閱讀思路:
1、原始碼編譯
2、功能如何使用
3、實現原理
4、原始碼閱讀(通讀+記錄+分析)
原始碼結構
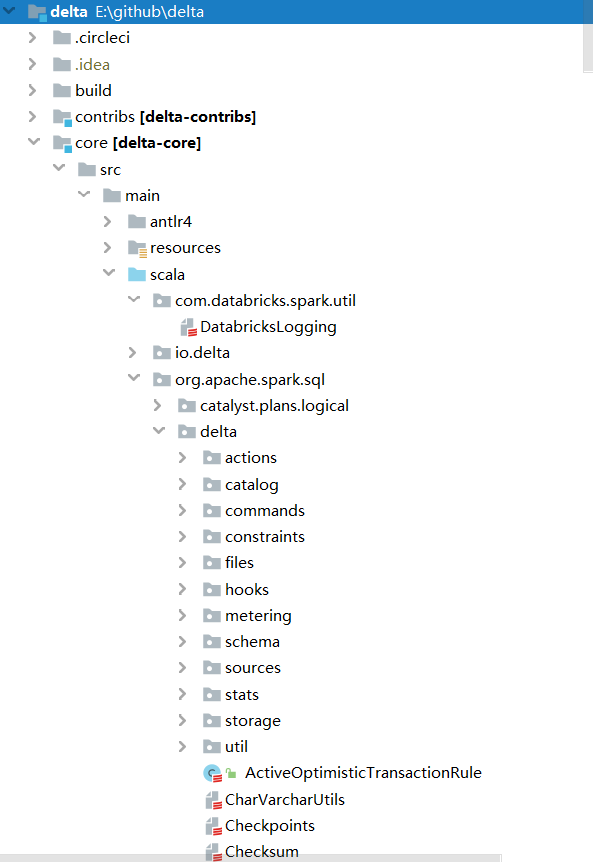
原始碼分析
後設資料
位置:org.apache.spark.sql.delta.actions下的actions檔案
Protocol: 當對協議進行向後不相容的更改時,用於阻止舊客戶端讀取或寫入日誌。在執行任何其他操作之前,readers和writers負責檢查它們是否滿足最低版本
SetTransaction: 設定給定應用程式的提交版本
AddFile: 往table中新增一個新檔案
RemoveFile: 從儲存庫中邏輯刪除給定檔案
AddCDCFile: 一個包含CDC資料的變化檔案
Metadata: 表的後設資料資訊
CommitInfo: 儲存有關表更改的來源資訊
事務
位置:org.apache.spark.sql.delta.OptimisticTransaction
關鍵方法:
def commit(actions: Seq[Action], op: DeltaOperations.Operation): Long = recordDeltaOperation(
deltaLog,
"delta.commit") {
...
}
主要分成以下三步:
- prepareCommit
- doCommitRetryIteratively
- postCommit
prepareCommit
提交之前對協議版本、後設資料合法性、一次事務中後設資料改動次數等actions進行校驗,並進行相應的改變,返回最終通過的actions。
doCommitRetryIteratively
儲存為hdfs
方法名:doCommitRetryIteratively
入參:
- attemptVersion: 嘗試提交的版本
- actions:要提交的actions
- isolationLevel:隔離級別(一共三種,這裡只用到SnapshotIsolation或者Serializable),若資料會改變則使用Serializable,否則SnapshotIsolation
邏輯:
- 嘗試第一次提交:doCommit,將actions寫入delta log對應的目錄中,先建立一個臨時檔案,再進行重新命名,因為hdfs rename是原子操作,不需要加鎖,若目標檔案已存在,則提交失敗,丟擲異常
- 若提交失敗,則進行固定次數的重試。在重試提交之前會進行邏輯上的衝突檢查(checkForConflicts),若檢查通過會返回nextAttemptVersion,再進行提交。
