前言
前面的文章中,主要都是在圍繞關聯式資料庫理論進行研究,沒有涉及到資料庫系統的具體實現。
雖說資料庫系統的具體實現因業務環境,RDBMS等因素而異,但總體開發流程,以及開發過程中所涉及到的一些問題,也具有不少統一的套路、標準。
本文主要討論資料庫系統實現過程中的重點環節、基本開發流程、資料庫管理以及資料質量工程等話題。
參照完整性約束對更新刪除操作的影響
在第三篇(傳送門)中,我們已經討論過,關係設計的目的就是為了減少冗餘消除更新異常。但當時也留下一個問題:外碼本身是冗餘的,那麼涉及到外碼的更新時怎麼辦呢?
關聯式資料庫理論將這個問題交給了RDBMS,讓它來解決涉及外碼的更新異常。下面先來看一下,涉及外碼的更新異常到底長什麼樣子。
在下面的這個關係中:
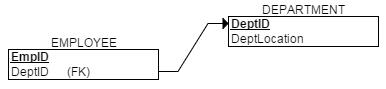
關係EMPLOYEE中的Dept屬性是一個外碼,它對應DEPARTMENT關係的主碼。如果對該屬性進行更新或者刪除,那麼這個外碼就找不到它對應的主碼,兩個關係的聯絡就被破壞了。針對這個問題,RDBMS的解決方案有四個,下面以刪除異常為例進行說明:

1. 限制刪除
限制刪除是指如果某記錄主碼被另一個記錄外碼對應,則該記錄不允許被刪除。如上面示例DEPARTMENT關係中的記錄在刪除的時候有可能被RDBMS禁止。
2. 級聯刪除
級聯刪除是指如果某個記錄的主碼被另一個記錄的外碼對應,那麼這兩個記錄將一起被刪除。
3. 設定為空
是指如果某個記錄的主碼被另一個記錄的外碼對應,那麼在刪除這個記錄後,另外那個記錄的外碼欄位置為空。
4. 設定預設值
同3,不過是將置為空改為設定成一個預設值。
更新情況和刪除一樣,要注意的是所有處理都發生在對外碼對映中的非外碼關係進行操作時發生。這些處理主要是對外碼關係進行附加操作,如級聯刪除,置空,置預設值,或者報錯。
索引機制
索引(index)機制的本質是一種檢索加速機制,本文將從索引的邏輯意義上對它進行解析,至於其在各RDBMS裡的物理實現細節則不做介紹。事實上若非資料庫維護管理人員,也沒必要知道。在下面這張客戶關係表中:
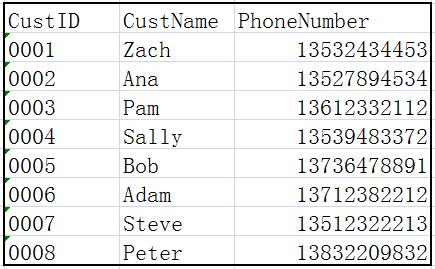
id是按順序排列的,因此如果要檢索某id對應記錄,則由於記錄已按id排好序,可使用多種查詢演算法提高檢索效率,如二分查詢等。但關係中某一列排好序以後,其他列必然是亂序的,那怎麼辦?在RDBMS中,這種情況可以通過新建一個只包含兩列的附加表來實現:

索引表中其中一列為索引欄位,另一列則包含一個指標指向原紀錄。這樣在對索引列進行查詢的時候,RDBMS會先對索引表進行操作,完了再對映到原表並返回結果。
從本質上來說,這是一種犧牲空間換取時間的辦法,索引建立不單耗費儲存資源,而且會降低更新、刪除等操作的效率。因此不是說建的索引越多就越好,具體建立何種索引,建立多少索引,則要取決於計算資源,RDBMS,業務場景等因素。
觸發器機制
觸發器是一種規則,當關系中刪除、插入、修改一條記錄的時候執行。它的應用場景很多,故幾乎所有RDBMS都提供了該功能。如下程式碼是在MYSQL中編寫的觸發器,它施加於student關係的insert操作上:每次insert一條學生記錄後,都會更新關係中的記錄數,如果記錄數超過10,則不為新的學生分配導師:
