前言
假如你想到某個線上約會網站尋找約會物件,那麼你很可能將該約會網站的所有使用者歸為三類:
1. 不喜歡的
2. 有點魅力的
3. 很有魅力的
你如何決定某個使用者屬於上述的哪一類呢?想必你會分析使用者的資訊來得到結論,比如該使用者 "每年獲得的飛行常客里程數","玩網遊所消耗的時間比","每年消耗的冰淇淋公升數"。
使用機器學習的K-近鄰演算法,可以幫助你在獲取到使用者的這三個資訊後(或者更多資訊 方法同理),自動幫助你對該使用者進行分類,多方便呀!
本文將告訴你如何具體實現這樣一個自動分類程式。
第一步:收集並準備資料
首先,請蒐集一些約會資料 - 儘可能多。
然後將自行蒐集到的資料存放到一個txt檔案中,例如,可以將每個樣本資料各為一行,
前言中提到的那三個分析資料(特徵)以及分析結果(整數表示)各為一列,如下所示:
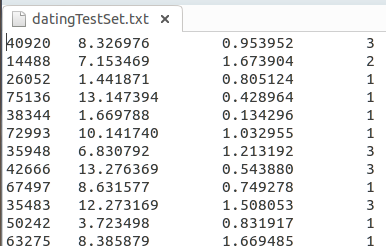
再編寫函式將這些資料從檔案中取出並存放到資料結構中:
1 # 匯入numpy數學運算庫 2 import numpy 3 4 # ============================================== 5 # 輸入: 6 # 訓練集檔名(含路徑) 7 # 輸出: 8 # 特徵矩陣和標籤向量 9 # ============================================== 10 def file2matrix(filename): 11 '獲取訓練集資料' 12 13 # 開啟訓練集檔案 14 fr = open(filename) 15 # 獲取檔案行數 16 numberOfLines = len(fr.readlines()) 17 # 檔案指標歸0 18 fr.seek(0) 19 # 初始化特徵矩陣 20 returnMat = numpy.zeros((numberOfLines,3)) 21 # 初始化標籤向量 22 classLabelVector = [] 23 # 特徵矩陣的行號 也即樣本序號 24 index = 0 25 26 for line in fr: # 遍歷訓練集檔案中的所有行 27 # 去掉行頭行尾的換行符,製表符。 28 line = line.strip() 29 # 以製表符分割行 30 listFromLine = line.split('\t') 31 # 將該行特徵部分資料存入特徵矩陣 32 returnMat[index,:] = listFromLine[0:3] 33 # 將該行標籤部分資料存入標籤矩陣 34 classLabelVector.append(int(listFromLine[-1])) 35 # 樣本序號+1 36 index += 1 37 38 return returnMat,classLabelVector
獲取到資料後就可以print檢視獲取到的資料內容了,如下:
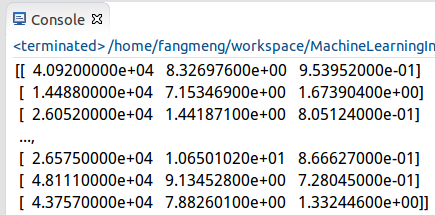
很顯然,這樣的顯示非常的不友好,可採用Python的Matplotlib庫來影象化地展示獲取到的資料。
如果你是在Ubuntu下使用Eclipse外掛編譯PyDev的話,安裝Matplotlib是很坑的。
在獲取到安裝包後,還得在外掛設定那裡新增新的庫路徑,因為Matplotlib不會自動安裝到Python2.7的庫目錄下,這和NumPy不同。
下面這個才是正確的庫路徑:

然後就可以編寫以下程式碼進行資料的分析了:
1 # 新建一個圖物件 2 fig = plt.figure() 3 # 設定1行1列個圖區域,並選擇其中的第1個區域展示資料。 4 ax = fig.add_subplot(111) 5 # 以訓練集第一列(玩網遊所消耗的時間比)為資料分析圖的行,第二列(每年消費的冰淇淋公升數)為資料分析圖的列。 6 ax.scatter(datingDataMat[:,1], datingDataMat[:,2]) 7 # 展示資料分析圖 8 plt.show()
另外在程式碼頂部記得包含所需的matplotlib庫:
1 # 匯入Matplotlib庫 2 import matplotlib.pyplot as plt 3 import matplotlib
執行完後,輸出資料分析圖如下:
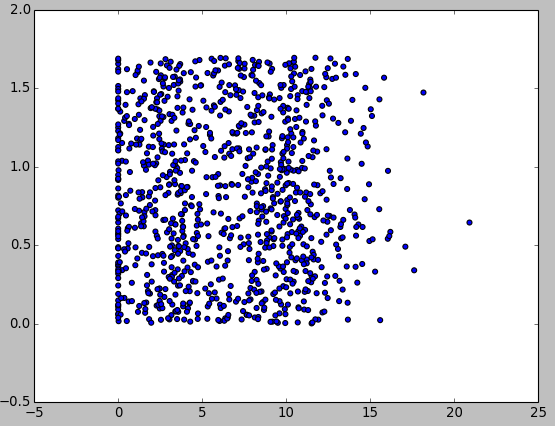
