前言
閱讀本文前,請先回答下面兩個問題:
1. 資料庫和資料倉儲有什麼區別?
2. 某大公司Hadoop Hive裡的關係表不完全滿足完整/參照性約束,也不完全滿足正規化要求,甚至第一正規化都不滿足。這種情況正常嗎?
如果您不能五秒內給出答案,那麼本文應該是對您有幫助的。
注:如果您還不清楚完整參照性約束,請參考《資料庫關係建模》:,如果您還不瞭解正規化,請參考《更新異常與規範化設計》。
資料庫的"分家"
隨著關聯式資料庫理論的提出,誕生了一系列經典的RDBMS,如Oracle,MySQL,SQL Server等。這些RDBMS被成功推向市場,併為社會資訊化的發展做出的重大貢獻。然而隨著資料庫使用範圍的不斷擴大,它被逐步劃分為兩大基本型別:
1. 操作型資料庫
主要用於業務支撐。一個公司往往會使用並維護若干個資料庫,這些資料庫儲存著公司的日常運算元據,比如商品購買、酒店預訂、學生成績錄入等;
2. 分析型資料庫
主要用於歷史資料分析。這類資料庫作為公司的單獨資料儲存,負責利用歷史資料對公司各主題域進行統計分析;
那麼為什麼要"分家"?在一起不合適嗎?能不能構建一個同樣適用於操作和分析的統一資料庫?
答案是NO。一個顯然的原因是它們會"打架"......如果操作型任務和分析型任務搶資源怎麼辦呢?再者,它們有太多不同,以致於早已"貌合神離"。接下來看看它們到底有哪些不同吧。
操作型資料庫 VS 分析型資料庫
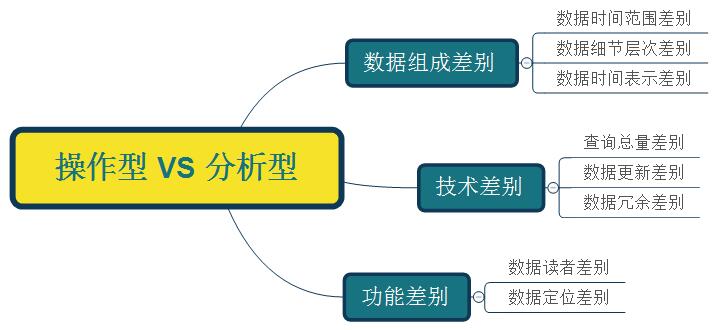
因為主導功能的不同(面向操作/面向分析),兩類資料庫就產生了很多細節上的差異。這就好像同樣是人,但一個和尚和一個穆斯林肯定有很多行為/觀念上的不同。
接下來本文將詳細分析兩類資料庫的不同點:
1. 資料組成差別 - 資料時間範圍差別
一般來講,操作型資料庫只會存放90天以內的資料,而分析型資料庫存放的則是數年內的資料。這點也是將操作型資料和分析型資料進行物理分離的主要原因。
2. 資料組成差別 - 資料細節層次差別
操作型資料庫存放的主要是細節資料,而分析型資料庫中雖然既有細節資料,又有彙總資料,但對於使用者來說,重點關注的是彙總資料部分。
操作型資料庫中自然也有彙總需求,但彙總資料本身不儲存而只儲存其生成公式。這是因為操作型資料是動態變化的,因此彙總資料會在每次查詢時動態生成。
而對於分析型資料庫來說,因為彙總資料比較穩定不會發生改變,而且其計算量也比較大(因為時間跨度大),因此它的彙總資料可考慮事先計算好,以避免重複計算。
3. 資料組成差別 - 資料時間表示差別
操作型資料通常反映的是現實世界的當前狀態;而分析型資料庫既有當前狀態,還有過去各時刻的快照,分析型資料庫的使用者可以綜合所有快照對各個歷史階段進行統計分析。
4. 技術差別 - 查詢資料總量和查詢頻度差別
操作型查詢的資料量少而頻率多,分析型查詢則反過來,資料量大而頻率少。要想同時實現這兩種情況的配置優化是不可能的,這也是將兩類資料庫物理分隔的原因之一。