CREATE TRIGER studentinserttrigger
BEFORE INSERT ON student
FOR EACH ROW
BEGIN
DECLARE totaladvised INT DEFAULT 0;
SELECT COUNT(*) INTO totaladvised
FROM student
WHERE advisorid = NEW.advisorid;
IF (totaladvised >= 10) THEN
SET NEW.advisorid = NULL;
END IF
END;
注意這段程式碼不是標準SQL程式碼,不必細究。觸發器實現程式碼的語法規則取決於RDBMS,需要時再有針對性的參考手冊即可。
資料庫系統開發流程
所謂資料庫系統(database system),就是指讓使用者和資料庫資訊之間進行有效互動的計算機系統。其典型的框架如下圖所示:
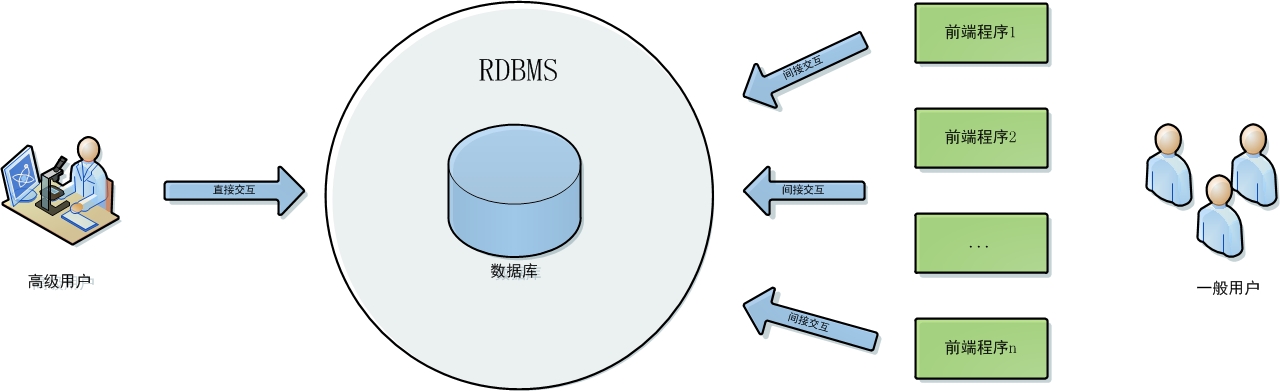
可見, 資料庫系統的三大主要成分分別是:資料庫,資料庫管理軟體RDBMS,還有前端應用程式(網站,APP等)。資料庫是資料庫系統的核心,負責存放所有資料。而資料庫對外的所有互動,均通過RDBMS來進行。一般使用者通過前端應用程式使用RDBMS,而比較專業的使用者也可直接使用RDBMS操縱資料庫。
舉例來說,某人通過APP訂購商品,那麼這個APP就是前端應用程式。而當他有一個具體行為,比如付款的時候,前段應用程式就會和RDBMS通訊,讓RDBMS完成扣款並返回操作執行結果。
資料庫系統的總體開發流程,可以總體劃分為以下步驟:

1. 資料庫需求
需求蒐集是所有環節中最重要的一步,吃透了使用者需求,往往就成功了大半。這些需求將指導後面如需求建模、實現、以及前端應用程式開發等。通常來說,需求都會通過ER圖來表示(參考本系列第一篇),並和各業務方討論蒐集得到,最終整理成文件。
要特別強調的一點是資料庫系統開發需求階段過程是迴圈迭代式的,一開始的需求集並不大,但隨著專案的進展,需求會越來越多。而且不論是以上哪個階段發生了需求變動,整個流程都需要重新走一遍,決不允許隱式變更需求。
2. 資料庫建模
也就是邏輯模型建模,在本系列第二篇有過詳細講解,這裡不再贅述。
3. 資料庫實現
這一步的本質就是在空的RDBMS裡實現2中建立的關係模型,一般通過使用SQL或者RDBMS提供的前端工具實現。
4. 開發前端應用程式
前端應用開發在需求蒐集好了之後就開始進行,主要有網站、APP等前端形式。另外前端程式的實際實現涉及到和資料庫之間互動,因此這一步的最終完成在資料庫建模之後。
5. 資料庫部署
顧名思義,這一步就是部署資料庫系統的軟硬體環境。筆者這裡插一個故事,以前在A公司工作時,一哥們自告奮勇到某政府祕密部門部署私有云環境。那地方很偏僻,不允許外網,U盤都不能用,只能光碟安裝。而A公司的雲平臺部署是一件非常複雜的活,於是那哥們就在那裡呆了一個多月,回來後據說是瘦了7斤......
