前言
本文介紹如何在Ubuntu Kylin作業系統上搭建Hadoop平臺。
配置
1. 作業系統: Ubuntu Kylin 14.04
2. 程式語言: JDK 1.8
3. 通訊協議: SSH
4. 雲端計算專案版本: Hadoop 1.2.1
第一步:安裝最新版本的JDK (若已經安裝過請忽略這一步)
1. 去官網下載JDK1.8並解壓 (當前安裝包為:jdk-8u25-linux-x64.gz)
2. 將解壓後的安裝包複製到 /usr/lib/jvm 目錄下 (jvm目錄需要自行建立)
3. 以管理員方式開啟 /etc/profile 檔案並在檔案底部新增以下程式碼:
1 #set Java Environment 2 export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_25 3 export CLASSPATH=".:$JAVA_HOME/lib:$CLASSPATH" 4 export PATH="$JAVA_HOME/bin:$PATH"
4. 執行以下命令使配置檔案立即生效:
1 source /etc/profile
5. 執行以下命令驗證JDK是否安裝成功:
1 java -version
若顯示以下資訊表示安裝完成:

第二步:配置SSH免密碼登陸
1. 執行以下命令安裝SSH:
1 sudo app-get install ssh
2. 檢查使用者目錄下是不是有個名為.ssh的隱藏資料夾,沒有的話就自己建立一個。
3. 執行以下命令配置SSH無密碼登陸 (這幾行程式碼的功能請參考SSH使用文件):
1 ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa 2 cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
4. 執行以下命令驗證SSH是否安裝配置成功:
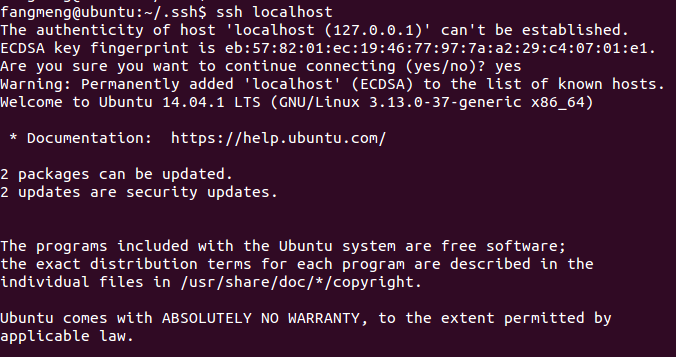
1 ssh localhost
出現提示輸入yes,若終端顯示以下資訊,表示SSH配置成功:
第三步:安裝並執行Hadoop
說明:Hadoop有三種執行方式 - 單機模式,偽分散式和完全分散式。
其中,前兩者主要用於程式的測試和除錯,這裡要講的是偽分散式的配置,配置完全分散式的方法將在以後講解。
1. 下載並解壓最新版本的Hadoop到當前目錄下 (當前安裝包為:hadoop-1.2.1.tar.gz)
2. 進入conf子目錄中,修改如下配置檔案:
a. hadoop-env.sh (設定JAVA路徑)
在末尾新增:
1 export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_25
b. core-site.xml (配置HDFS地址及埠號)
