前言
本文講解Hadoop中的程式設計及計算模型MapReduce,並將給出在MapReduce模型下程式設計的基本套路。
模型架構
在Hadoop中,用於執行計算任務(MapReduce任務)的機器有兩個角色:一個是JobTracker,一個是TaskTracker,前者用於管理和排程工作,後者用於執行工作。
一般來說,一個Hadoop叢集由一個JobTracker和N個TaskTracker構成。
執行流程
每次計算任務都可以分為兩個階段,Map階段和Reduce階段。
其中,Map階段接收一組鍵值對模式<key, Value>的輸入併產生同樣是鍵值對模式<key, Value>的中間輸出;
Reduce階段負責接收Map產生的中間輸出<key, Value>,然後對這個結果進行處理並輸出結果。
這裡舉個很簡單的例子,有一個程式用來統計文字中各個單詞出現的個數,那麼每個Map任務可以負責提取出文字中的所有單詞併產生n個<word, 1>這樣的輸出;
而Reduce任務可以負責對這些中間輸出做出處理,轉換成<word, n> 這樣的輸出。
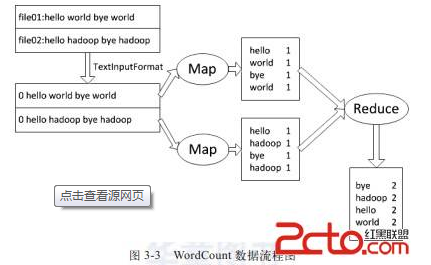
多說一句,Map產生的中間輸出是直接放在本地磁碟,job完成後就會刪除了。而Reduce產生的最終結果才會存放在Hdfs上。
編碼框架說明
編碼涉及到一些細節,建議結合具體程式碼進行分析,這裡只給出一個框架性的說明。推薦閱讀經典的wordcount程式。
1. 匯入Hadoop開發需要用到的一些包
2. 定義一個需要用到分散式計算的類
3. 在此類中新增Map類,並使該類繼承Mapper抽象類,然後實現該抽象類中的map方法。
4. 在此類中新增Reduce類,並使該類繼承Reducer抽象類,然後實現該抽象類中的reduce方法。
5. 在類中定義一個成員函式並做如下操作:
a. 定義一個Job物件負責job排程
b. 往a中定義的job物件中注入2中定義的分散式類 (setJarByClass)
c. 定義分散式任務的名字 (setJobName)
d. 往a中定義的job物件中注入輸出的key和value的型別 (setOutPutKeyClass,setOutPutKeyClass)
e. 往a中定義的job物件中注入3和4中定義的Map,Reduce類
f. 往a中定義的job物件中注入資料切分格式類 (setInputFormat,setOutputFormat)
g. 往a中定義的job物件中注入輸出的路徑地址 (setInputPaths,setOutputPath)
h. 啟動計算任務 (waitForCompletion)
i. 返回布林型別的執行結果
6. 在主函式中呼叫上述方法 (命令列方式)
執行方法
1. 執行以下格式的命令以編譯分散式計算類
1 javac -classpath "hadoop目錄下的core.jar" -d "結果輸出目錄" "分散式類檔名"
2. 執行以下格式的命令將該類打包成jar
1 jar -cvf "結果檔名(字尾.jar)" -C "目標目錄" "結果輸出目錄"
3. 執行以下格式的命令將輸入檔案存入HDFS檔案系統 (該命令將在HDFS上建立一個名為input的目錄並將使用者目錄下input目錄內字首為file的檔案匯入進去):
1 dfs -mkdir input 2 dfs -put ~/input/file0* input
4. 執行以下格式的命令啟動hadoop程式 (下面的引數一和二一般分別指輸入和輸出目錄)
1 jar "分散式類jar包" "分散式類名" 引數一,引數二......
MapReduce的資料流和控制流
下面來討論一下Hadoop程式的資料流和控制流的關係,首先請看下圖:
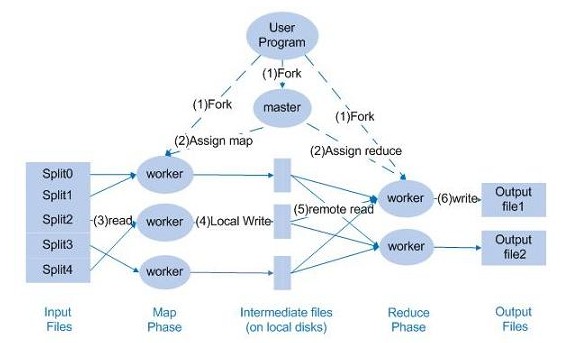
首先,由Master,也即JobTracker負責分派任務到下面的各個worker,也即TaskTracker。
某個worker在執行的時候,會返回進度報告,master負責記錄進度的進行狀況。
若某個worker失敗,那麼master會分派這個執行失敗的任務給新的worker。
程式優化技巧
MapReduce程式的優化主要集中在兩個方面:一個是運算效能方面的優化;另一個是IO操作方面的優化。
具體體現在以下的幾個環節之上:
1. 任務排程
a. 儘量選擇空閒節點進行計算
b. 儘量把任務分配給InputSplit所在機器
2. 資料預處理與InputSplit的大小
儘量處理少量的大資料;而不是大量的小資料。因此可以在處理前對資料進行一次預處理,將資料進行合併。
如果自己懶得合併,可以參考使用CombineFileInputFormat函式。具體用法請查閱相關函式手冊。
3. Map和Reduce任務的數量
Map任務槽中任務的數量需要參考Map的執行時間,而Reduce任務的數量則只需要參考Map槽中的任務數,一般是0.95或1.75倍。
4. 使用Combine函式
該函式用於合併本地的資料,可以大大減少網路消耗。具體請參考函式手冊。
5. 壓縮
可以對一些中間資料進行壓縮處理,達到減少網路消耗的目的。
6. 自定義comparator
可以自定義資料型別實現更復雜的目的。
小結
本文大致講解了Hadoop的程式設計模型MapReduce,並大致介紹瞭如何在這個框架下進行簡單的程式開發。
更復雜的框架剖析以及Hadoop高階程式開發,將在以後的文章中進行細緻的探討。