回到正題,資料庫部署往往還包含將初始資料填入資料庫中的意思。對於雲資料倉儲,這一步就叫"資料上雲"。
6. 資料庫使用
這一步沒啥多講的,就再講一個有關的故事吧。同樣是在A公司,有一次某政企私有云專案完成後,我們有人被派去給他們培訓如何使用。結果去的人回來後說政企意見很大,認為讓他們學習SQL以外的東西都不行。拒絕用Python寫UDF,更拒絕MR程式設計介面,只要SQL和圖形介面操作方式。一開始我對政企的這種行為有點看不起,但後來我想,就是因為有這群挑剔的使用者,才使得A公司雲產品的易用性如此強大,從而佔領國內雲端計算的大部分市場。使用者的需求才是技術的唯一試金石。
7. 資料庫管理和維護
嚴格來講,這部分不算開發流程,屬於資料庫系統開發完成後的工作。接下來本文將圍繞這個話題進行講解。
資料庫系統管理
資料庫系統發行後,控制權便從資料庫設計、實現、部署的團隊移交給了資料庫管理員(database administrator, DBA),並由他們來對系統進行管理。
資料庫管理涵蓋了確保一個已經部署的資料庫系統正確執行的各種行為。為了實現這一目標,資料庫管理具體包含以下範疇:
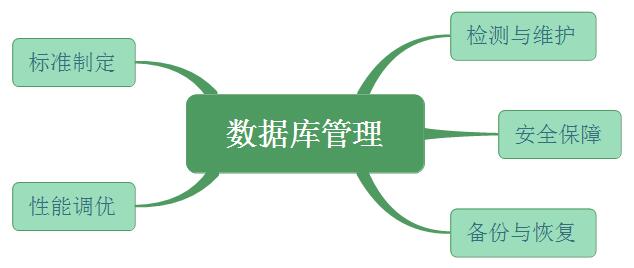
這部分工作的涉及面相當廣而深,應由專業的DBA團隊去完成。本文主要針對人群是資料科學家,因此僅對這些工作做一個簡明的介紹。
1. 資料庫系統監測與維護
監測工作可以讓DBA掌握資料庫系統的執行情況,並針對發現的問題進行維護。比如發現儲存資源不夠用了,則要分配給資料庫系統更多儲存空間等。
同時,監測工作也可以讓DBA知道關聯式資料庫中各關係的具體使用情況,從而進行優化。比如某兩個表被大群使用者頻繁使用,並只用來重複建立相同的報表。這時候DBA就可以考慮建議資料庫開發團隊反規範化設計的將這兩個表合併到一起。
維護工作是指DBA在監測到了問題後,採取的修復行為。比如上面提到的分配更多儲存空間,向資料系統加入新的關係(注: 資料庫開發設計人員決定是否加入關係,DBA負責建議加入和具體執行),都屬於維護範疇。
2. 資料庫安全保障
資料庫安全保障工作可以說是資料庫系統管理工作中的首要任務,該任務需要DBA對資料的存取過程嚴加控制。
具體點來說,就是要求DBA做好資料庫訪問人員的認證工作,並對所有使用者進行許可權劃分。
此外,對於特別敏感的資料,還應進行加密處理。這部分功能一些商業資料庫做得很好,比如Oracle。
3. 資料庫備份與恢復
這裡簡要說明一下資料庫備份與恢復的原理。我們知道,資料庫的資料,是存放到磁碟裡的。而計算機對資料的處理過程,都是先把資料從硬碟轉移到記憶體,處理完後再放回去。
而如果資料在記憶體中進行處理,還沒有將資料轉移回磁碟的時候,資料庫掛了的話就將導致資料丟失。因此RDBMS採用恢復日誌(recovery log)機制,先記錄更新操作要做的事情,比如那個資料被更新,更新前後的值,更新請求的使用者等,然後再做具體的更新操作。在更新日誌中可以設定"檢查點",之後DBA可使用它進行週期性副本備份。失效事件發生之後,DBA可以利用"檢查點"進行系統恢復:回滾(Roll Back)至指定檢查點狀態。
對於那種徹底性毀壞的情況,比如發生火災、地震等,可在多個不同物理站點上保留完全映象備份(complete mirrored backup)。這些副本需持續更新保證與資料庫系統一致。