配置為:
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>fs.default.name</name> <value>hdfs://localhost:9000</value> </property> </configuration>
c. hdfs-site.xml (修改備份方式,單機版本需要將其改為1)
配置為:
1 <?xml version="1.0"?> 2 <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> 3 4 <!-- Put site-specific property overrides in this file. --> 5 6 <configuration> 7 <property> 8 <name>dfs.replication</name> 9 <value>1</value> 10 </property> 11 </configuration>
d. mapred-site.xml (設定JobTracker地址及埠)
配置為:
1 <?xml version="1.0"?> 2 <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> 3 4 <!-- Put site-specific property overrides in this file. --> 5 6 <configuration> 7 <property> 8 <name>mapred.job.tracker</name> 9 <value>localhost:9001</value> 10 </property> 11 </configuration>
3. 進入Hadoop資料夾執行以下命令以格式化Hadoop檔案系統HDFS:
1 bin/hadoop namenode -format
4. 執行以下命令以啟動所有Hadoop程式:
1 bin/start-all.sh
5. 驗證Hadoop是否安裝成功
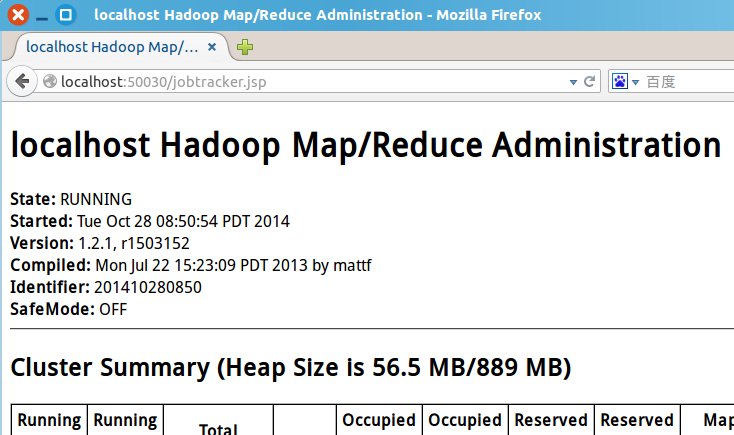
a. 開啟瀏覽器,輸入網址 http://localhost:50030 以檢視MapReduce的Web頁面:
b. 開啟瀏覽器,輸入網址 http://localhost:50070 以檢視HDFS的Web頁面:
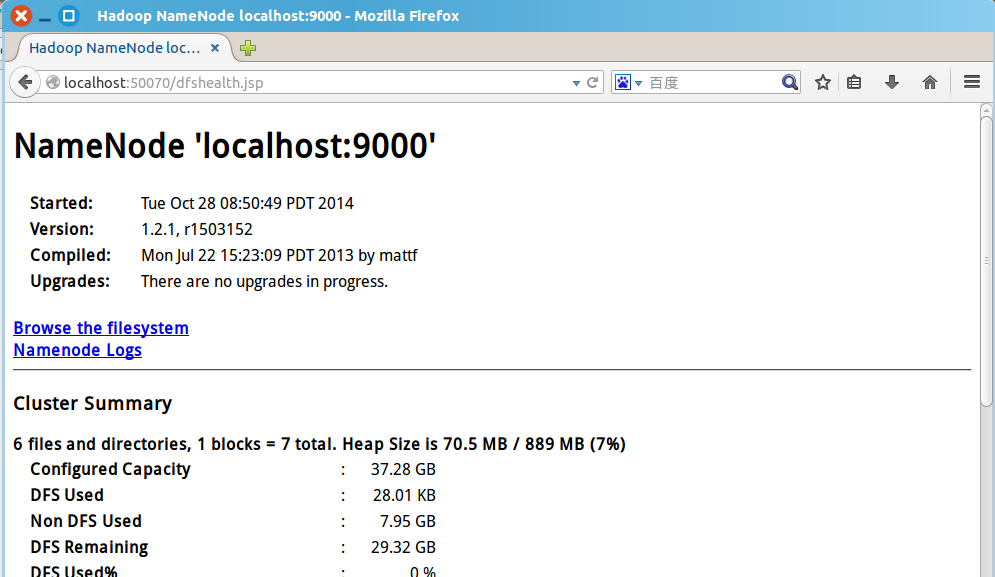
如果顯示正常,那麼Hadoop環境便搭建好了。
小結
1. 偽分散式的架構,機制和真實分散式其實是一樣的,不過偽分散式中,Master和Slave都是一臺機器。
2. 關於真實分散式環境的搭建,將在以後介紹。到時會在虛擬機器上組建一個虛擬網路,跑真·分散式程式。