前言
支援向量機,也即SVM,號稱分類演算法,甚至機器學習界老大哥。其理論優美,發展相對完善,是非常受到推崇的演算法。
本文將講解的SVM基於一種最流行的實現 - 序列最小優化,也即SMO。
另外還將講解將SVM擴充套件到非線性可分的資料集上的大致方法。
預備術語
1. 分割超平面:就是決策邊界
2. 間隔:樣本點到分割超平面的距離
3. 支援向量:離分割超平面距離最近的樣本點
演算法原理
在前一篇文章 - 邏輯迴歸中,講到了通過擬合直線來進行分類。
而擬合的中心思路是求錯誤估計函式取得最小值,得到的擬合直線是到各樣本點距離和最小的那條直線。
然而,這樣的做法很多時候未必是最合適的。
請看下圖:
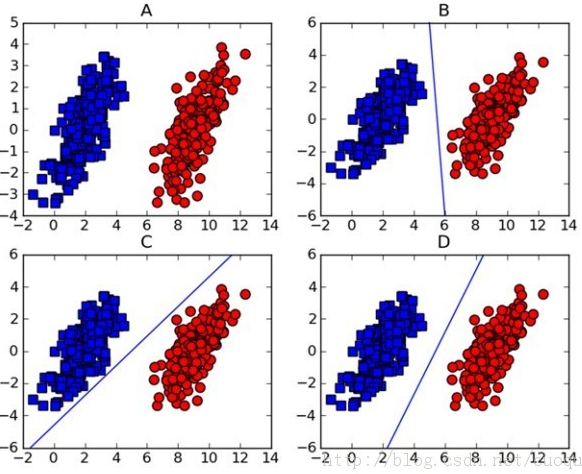
一般來說,邏輯迴歸得到的直線線段會是B或者C這樣的形式。而很顯然,從分類演算法的健壯性來說,D才是最佳的擬合線段。
SVM分類演算法就是基於此思想:找到具有最小間隔的樣本點,然後擬合出一個到這些樣本點距離和最大的線段/平面。
如何計算最優超平面
1. 首先根據演算法思想 - "找到具有最小間隔的樣本點,然後擬合出一個到這些樣本點距離和最大的線段/平面。" 寫出目標函式:

該式子的解就是待求的迴歸係數。
然而,這是一個巢狀優化問題,非常難進行直接優化求解。為了解這個式子,還需要以下步驟。
2. 不去計算內層的min優化,而是將距離值界定到一個範圍 - 大於1,即最近的樣本點,也即支援向量到超平面的距離為1。下圖可以清楚表示這個意思:

去掉min操作,代之以界定:label * (wTx + b) >= 1。
3. 這樣得到的式子就是一個帶不等式的優化問題,可以採用拉格朗日乘子法(KKT條件)去求解。
具體步驟推論本文不給出。推導結果為:

另外,可加入鬆弛係數 C,用於控制 "最大化間隔" 和"保證大部分點的函式間隔小於1.0" 這兩個目標的權重。
將 α >= 0 條件改為 C >= α >= 0 即可。
α 是用於求解過程中的一個向量,它和要求的結果迴歸係數是一一對應的關係。
將其中的 α 解出後,便可依據如下兩式子(均為推導過程中出現的式子)進行轉換得到迴歸係數:
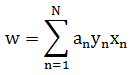
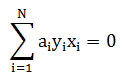
說明: 要透徹理解完整的數學推導過程需要一些時間,可參考某位大牛的文章http://blog.csdn.net/v_july_v/article/details/7624837。
使用SMO - 高效優化演算法求解 α 值
演算法思想:
每次迴圈中選擇兩個 α 進行優化處理。一旦找到一對合適的 α,那麼就增大其中一個減小另外一個。
所謂合適,是指必須符合兩個條件:1. 兩個 α 值必須要在 α 分隔邊界之外 2. 這兩個α 還沒有進行過區間化處理或者不在邊界上。
使用SMO求解 α 虛擬碼:
1 建立一個 alpha 向量並將其初始化為全0 2 當迭代次數小於最大迭代次數(外迴圈): 3 對資料集中的每個向量(內迴圈): 4 如果該資料向量可以被優化 5 隨機選擇另外一個資料向量 6 同時優化這兩個向量 7 如果都不能被優化,推出內迴圈。 8 如果所有向量都沒有被優化,則增加迭代數目,繼續下一次的迴圈。
實現及測試程式碼:
1 #!/usr/bin/env python 2 # -*- coding:UTF-8 -*- 3 4 ''' 5 Created on 20**-**-** 6 7 @author: fangmeng 8 ''' 9 10 from numpy import * 11 from time import sleep 12 13 #===================================== 14 # 輸入: 15 # fileName: 資料檔案 16 # 輸出: 17 # dataMat: 測試資料集 18 # labelMat: 測試分類標籤集 19 #===================================== 20 def loadDataSet(fileName): 21 '載入資料' 22 23 dataMat = []; labelMat = [] 24 fr = open(fileName) 25 for line in fr.readlines(): 