測試眼裡的Hadoop系列 之Terasort
TeraSort是Hadoop的測試中很有用的一個工具,但以前只是粗略的知道它的功能和用法,簡單的用它做了幾個測試用例。實際上,對於這種比較通用的工具,如果能夠了解它更多一些的話,對於理解Hadoop是很有幫助的,同時也可以更好的利用它來幫助測試。最近有點時間,就瞭解了一些它的背景,程式碼實現原理等等,就先記錄下來吧。
1. Hadoop與Sort Benchmarks
SortBenchmark(http://sortbenchmark.org/ )是JimGray自98年建立的一項排序競技活動,它制定了不同類別的排序專案和場景,每年一次,決出各項排序演算法實現的第一名(看介紹是在每年的ACM SIGMOD頒發獎牌哦)。
Hadoop在2008年以209秒的成績獲得年度TeraSort項(Dotona類)的第一名;而此前這一項排序的記錄是297秒。
從SortBenchmark網站上可以瞭解到,Hadoop到今天仍然保持了Minute項Daytona型別排序的冠軍。Minute項排序是通過評判在60秒或小於60秒內能夠排序的最大資料量來決定勝負的;其實等同於之前的TeraSort(TeraSort的評判標準是對1T資料排序的時間)。
Hadoop原始碼中包含了TeraSort,打包在examples包(如:hadoop-0.20.2-examples.jar)。
2. 輸入資料:TeraGen
SortBenchmark對排序的輸入資料制定了詳細規則,要求使用其提供的gensort工具(http://www.ordinal.com/gensort.html )生成輸入資料。Hadoop的TeraSort也用Java實現了一個生成資料工具TeraGen,演算法與gensort一致。
對輸入資料的基礎要求是:輸入檔案是由一行行100位元組的記錄組成,每行記錄包括一個10位元組的Key;以Key來對記錄排序。
Minute項排序允許輸入檔案可以是多個檔案,但Key的每個位元組要求是binary編碼而不是ASCII編碼,也就是每個字元可能有256種可能,也就是說每條記錄,有2的80次方種可能的Key;
同時Daytona類別則要求排序程式不僅是為10位元組長Key、100位元組長記錄排序設計的,還可以支援對其他長度的Key或行記錄進行排序;也就是說這個排序程式是通用的。
在hadoop裡,利用TeraGen生成排序輸入資料的命令格式是這樣的:
$ bin/hadoop jar hadoop-0.19.2-examples.jar teragen 10000000000 /terasort/input1TB注意,teragen後的數值單位是行數;因為每行100個位元組,所以如果要產生1T的資料量,則這個數值應為1T/100=10000000000(10個0)。
生成的資料是這樣的:
!x'-n[Pp+l1049085170QQQQQQQQQQRRRRRRRRRRSSSSSSSSSSTTTTTTTTTTUUUUUUUUUUVVVVVVVVVVWWWWWWWWWWXXXXXXXX
r0JZ8-|o\)1049085171YYYYYYYYYYZZZZZZZZZZAAAAAAAAAABBBBBBBBBBCCCCCCCCCCDDDDDDDDDDEEEEEEEEEEFFFFFFFF
@Jp9XC#d/J1049085172GGGGGGGGGGHHHHHHHHHHIIIIIIIIIIJJJJJJJJJJKKKKKKKKKKLLLLLLLLLLMMMMMMMMMMNNNNNNNN
N)eM''3<pr1049085173OOOOOOOOOOPPPPPPPPPPQQQQQQQQQQRRRRRRRRRRSSSSSSSSSSTTTTTTTTTTUUUUUUUUUUVVVVVVVV
ryfUS$G1&y1049085174WWWWWWWWWWXXXXXXXXXXYYYYYYYYYYZZZZZZZZZZAAAAAAAAAABBBBBBBBBBCCCCCCCCCCDDDDDDDD
=i*nyMblSg1049085175EEEEEEEEEEFFFFFFFFFFGGGGGGGGGGHHHHHHHHHHIIIIIIIIIIJJJJJJJJJJKKKKKKKKKKLLLLLLLL
7I6>/,!~@@1049085176MMMMMMMMMMNNNNNNNNNNOOOOOOOOOOPPPPPPPPPPQQQQQQQQQQRRRRRRRRRRSSSSSSSSSSTTTTTTTT