- 提交成功,則返回當前提交的版本號。
重要方法:
方法名:checkForConflicts
入參:
- checkVersion:上一次提交失敗的版本號
- actions:要提交的actions
- attemptNumber:嘗試次數
- commitIsolationLevel:SnapshotIsolation\Serializable
邏輯:
- 獲取nextAttemptVersion。執行 deltaLog.update(),這裡stalenessAcceptable預設是false,所以需要加鎖同步執行 updateInternal,通過currentSnapshot中的checkpointVersion獲取對應的chk型別檔案及其之後的delta型別檔案,從這些檔案中篩選出最新完成的chk及其之後的delta檔案,處理後返回LogSegment物件;接著建立新的snapshot,並替換掉當前的snapshot;將此時snapshot中的version加1作為nextAttemptVersion。
- 檢查衝突,成功則返回nextAttemptVersion。從上一次提交失敗的版本號開始迴圈直到上一步中獲取的nextAttemptVersion,獲取在nextAttemptVersion之前的版本對應的要提交的actions,將其分為metadataUpdates、removedFiles、txns、protocol、commitInfo這些action,分別進行併發衝突的判斷。詳細併發衝突型別見:https://docs.delta.io/latest/concurrency-control.html#conflict-exceptions
postCommit
執行提交後的動作。如果需要進行checkpoint,即提交的版本不等於0並且對chk間隔取餘等於0,則進行chk,跟據提交的版本建立snapshot,之後呼叫 Checkpoints.writeCheckpoint 生成對應的CheckpointMetaData物件,接著寫入hdfs,最後,如果開啟了過期日誌清理,則判斷已過期的日誌進行刪除。
呼叫commit的操作
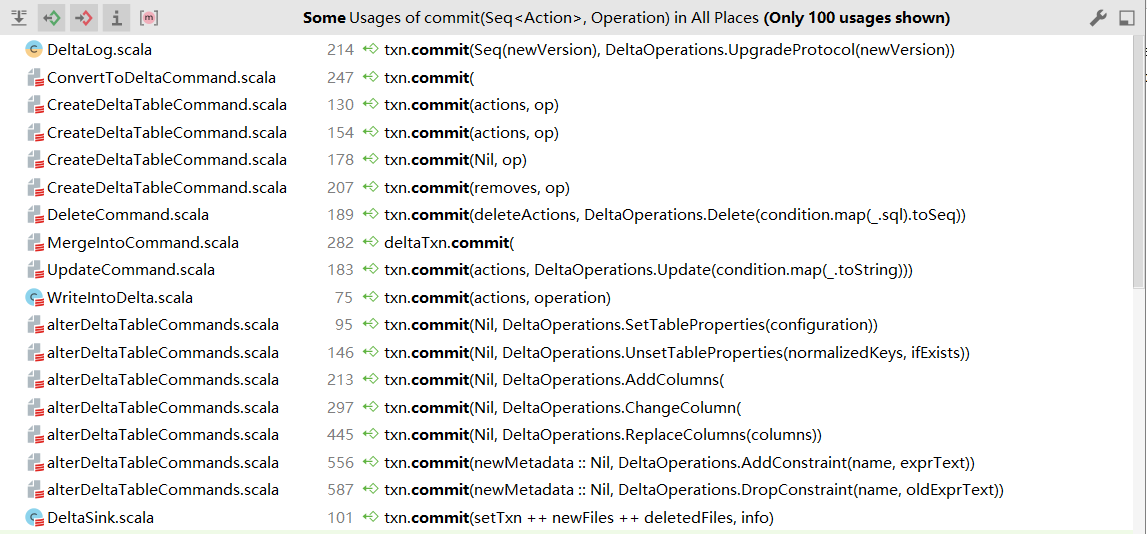
Table deletes, updates, and merges
deletes
方法名:以 delete(condition: String) 為例
一個問題:如何將delete logical plan轉到DeleteCommand?