26 lineArr = line.strip().split('\t') 27 dataMat.append([float(lineArr[0]), float(lineArr[1])]) 28 labelMat.append(float(lineArr[2])) 29 return dataMat,labelMat 30 31 #===================================== 32 # 輸入: 33 # i: 返回結果不等於該引數 34 # m: 指定隨機範圍的引數 35 # 輸出: 36 # j: 0-m內不等於i的一個隨機數 37 #===================================== 38 def selectJrand(i,m): 39 '隨機取數' 40 41 j=i 42 while (j==i): 43 j = int(random.uniform(0,m)) 44 return j 45 46 #===================================== 47 # 輸入: 48 # aj: 資料物件 49 # H: 資料物件最大值 50 # L: 資料物件最小值 51 # 輸出: 52 # aj: 定界後的資料物件。最大H 最小L 53 #===================================== 54 def clipAlpha(aj,H,L): 55 '為aj定界' 56 57 if aj > H: 58 aj = H 59 if L > aj: 60 aj = L 61 return aj 62 63 #===================================== 64 # 輸入: 65 # dataMatIn: 資料集 66 # classLabels: 分類標籤集 67 # C: 鬆弛引數 68 # toler: 榮錯率 69 # maxIter: 最大迴圈次數 70 # 輸出: 71 # b: 偏移 72 # alphas: 拉格朗日對偶因子 73 #===================================== 74 def smoSimple(dataMatIn, classLabels, C, toler, maxIter): 75 'SMO演算法求解alpha' 76 77 # 資料格式轉化 78 dataMatrix = mat(dataMatIn); 79 labelMat = mat(classLabels).transpose() 80 m,n = shape(dataMatrix) 81 alphas = mat(zeros((m,1))) 82 83 84 iter = 0 85 b = 0 86 while (iter < maxIter): 87 # alpha 改變標記 88 alphaPairsChanged = 0 89 90 # 對所有資料集 91 for i in range(m): 92 # 預測結果 93 fXi = float(multiply(alphas,labelMat).T*(dataMatrix*dataMatrix[i,:].T)) + b 94 # 預測結果與實際的差值 95 Ei = fXi - float(labelMat[i]) 96 # 如果差值太大則進行優化 97 if ((labelMat[i]*Ei < -toler) and (alphas[i] < C)) or ((labelMat[i]*Ei > toler) and (alphas[i] > 0)): 98 # 隨機選擇另外一個樣本 99 j = selectJrand(i,m) 100 # 計算另外一個樣本的預測結果以及差值 101 fXj = float(multiply(alphas,labelMat).T*(dataMatrix*dataMatrix[j,:].T)) + b 102 Ej = fXj - float(labelMat[j]) 103 # 暫存當前alpha值對 104 alphaIold = alphas[i].copy(); 105 alphaJold = alphas[j].copy(); 106 # 確定alpha的最大最小值 107 if (labelMat[i] != labelMat[j]): 108 L = max(0, alphas[j] - alphas[i]) 109 H = min(C, C + alphas[j] - alphas[i]) 110 else: 111 L = max(0, alphas[j] + alphas[i] - C) 112 H = min(C, alphas[j] + alphas[i]) 113 if L==H: 114 pass 115 # eta為alphas[j]的最優修改量 116 eta = 2.0 * dataMatrix[i,:]*dataMatrix[j,:].T - dataMatrix[i,:]*dataMatrix[i,:].T - dataMatrix[j,:]*dataMatrix[j,:].T 117 if eta >= 0: 118 print "eta>=0"; continue 119 # 訂正alphas[j] 120 alphas[j] -= labelMat[j]*(Ei - Ej)/eta 121 alphas[j] = clipAlpha(alphas[j],H,L) 122 # 如果alphas[j]發生了輕微變化 123 if (abs(alphas[j] - alphaJold) < 0.00001): 124 continue 125 # 訂正alphas[i] 126 alphas[i] += labelMat[j]*labelMat[i]*(alphaJold - alphas[j]) 127 128 # 訂正b 129 b1 = b - Ei- labelMat[i]*(alphas[i]-alphaIold)*dataMatrix[i,:]*dataMatrix[i,:].T - labelMat[j]*(alphas[j]-alphaJold)*dataMatrix[i,:]*dataMatrix[j,:].T 130 b2 = b - Ej- labelMat[i]*(alphas[i]-alphaIold)*dataMatrix[i,:]*dataMatrix[j,:].T - labelMat[j]*(alphas[j]-alphaJold)*dataMatrix[j,:]*dataMatrix[j,:].T 131 if (0 < alphas[i]) and (C > alphas[i]): b = b1 132 elif (0 < alphas[j]) and (C > alphas[j]): b = b2 133 else: b = (b1 + b2)/2.0 134 135 # 更新修改標記引數 136 alphaPairsChanged += 1 137 138 if (alphaPairsChanged == 0): iter += 1 139 else: iter = 0 140 141 return b,alphas 142 143 def test(): 144 '測試' 145 146 dataArr, labelArr = loadDataSet('/home/fangmeng/testSet.txt') 147 b, alphas = smoSimple(dataArr, labelArr, 0.6, 0.001, 40) 148 print b 149 print alphas[alphas>0] 150 151 152 if __name__ == '__main__': 153 test()
其中,testSet.txt資料檔案格式為三列,前兩列特徵,最後一列分類結果。
測試結果:

結果具有隨機性,多次執行的結果不一定一致。
得到 alphas 陣列和 b 向量就能直接算到迴歸係數了,參考上述程式碼 93 行,稍作變換即可。
非線性可分情況的大致解決思路
當資料分析圖類似如下的情況:
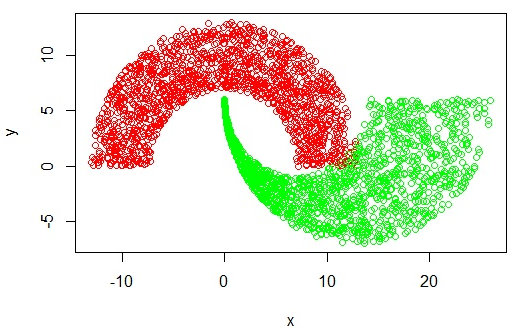
則顯然無法擬合出一條直線來。碰到這種情況的解決辦法是使用核函式 - 將在低維處理非線性問題轉換為在高維處理線性問題。
也就是說,將在SMO中所有出現了向量內積的地方都替換成核函式處理。
具體的用法,程式碼本文不做講解。
小結
支援向量機是分類演算法中目前用的最多的,也是最為完善的。
關於支援向量機的討論遠遠不會止於此,本文初衷僅僅是對這個演算法有一定的瞭解,認識。
若是在以後的工作中需要用到這方面的知識,還需要全面深入的學習,研究。