5. 技術差別 - 資料更新差別
操作型資料庫允許使用者進行增,刪,改,查;分析型資料庫使用者則只能進行查詢。
6. 技術差別 - 資料冗餘差別
資料的意義是什麼?就是減少資料冗餘,避免更新異常。而如5所述,分析型資料庫中沒有更新操作。因此,減少資料冗餘也就沒那麼重要了。
現在回到開篇是提到的第二個問題"某大公司Hadoop Hive裡的關係表不完全滿足完整/參照性約束,也不完全滿足正規化要求,甚至第一正規化都不滿足。這種情況正常嗎?",答曰是正常的。因為Hive是一種資料倉儲,而資料倉儲和分析型資料庫的關係非常緊密(後文會講到)。它只提供查詢介面,不提供更新介面,這就使得消除冗餘的諸多措施不需要被特別嚴格地執行了。
7. 功能差別 - 資料讀者差別
操作型資料庫的使用者是業務環境內的各個角色,如使用者,商家,進貨商等;分析型資料庫則只被少量使用者用來做綜合性決策。
8. 功能差別 - 資料定位差別
這裡說的定位,主要是指以何種目的組織起來。操作型資料庫是為了支撐具體業務的,因此也被稱為"面向應用型資料庫";分析型資料庫則是針對各特定業務主題域的分析任務建立的,因此也被稱為"面向主題型資料庫"。
資料倉儲(data warehouse)定義
聰明的讀者應該已經意識到這個問題:既然分析型資料庫中的操作都是查詢,因此也就不需要嚴格滿足完整性/參照性約束以及正規化設計要求,而這些卻正是關聯式資料庫精華所在。這樣的情況下再將它歸為資料庫會很容易引起大家混淆,畢竟在絕大多數人心裡資料庫是可以關係型資料庫畫上等號的。
那麼為什麼不乾脆叫"面向分析的儲存系統"呢?
Bingo!~這就是關於資料倉儲最貼切的定義了。事實上資料倉儲不應讓傳統關聯式資料庫來實現,因為關聯式資料庫最少也要求滿足第1正規化,而資料倉儲裡的關係表可以不滿足第1正規化。也就是說,同樣的記錄在一個關係表裡可以出現N次。但由於大多數資料倉儲內的表的統計分析還是用SQL,因此很多人把它和關聯式資料庫搞混了。
知道了什麼是資料倉儲後,再來看看它有哪些特點吧。某種程度上來說,這也是分析型資料庫的特點:
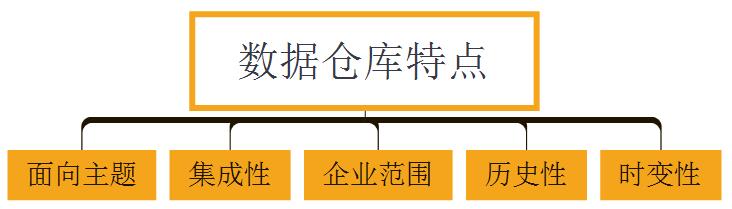
1. 面向主題
面向主題特性是資料倉儲和操作型資料庫的根本區別。操作型資料庫是為了支撐各種業務而建立,而分析型資料庫則是為了對從各種繁雜業務中抽象出來的分析主題(如使用者、成本、商品等)進行分析而建立;
2. 整合性
整合性是指資料倉儲會將不同源資料庫中的資料彙總到一起;
3. 企業範圍
資料倉儲內的資料是面向公司全域性的。比如某個主題域為成本,則全公司和成本有關的資訊都會被彙集進來;
4. 歷史性
較之操作型資料庫,資料倉儲的時間跨度通常比較長。前者通常儲存幾個月,後者可能幾年甚至幾十年;
5. 時變性