=>delta通過繼承Rule來實現,如下圖程式碼。
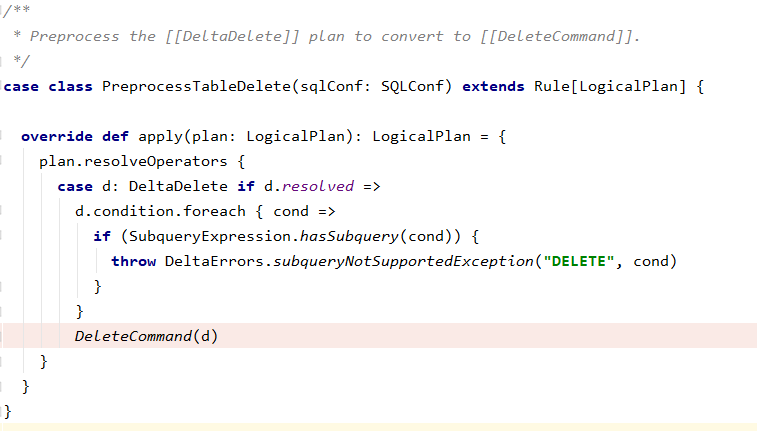
執行DeleteCommand run方法
final override def run(sparkSession: SparkSession): Seq[Row] = {
recordDeltaOperation(tahoeFileIndex.deltaLog, "delta.dml.delete") {
val deltaLog = tahoeFileIndex.deltaLog
deltaLog.assertRemovable()
deltaLog.withNewTransaction { txn =>
performDelete(sparkSession, deltaLog, txn)
}
// Re-cache all cached plans(including this relation itself, if it's cached) that refer to
// this data source relation.
sparkSession.sharedState.cacheManager.recacheByPlan(sparkSession, target)
}
Seq.empty[Row]
}
通過deltaLog.withNewTransaction保證刪除的原子性,在事務中執行performDelete方法
方法名:deltaLog.withNewTransaction
- 執行startTransaction。更新當前的snapshot,獲取到表最新資訊,並返回OptimisticTransaction
- 將該OptimisticTransaction用ThreadLocal包裝起來,保證可見性
- 將OptimisticTransaction作為入參,呼叫performDelete方法
方法名:performDelete
- 若刪除時沒有條件,則返回所有的AddFile;若有條件,則繼續根據分割槽列將條件拆分為後設資料的條件(根據分割槽過濾)和其他條件。
- 若其他條件是空的,則意味著不需要掃描任何資料檔案,直接根據分割槽篩選出要刪除的檔案集合;否則,先找出待刪除的分割槽檔案,接著保留原始的target(LogicalPlan),替換得到newTarget,只包含待刪除的AddFile,然後根據newTarget獲取到DataFrame,再通過條件過濾得到需要重寫的檔案。
- 若無需要重寫的檔案,則不需要進行刪除,返回空;否則,替換建立新的newTarget,獲取到DF,過濾得到不需要刪除的DF(updatedDF),重新寫入檔案(txn.writeFiles(updatedDF)),返回所有的RemoveFile和AddFile
- 如果deleteActions不是空,則進行事務commit
updates
方法名:以update(condition: Column, set: Map[String, Column])為例
執行UpdateCommand run方法
final override def run(sparkSession: SparkSession): Seq[Row] = {
recordDeltaOperation(tahoeFileIndex.deltaLog, "delta.dml.update") {
val deltaLog = tahoeFileIndex.deltaLog
deltaLog.assertRemovable()
deltaLog.withNewTransaction { txn =>
performUpdate(sparkSession, deltaLog, txn)
}
// Re-cache all cached plans(including this relation itself, if it's cached) that refer to
// this data source relation.