#g{6{0Z;%\1049085177UUUUUUUUUUVVVVVVVVVVWWWWWWWWWWXXXXXXXXXXYYYYYYYYYYZZZZZZZZZZAAAAAAAAAABBBBBBBB
7</ioXV\It1049085178CCCCCCCCCCDDDDDDDDDDEEEEEEEEEEFFFFFFFFFFGGGGGGGGGGHHHHHHHHHHIIIIIIIIIIJJJJJJJJ
8in+{B{w'R1049085179KKKKKKKKKKLLLLLLLLLLMMMMMMMMMMNNNNNNNNNNOOOOOOOOOOPPPPPPPPPPQQQQQQQQQQRRRRRRRR
]Xq/CdFy%E1049085180SSSSSSSSSSTTTTTTTTTTUUUUUUUUUUVVVVVVVVVVWWWWWWWWWWXXXXXXXXXXYYYYYYYYYYZZZZZZZZ
:,/$4U]DIJ1049085181AAAAAAAAAABBBBBBBBBBCCCCCCCCCCDDDDDDDDDDEEEEEEEEEEFFFFFFFFFFGGGGGGGGGGHHHHHHHH每行記錄由3段組成:
- 前10個位元組:隨機binary code的十個字元,為key
- 中間10個位元組:行id
- 後面80個位元組:8段,每段10位元組相同隨機大寫字母
在這我其實有個小問題,因為排序是針對Key的,豈不是後面的Value只需要保證長度就可以,至於內容是什麼都沒關係麼?有人可能說隨機字母組成是為了避免壓縮時不均衡。但SortBenchmark是要求所有輸入檔案、輸出檔案、甚至中間傳輸過程的檔案都不允許使用壓縮的。不管怎麼說,對內容制定個規則,應該還是為了保證比賽公平性吧。
TeraGen作業沒有Reduce Task,產生檔案的個數取決於設定Map的個數。
3. TeraSort的原理
瞭解了我們需要排序的輸入資料是什麼樣了,接下來來了解TeraSort。
執行TeraSort的命令是這樣的:
$ bin/hadoop jar hadoop-0.19.2-examples.jar terasort /terasort/input1TB /terasort/output1TB檢視TeraSort的原始碼,你會發現這個作業同時沒有設定mapper和reducer;也就是意味著它使用了Hadoop預設的IdentityMapper和IdentityReducer。IdentityMapper和IdentityReducer對它們的輸入不做任何處理,將輸入k,v直接輸出;也就是說是完全是為了走框架的流程而空跑。
這正是Hadoop的TeraSort的巧妙所在,它沒有為排序而實現自己的mapper和reducer,而是完全利用Hadoop的Map Reduce框架內的機制實現了排序。
我們需要先來了解下Hadoop的Map Reduce過程,下圖較清楚的說明了這個過程。
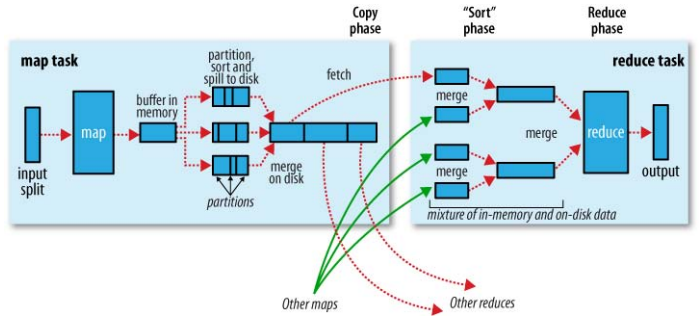
(這個圖非常經典,截自:Hadoop:The Definitive Guide)
恰好趁這個機會,把自己對MapReduce過程的理解簡要的整理一下:
- 一般情況下,作業會需要指定input目錄和output目錄
- 作業的Mapper根據設定的InputFormat來從input目錄讀取輸入資料,分成多個splits; 每一個split交給一個mapper處理
- mapper的輸出會按照partions分組,每一個partion對應著一個reducer的輸入; 在每個partion內,會有一個按key排序的過程,也就是說,每一個partion內的資料是有序的。
- 當處理完combiner和壓縮後(如果有設定),map的輸出會寫到硬碟上。map結束後,所在的TT會在下一個心跳通知到JT。
- 每一個reducer查詢JT瞭解到屬於自己對應partition的mapoutput資料的對應的TT位置,然後去那copy到本地(HTTP協議)。
- Copy並儲存到本地磁碟的過程同mapper端的輸出儲存過程非常相似。等到reducer獲取到屬於它的所有mapoutput資料後,它會保持之前mapper端的sort順序,把這些mapoutput合併成較集中的中間檔案(個數取決於資料大小和設定)。為了節省io的開銷,merge會保證最後一輪是滿負荷合併;並且,merge的最後一輪輸出會直接在記憶體輸入給reducer。