4. 資料庫效能優化
效能優化工作包括設定索引,逆規範化,SQL優化等等。通常有QPS(query per second)等指標來衡量資料庫系統的優化效果。
這部分工作內容很多也比較雜,主要通過DBA管理RDBMS的查詢優化器完成。但對於資料庫的開發員和使用者來說,也多多少少要知道一點,比如寫Hive語句的時候需要靈活設定分割槽,避免資料傾斜等。這些具體環境的優化方案,本文篇幅有限就不一一講解了。
5. 資料庫標準制定
這部分工作包括資料庫中欄位命名規範,SQL編碼規範的制定等。除了這些開發標準,還有使用標準,比如使用資料庫的人需要遵守哪些有益於資料庫系統健康的行為規範。
資料質量體系
資料庫系統,以及接下一個系列要講的資料倉儲系統,都需要始終重視資料質量問題。用一句話概括,資料質量就是衡量資料能否真實、及時反映客觀世界的指標。
具體來說,資料質量包含以下幾大指標:
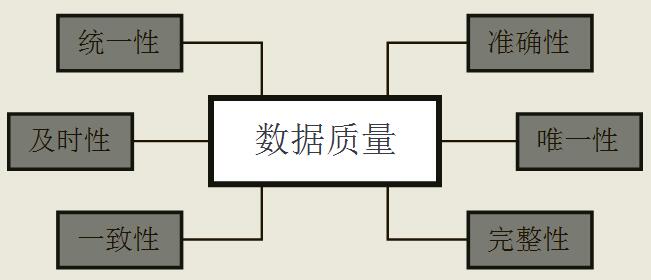
1. 準確性
準確性要求資料能夠正確描述客觀世界。比如某使用者姓名拼音mu chen錯誤的錄入成了muc hen,就應該彈出警告語;
2. 唯一性
唯一性要求資料不能被重複錄入,或者不能有兩個幾乎相同的關係。比如張三李四在不同業務環境下分別建立了近乎相同的關係,這時應將這兩個關係合併;
3. 完整性
完整性要求進行資料蒐集時,需求資料的被描述程度要高。比如一個使用者的購買記錄中,必然要有支付金額這個屬性;
4. 一致性
一致性要求不同關係、或者同一關係不同欄位的資料意義不發生衝突。比如某關係中昨天存貨量欄位+當天進貨量欄位-當天銷售量欄位不等於當天存活量,否則就可能是資料質量有問題;
5. 及時性
及時性要求資料庫系統中的資料"保鮮"。比如當天的購買記錄當天就要入庫;
6. 統一性
統一性要求資料格式統一。比如nike這個品牌,不能有的欄位描述為"耐克",而有的欄位又是"奈克";
資料質量和資料具體意義有很大相關性,因此無法單憑資料庫理論來保證。且由於具體業務及真實世界的複雜性,資料質量問題必然會存在,不可能完全預防得了。因此很多RDBMS或第三方公司都提供了資料質量工程服務/軟體,用來識別和校正資料庫系統中的各種資料質量問題。
小結
本篇作為資料庫系列的終篇,主要圍繞資料庫系統實現所涉及到的方方面面進行講解。想必讀者看完本文後會和我一樣,感受到一個完整而優秀的資料庫系統實現並不簡單,甚至可以說是比較繁瑣。雖說實際專案中每個人只需要專門負責其中一個或者幾個模組,不過筆者認為作為一名優秀的資料庫開發人員,也必須對全域性有一定的認識,這也是本文意義所在。
最後談點題外話吧。筆者本人是一名資料探勘工程師,看到很多朋友把精力完全投到研究資料探勘演算法和實現上,私以為這樣做是很不科學的。因為一個優秀的資料探勘引擎,必然架構在一個優秀的資料庫/資料倉儲系統之上。而一個資料探勘工程師80%的工作都是在利用這些系統進行資料清洗、特徵提取等,深入思考演算法模型的時間並不多(除非您是在特別牛的平臺性演算法團隊工作)。因此在深入學習資料探勘演算法之前,一定要有良好的資料基礎知識,不能好高騖遠。
下個系列的主題是資料倉儲,它和本系列,以及另幾個系列,如"資料視覺化_R語言","資料分析_Excel"一樣都是資料基礎知識的重要組成部分。期待各位讀者的持續關注、交流、指正。