時變性是指資料倉儲包含來自其時間範圍不同時間段的資料快照。有了這些資料快照以後,使用者便可將其彙總,生成各歷史階段的資料分析報告;
資料倉儲元件
資料倉儲的核心元件有四個:各源資料庫,ETL,資料倉儲,前端應用。如下圖所示:
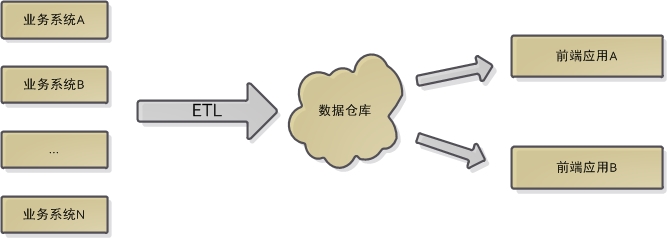
1. 業務系統
業務系統包含各種源資料庫,這些源資料庫既為業務系統提供資料支撐,同時也作為資料倉儲的資料來源(注:除了業務系統,資料倉儲也可從其他外部資料來源獲取資料);
2. ETL
ETL分別代表:提取extraction、轉換transformation、載入load。其中提取過程表示操作型資料庫蒐集指定資料,轉換過程表示將資料轉化為指定格式並進行資料清洗保證資料質量,載入過程表示將轉換過後滿足指定格式的資料載入進資料倉儲。資料倉儲會週期不斷地從源資料庫提取清洗好了的資料,因此也被稱為"目標系統";
3. 前端應用
和操作型資料庫一樣,資料倉儲通常提供具有直接訪問資料倉儲功能的前端應用,這些應用也被稱為BI(商務智慧)應用;
資料集市(data mart)
資料集市可以理解為是一種"小型資料倉儲",它只包含單個主題,且關注範圍也非全域性。
資料集市可以分為兩種,一種是獨立資料集市(independent data mart),這類資料集市有自己的源資料庫和ETL架構;另一種是非獨立資料集市(dependent data mart),這種資料集市沒有自己的源系統,它的資料來自資料倉儲。當使用者或者應用程式不需要/不必要/不允許用到整個資料倉儲的資料時,非獨立資料集市就可以簡單為使用者提供一個資料倉儲的"子集"。
資料倉儲開發流程
在資料庫系列的第五篇中,曾詳細分析了資料庫系統的開發流程。資料倉儲的開發流程和資料庫的比較相似,因此本文僅就其中區別進行分析。
下圖為資料倉儲的開發流程:
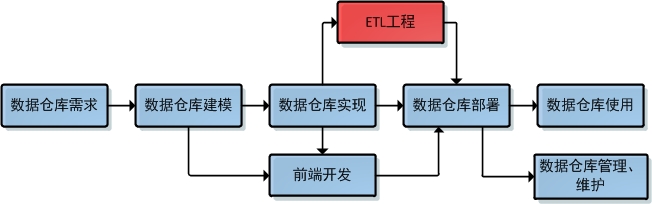
較之資料庫系統開發,資料倉儲開發只多出ETL工程部分。然而這一部分極有可能是整個資料倉儲開發流程中最為耗時耗資源的一個環節。因為該環節要整理各大業務系統中雜亂無章的資料並協調後設資料上的差別,所以工作量很大。在很多公司都專門設有ETL工程師這樣的崗位,大的公司甚至專門聘請ETL專家。
小結
在大資料時代,資料倉儲的重要性更勝以往。Hadoop平臺下的Hive,Spark平臺下的Spark SQL都是各自生態圈內應用最熱門的配套工具,而它們的本質就是開源分散式資料倉儲。
在國內最優秀的網際網路公司裡(如阿里、騰訊),很多資料引擎是架構在資料倉儲之上的(如資料分析引擎、資料探勘引擎、推薦引擎、視覺化引擎等等)。不少員工認為,開發成本應更多集中在資料倉儲層,不斷加大資料建設的投入。因為一旦規範、標準、高效能的資料倉儲建立好了,在之上進行資料分析、資料探勘、跑推薦演算法等都是輕鬆愜意的事情。反之如果業務資料沒梳理好,各種髒亂資料會搞得人焦頭爛額,苦不堪言。