(WordCount.class); 97 // 註冊Mapper類 98 job.setMapperClass(TokenizerMapper.class); 99 // 註冊合併類 100 job.setCombinerClass(IntSumReducer.class); 101 // 註冊Reducer類 102 job.setReducerClass(IntSumReducer.class); 103 // 註冊輸出格式類 104 job.setOutputKeyClass(Text.class); 105 job.setOutputValueClass(IntWritable.class); 106 // 設定輸入輸出路徑 107 FileInputFormat.addInputPath(job, new Path(otherArgs[0])); 108 FileOutputFormat.setOutputPath(job, new Path(otherArgs[1])); 109 110 // 執行程式 111 System.exit(job.waitForCompletion(true) ? 0 : 1); 112 } 113 }
執行方法
1. 開啟Eclipse並啟動Hdfs(方法請參考前文)
2. 新建一個MapReduce工程:”file" -> "new" -> "project",然後選擇 "Map/Reduce Project"
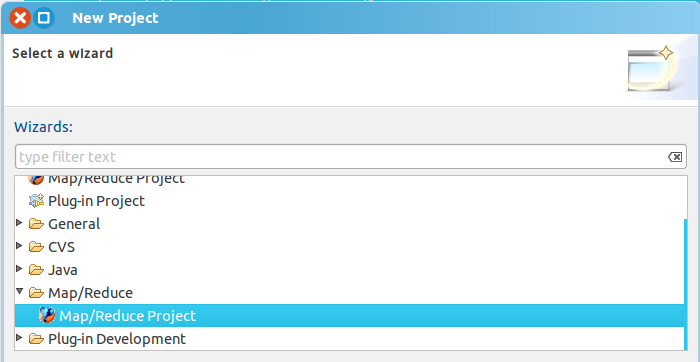
3. 設定輸入目錄及檔案
在專案工程包裡面新建一個名為input的目錄,裡面存放需要處理的輸入檔案。這裡選用2個檔名分別為file01和file02的檔案進行測試。檔案內容同需求示例。
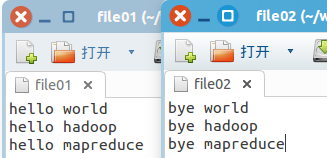
4. 將輸入檔案傳輸入Hdfs
在終端輸入以下命令即可將整個目錄傳輸進Hdfs(input目錄下的所有檔案將會被送進Hdfs下名為input01的目錄裡),請根據MapReduce工程包實際路徑對如下命令略作修改即可:
1 ./bin/hadoop fs -put ../workspace/Hadoop_t1/input/ input01
5. 在工程包中新建一個WordCount類並將上面的原始碼拷貝進去。
6. 調整專案執行引數:右鍵專案 -> “Run As" -> ”Run Configurations"
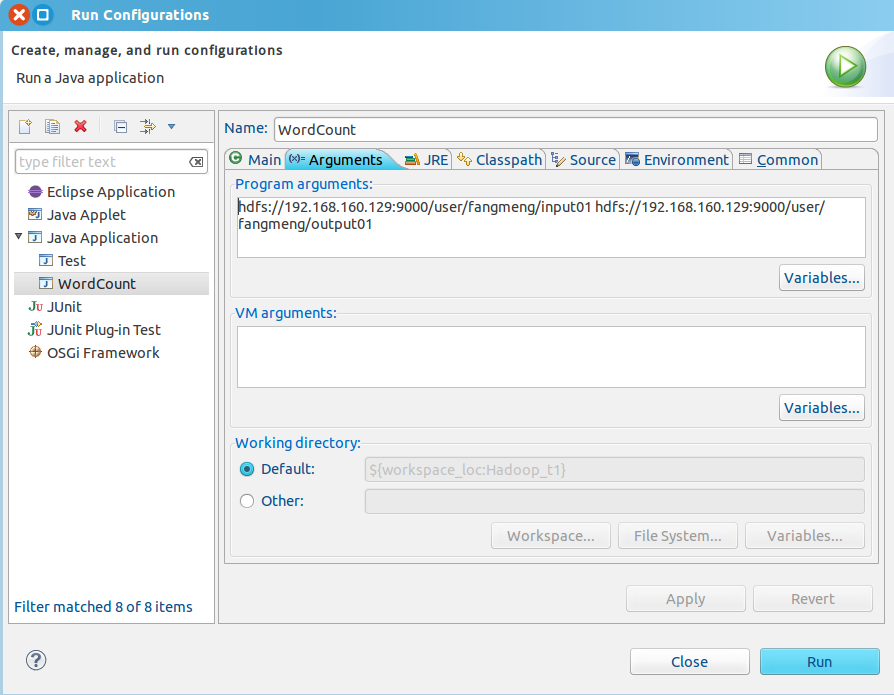
需要新增的就是"Program arguments"下的那些程式碼。它們其實是作為命令列引數傳遞程式序的,第一段是輸入檔案路徑;第二段是輸出檔案路徑。
路徑的格式為 "[主機IP地址:hdfs埠] + [輸入/輸出目錄在hdfs中的路徑]"。
可以輸入以下命令檢視輸入目錄路徑:
1 ./bin/hadoop fs -ls

7. 點選"Run"執行程式。
8. 執行以下命令檢視結果:
1 ./bin/hadoop fs -cat output01/*

這些主機和Hdfs的檔案傳遞,顯示也可以使用Eclipse,更方便容易。在此就不提了。
小結
1. 多多熟練Hadoop平臺下MapReduce專案基本建立流程。
2. WordCount是一個很經典的Hadoop示例,它雖然簡單,但具有很大的代表性。
3. 從某個程度上來說也反映了其設計的初衷,對日誌檔案的分析。