前言
本文大致介紹下Hadoop的一些背景知識,為後面深入學習打下鋪墊。
什麼是Hadoop
Hadoop是一個開源分散式計算平臺,它以HDFS檔案系統和MapReduce計算框架為核心。
前者能夠讓使用者使用一些廉價的硬體搭建出分散式系統,後者則能夠讓使用者在不需要過多瞭解底層架構細節的情況下,開發並行分散式應用程式。
-- 具體含義以後會詳細分析。
Hadoop的作用
具體的來說,Hadoop的作用主要在於處理海量資料,這也是為什麼大資料技術中常常提到這個概念的原因。
更具體的來說,雅虎通過它做Web搜尋,跑廣告系統;百度用它做搜尋日誌分析,網頁資料探勘;阿里用它儲存海量的交易資料;移動研究院用它進行資料分析並對外提供服務。
很多人看好它會在更多領域(如銀行,醫院等),更深層次,發揮出更大作用。
Hadoop的優勢
為什麼Hadoop能夠勝任這些工作?
有以下幾個主要原因:
1. 高可靠性 - 能正確無誤的處理資料
2. 高擴充套件性 - 可以方便的加入或遮蔽計算機叢集中的節點
3. 高效性 - 能非常快速的處理資料
4. 高容錯性 - 某個節點任務失敗不會影響結果
Hadoop專案結構圖
除了HDFS檔案系統和MapReduce計算架構兩大核心,Hadoop還提供了其他一些專案提供更多服務,這些專案也不可或缺。 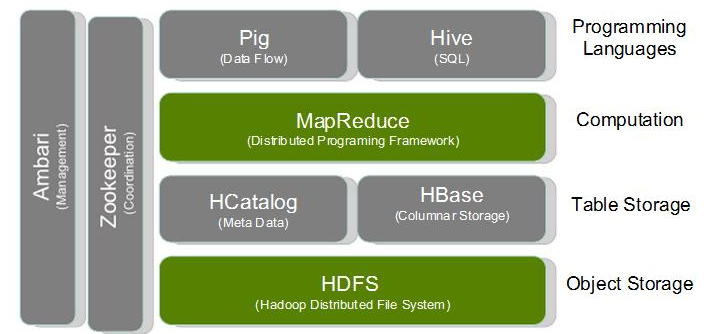
這些專案具體的使用方法,都是日後學習的重要內容,在此不做細緻介紹。
Hadoop的體系結構
首先介紹HDFS檔案系統的體系結構:
HDFS採用M/S結構模型,Namenode作為主伺服器,管理檔案系統的名稱空間和客戶端對檔案的訪問操作;而Datanode管理儲存的資料。
下為HDFS檔案系統的體系結構圖:
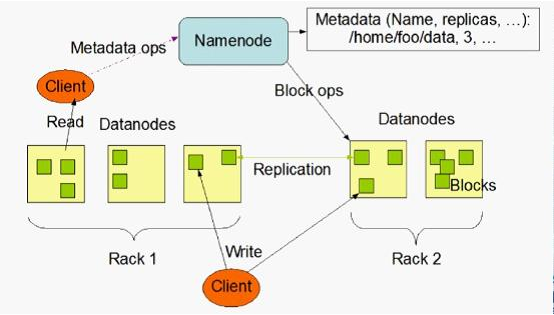
通常來說一個典型的叢集環境是一臺機器執行Namenode而其他每臺機器執行一個Datanode。
這裡再介紹下MapReduce計算架構的體系結構:
MapReduce其本質是一個非常簡單易用的並行程式設計框架,它同樣採用M/S模型,由一個單獨執行在主節點的JobTracker和執行在各個從節點上的TaskTracker共同組成。
小結
本文旨在描繪出Hadoop這頭“大象”的具體輪廓,其細節在以後的文章中會具體分析,細細體會,實際應用。