- reducer的輸出按照OutputFormat來儲存到output目錄。
如果我們注意到上述過程的藍色加粗部分,就可以猜測到TeraSort是如何利用hadoop的map reduce機制來達到排序目的的。或許我們可以懷疑,hadoop的Map Reduce機制就是為了TeraSort而設計的,:) 。
既然Hadoop可以保證每一個partition內的資料有序,TeraSort只需要做一件事情:保證partition之間也是有序的。
Hadoop預設的partitioner是HashPartitioner,它的實現是這樣的:
public classHashPartitioner<K2, V2> implements Partitioner<K2, V2> {
public void configure(JobConf job) {}
public int getPartition(K2 key, V2 value,
int numPartitions) {
return (key.hashCode() &Integer.MAX_VALUE) % numPartitions;
}
}它將每個Key的HashCode對總reducer數取模,轉換成partion index。
個人理解這樣做有兩個目的:
- 所有相同Key的資料在一個Reducer內處理
- 儘量均勻的將資料分配到各個Reducer
為了保證Partion之間的有序,TeraSort定義了一個TotalOrderPartitioner。
TotalOrderPartitioner首先要解決的問題是,partitioner發生在map裡,而每個mapper只處理它自己的一份split資料,它如何知道它所處理的資料在全域性所有輸入資料裡的位置?
回溯到源頭,InputFormat有資料的全域性觀。TeraSort定義的TeraInputFormat有一個重要的功能,就是把對全部資料形成一個摘要檔案,以提供給之後的partitioner使用。為了保證保證效率,TeraSort採用抽樣來實現摘要。
執行TeraSort後,它做的第一件事情是對輸入資料進行抽樣,抽樣頻率由設定項抽樣總條數terasort.partitions.sample決定,預設值為100000條。對輸入記錄分10個區間(或更小)來分批取樣,直到採到足夠條數;取樣完成後對這些抽樣點進行排序,然後對排序後記錄均分成partitions個區間,最終將這些區間分割點寫到檔案,檔名為_partition.lst。這個檔案會被加到distributed cache裡,目的是為了能被hadoop分發到將來執行mapper的每一個TT上去。
有了所有資料的摘要資訊,後面的partitioner做起來就有依據了。當它處理一條mapper的輸出記錄時,它可以按照一種對映演算法,依據每條記錄的Key與_partition.lst記錄的對應資訊做比較,將它劃分到某一個partition,從而保證partition之間的有序性。
假設我們從_partition.lst得到的Key組合為sample[];某一條記錄的Key值為key,如果查詢到sample[i-1] <= key < sample[i] , 那麼這條記錄會被分配到第i個partition,也就是第i個reducer來處理。這樣,partition之間也就有序了。
在TeraSort中,構建了一個trie來實現對Key的查詢歸類(Partitioner的過程其實就是歸類,然後把每一類交給一個reducer處理)。TeraSort預設使用2層的Trie,意味著它只用Key的前兩個位元組與與分割點比較; Trie的非葉子節點有256個子節點(對應著Key的每一個位元組的binary code,有256種可能)。
需要提到的是,TeraSort輸出的replica數設定是1份,而不是Hadoop預設使用的3份。為什麼?因為SortBenchmark沒有規定結果要存多份副本,而設定成1份,Hadoop會就近存在本地(如果這個reducer的TT上也同時有DN)。這可節省了不少網路和磁碟消耗,間接的提高了TeraSort的執行效率。
4. 結果的校驗:TeraValidate
TeraSort還帶有一個校驗程式,來檢驗排序輸出結果是否是有序的。TeraValidate是一個簡單的Map Reduce作業,大家看看Mapper和Reducer就好了。執行TeraValidate的命令是:
bin/hadoop jar hadoop-0.19.2-examples.jar teravalidate /terasort/output1TB /terasort/validate1TB如果有錯誤,log記錄會放在輸出目錄裡。
job.setLong("mapred.min.split.size", Long.MAX_VALUE);它用來保證每一個輸入檔案都不會被split,又因為TeraInputFormat繼承自FileInputFormat,所以TeraValidate執行mapper的總數正好等於輸入檔案的個數。
5. TeraSort與hadoop測試
TeraSort巧妙的利用了Hadoop的MapReduce機制來實現了Sort的目的,與Hadoop機制的完美結合也許是它優異排序成績的一個重要原因。而也正因為如此,我們可以在叢集上利用TeraSort來測試Hadoop,它將具有很高的測試利用價值。我稍微總結下,可以用TeraSort來測試的場景:
- 在不同版本Hadoop上執行TeraSort,使用相同的配置引數,來進行正確性對比測試
- 在不同版本Hadoop上執行TeraSort,使用相同的配置引數,來進行效能對比測試
- 在相同版本Hadoop上執行TeraSort,使用不同的配置引數,進行效能對比測試,發現問題
TeraSort只是一個小工具,比起生產應用作業,可能是微不足道了。但一個小工具,如果能夠挖掘到底,背後也會有大價值;尤其對測試來講,如果能夠對背景知識有更多的瞭解,一個小工具可以轉換成眾多方便且有價值的測試用例;並且,如果能對一個小工具舉一反三,也能夠為其他地方的測試提供價值。
相關文章
- Hadoop測試TeraSortHadoop
- hadoop基準測試_Hadoop TeraSort基準測試Hadoop
- Hadoop TeraSort 基準測試實驗Hadoop
- Hadoop TerasortHadoop
- Hadoop的TeraSort問題Hadoop
- hadoop的terasort排序總結Hadoop排序
- 大資料測試之hadoop初探大資料Hadoop
- Hadoop學習筆記 - Sort / TeraSort / TestDFSIOHadoop筆記
- Hadoop學習筆記之TeraSort修改後輸出翻倍異常Hadoop筆記
- Hadoop-MapReduce-TeraSort-大資料排序例子Hadoop大資料排序
- Hadoop TeraSort演算法之2-trie樹構造時間解惑Hadoop演算法
- 小白學習大資料測試之hadoop大資料Hadoop
- 2. TeraSort在Hadoop分散式叢集中的執行Hadoop分散式
- 軟體測試之資料庫測試技術系列七資料庫
- Google正測試一款智慧隱形眼鏡探尋眼淚中血糖之謎Go
- SQLTest系列之INSERT語句測試SQL
- 修改 Hadoop TeraSort演算法 —— 按照LongWritable型別的Key排序Hadoop演算法型別排序
- 人眼疲勞檢測之opencv人眼檢測xml說明OpenCVXML
- 小白測試系列:介面測試與效能測試的區別
- 介面測試裡的查詢介面要測試嗎
- USB 幾種常規眼圖測試
- Hadoop測試常見問題和測試方法Hadoop
- 軟體測試之資料庫系列六資料庫
- 軟體測試之資料庫系列五資料庫
- 軟體測試之資料庫系列四資料庫
- 軟體測試之資料庫系列三資料庫
- 軟體測試之資料庫系列二資料庫
- 軟體測試之資料庫系列一資料庫
- ASP.NET 系列:單元測試之SmtpClientASP.NETclient
- ASP.NET 系列:單元測試之StructureMapASP.NETStructREM
- hadoop2.4.1_WordCount測試Hadoop
- 貓眼測試開發實踐沉澱--Chaoyue測試管理平臺
- 介面自動化測試系列之PHPUnit-GET請求介面測試方法PHP
- app 裡的 A/B 測試簡介APP
- Spark 與 Hadoop 關於 TeraGen/TeraSort 的對比實驗(包含原始碼)SparkHadoop原始碼
- 軟體效能測試常見指標。在哪裡測試測試?指標
- 小丸子學Hadoop系列之——部署Hadoop叢集Hadoop
- 測試平臺系列(63) 軟刪除之殤