這裡發現一個問題,上面的資料分析圖並沒有顯示分類的結果。
進一步優化資料分析圖顯示部分程式碼:
1 # 新建一個圖物件 2 fig = plt.figure() 3 # 設定1行1列個圖區域,並選擇其中的第1個區域展示資料。 4 ax = fig.add_subplot(111) 5 # 以訓練集第一列(玩網遊所消耗的時間比)為資料分析圖的行,第二列(每週消費的冰淇淋公升數)為資料分析圖的列。 6 ax.scatter(datingDataMat[:,1], datingDataMat[:,2], 15.0*numpy.array(datingLabels), 15.0*numpy.array(datingLabels)) 7 # 座標軸定界 8 ax.axis([-2,25,-0.2,2.0]) 9 # 座標軸說明 (matplotlib配置中文顯示有點麻煩 這裡直接用英文的好了) 10 plt.xlabel('Percentage of Time Spent Playing Online Games') 11 plt.ylabel('Liters of Ice Cream Consumed Per Week') 12 # 展示資料分析圖 13 plt.show()
得到如下資料分析圖:
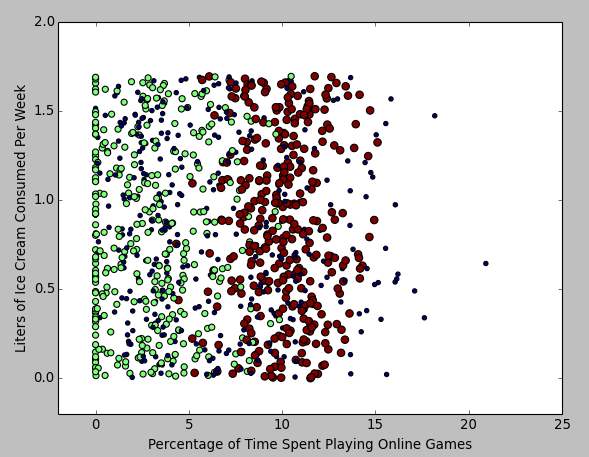
也可以用同樣方法得到 "每年獲得的飛行常客里程數" 和 "玩網遊所消耗的時間比" 為軸的圖:
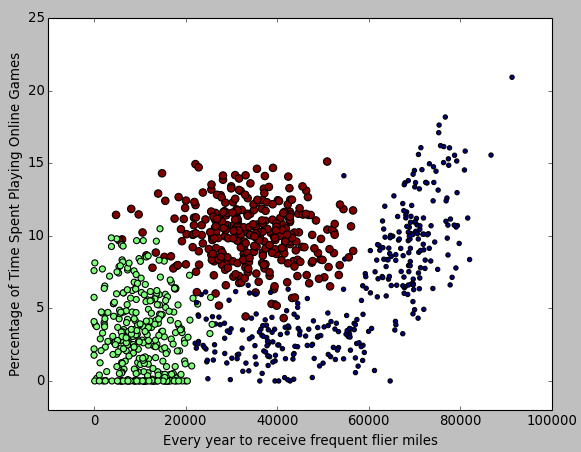
第三步:資料歸一化
想必你會發現,我們分析的這三個特徵,在距離計算公式中所佔的權重是不同的:飛機歷程肯定要比吃冰淇淋的公升數大多了。
因此,需要將它們轉為同樣的一個數量區間,再進行距離計算。 --- 這個步驟就叫做資料歸一化。
可以使用如下公式對資料進行歸一化:
newValue = (oldValue - min) / (max - min)
即用舊的特徵值去減它取到的最小的值,然後再除以它的取值範圍。
很顯然,所有得到的新值取值均在 0 -1 。
這部分程式碼如下:
1 # ============================================== 2 # 輸入: 3 # 訓練集 4 # 輸出: 5 # 歸一化後的訓練集 6 # ============================================== 7 def autoNorm(dataSet): 8 '資料歸一化' 9 10 # 獲得每列最小值 11 minVals = dataSet.min(0) 12 # 獲得每列最大值 13 maxVals = dataSet.max(0) 14 # 獲得每列特徵的取值範圍 15 ranges = maxVals - minVals 16 # 構建初始矩陣(模型同dataSet) 17 normDataSet = numpy.zeros(numpy.shape(dataSet)) 18 19 # 資料歸一化矩陣運算 20 m = dataSet.shape[0] 21 normDataSet = dataSet - numpy.tile(minVals, (m,1)) 22 # 注意/是特徵值相除法。/在別的函式庫也許是矩陣除法的意思。 23 normDataSet = normDataSet/numpy.tile(ranges, (m,1)) 24 25 return normDataSet
第四步:測試演算法
測試的策略是隨機取10%的資料進行分析,再判斷分類準確率如何。
這部分程式碼如下:
1 # ================================================ 2 # 輸入: 3 # 空 4 # 輸出: 5 # 對指定訓練集檔案進行K近鄰演算法測試並列印測試結果 6 # ================================================ 7 def datingClassTest(): 8 '分類演算法測試' 9 10 # 設定要測試的資料比重 11 hoRatio = 0.10 12 # 獲取訓練集 13 datingDataMat,datingLabels = file2matrix('datingTestSet.txt') 14 # 資料歸一化 15 normMat, ranges, minVals = autoNorm(datingDataMat) 16 # 計算實際要測試的樣本數 17 m = normMat.shape[0] 18 numTestVecs = int(m*hoRatio) 19 # 存放錯誤數 20 errorCount = 0.0 21 22 # 對測試集樣本一一進行分類並分析列印結果 23 print "錯誤的分類結果如下:" 24 for i in range(numTestVecs): 25 classifierResult = classify0(normMat[i,:],normMat[numTestVecs:m,:],datingLabels[numTestVecs:m],3) 26 if (classifierResult != datingLabels[i]): 27 print "分類結果: %d, 實際結果: %d" % (classifierResult, datingLabels[i]) 28 errorCount += 1.0 29 print "總錯誤率: %.2f" % (errorCount/float(numTestVecs)) 30 print "總錯誤數:%.2f" % errorCount
其中,classify0 函式在文章K-近鄰分類演算法原理分析與程式碼實現中有具體實現。
列印出如下結果:

錯誤率為5%左右,這是應該算是比較理想的狀況了吧。
第五步:使用演算法構建完整可用系統
下面,可以在這個訓練集和分類器之上構建一個完整的可用系統了。
系統功能很簡單:使用者輸入要判斷物件三個特徵 - "每年獲得的飛行常客里程數","玩網遊所消耗的時間比","每年消耗的冰淇淋公升數"。
PS:在真實系統中,這部分輸入可不由使用者來輸入,而從網站直接下載資料。
程式幫你判斷你是不喜歡還是有點喜歡,抑或是很喜歡。
這部分程式碼如下:
1 # =========================================================== 2 # 輸入: 3 # 空 4 # 輸出: 5 # 對使用者指定的物件以指定的訓練集檔案進行K近鄰分類並列印結果資訊 6 # =========================================================== 7 def classifyPerson(): 8 '約會物件分析系統' 9 10 # 分析結果集合 11 resultList = ['不喜歡', '有點喜歡', '很喜歡'] 12 13 # 獲取使用者輸入的目標分析物件的特徵值 14 percentTats = float(raw_input("玩網遊所消耗的時間比:")) 15 ffMiles = float(raw_input("每年獲得的飛行常客里程數:")) 16 iceCream = float(raw_input("每年消費的冰淇淋公升數:")) 17 18 # 獲取訓練集 19 datingDataMat, datingLabels = file2matrix('datingTestSet.txt') 20 # 資料歸一化 21 normMat, ranges, minVals = autoNorm(datingDataMat) 22 # 獲取分類結果 23 inArr = numpy.array([ffMiles, percentTats, iceCream]) 24 classifierResult = classify0((inArr-minVals)/ranges, normMat, datingLabels, 3) 25 26 print "分析結果:", resultList[classifierResult-1]
執行結果:
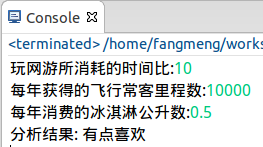
至此,該系統編寫完畢。
小結
1. KNN演算法其實並沒有一個實際的 "訓練" 過程。取得了資料就當作是訓練過了的。在下下篇文章將講解決策樹,它就有詳細的訓練,或者說知識學習的過程。
2. 可採用從網站自動下載資料的方式,讓這個系統的決策更為科學,再加上良好的介面,就能投入實際使用了。
3. 下篇文章將講解KNN演算法一個更為高階的應用 - 手寫識別系統。
4. 這個程式也看出,處理文字/字串方面,Python比C++好用多了。