sparkSession.sharedState.cacheManager.recacheByPlan(sparkSession, target)
}
Seq.empty[Row]
}
方法名:performUpdate
- 獲取candidateFiles。根據後設資料條件和資料條件過濾得到candidateFiles。
- 如果candidateFiles為空,則返回Nil;否則如果資料條件為空,則需要更新指定分割槽檔案中的所有行,先獲取所有檔案路徑,根據條件重寫檔案中的所有row,得到rewrittenFiles(AddFile),將candidateFiles中元素更新為RemoveFile,返回deleteActions和rewrittenFiles合併的結果actions;如果資料條件不為空,根據指定條件找出所有受影響的檔案filesToRewrite,如果filesToRewrite為空,則返回Nil,否則刪除filesToRewrite中包含的檔案,根據條件重寫檔案中的所有row,得到rewrittenFiles(AddFile),返回deleteActions和rewrittenFiles合併的結果actions
- 如果actions不為空,則進行事務提交
merges
示例如下:
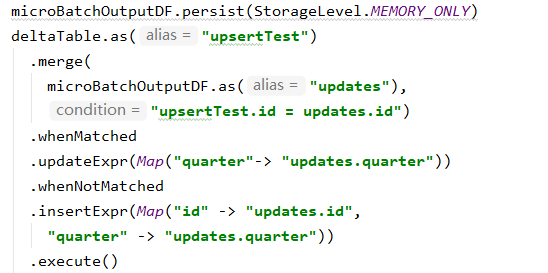
呼叫的方法為:DeltaMergeBuilder.execute()
最終執行方法:MergeIntoCommand.run()
邏輯:
- 如果可以合併schema,則更新後設資料資訊,否則不更新。詳見:https://docs.delta.io/latest/delta-update.html#automatic-schema-evolution
- 如果只進行插入並且此時允許優化,則進入 writeInsertsOnlyWhenNoMatchedClauses,避免重寫舊檔案,只插入新檔案。獲取目標輸出的對應列的表示式集合,獲取源表的DF,根據merge的條件只獲取目標表中需要的檔案並轉化成目標表的DF,將源表DF和目標表DF通過leftanti進行join篩選出需要寫入的DF,最後寫入新的檔案中,返回action集合deltaActions
- 否則,走正常merge邏輯。1) 先找到需要重寫的檔案filesToRewrite:通過將源表DF和目標表DF進行inner join得到joinToFindTouchedFiles,從中篩選出需要的列(行id、檔名id)的DF,根據行id進行分組求和,統計求和結果大於1的個數記為multipleMatchCount;如果匹配條件的size大於1且是無條件的刪除,則即使multipleMatchCount的值大於0也可以正常計算,否則丟擲異常。通過檔案路徑找到對應的AddFile並返回。2)寫入所有的變化。1)獲取目標輸出列,並由此生成新的LogicalPlan,併為輸出列建立別名,從而得到新的目標plan。2)如果只有匹配上的條件且允許調優,則join的型別為rightouter,否則為fullouter;將源表DF與目標DF進行join。3)通過join後的plan獲取到rows,對其進行mapPartitions操作,執行JoinedRowProcessor中的processPartition,獲取輸出的DF,寫入delta表,返回action集合newWrittenFiles。4)將filesToRewrite轉化為RemoveFile,並與newWrittenFiles組合後返回deltaActions
- 提交事務。
重要方法:processPartition
準備
right outer join:參與 Join 的右表資料都會顯示出來,而左表只有關聯上的才會顯示,否則為null。
full outer join:左右表都會顯示,但是如果沒有關聯時會顯示,否則左右表會有一個顯示為null。
def processPartition(rowIterator: Iterator[Row]): Iterator[Row] = {
val targetRowHasNoMatchPred = generatePredicate(targetRowHasNoMatch)
val sourceRowHasNoMatchPred = generatePredicate(sourceRowHasNoMatch)
val matchedPreds = matchedConditions.map(generatePredicate)
val matchedProjs = matchedOutputs.map(generateProjection)
val notMatchedPreds = notMatchedConditions.map(generatePredicate)
val notMatchedProjs = notMatchedOutputs.map(generateProjection)
val noopCopyProj = generateProjection(noopCopyOutput)
val deleteRowProj = generateProjection(deleteRowOutput)
val outputProj = UnsafeProjection.create(outputRowEncoder.schema)
def shouldDeleteRow(row: InternalRow): Boolean =
row.getBoolean(outputRowEncoder.schema.fields.size)
def processRow(inputRow: InternalRow): InternalRow = {
if (targetRowHasNoMatchPred.eval(inputRow)) {
// Target row did not match any source row, so just copy it to the output
noopCopyProj.apply(inputRow)
} else {
// identify which set of clauses to execute: matched or not-matched ones
val (predicates, projections, noopAction) = if (sourceRowHasNoMatchPred.eval(inputRow)) {
// Source row did not match with any target row, so insert the new source row
(notMatchedPreds, notMatchedProjs, deleteRowProj)
} else {
// Source row matched with target row, so update the target row
(matchedPreds, matchedProjs, noopCopyProj)
}
// find (predicate, projection) pair whose predicate satisfies inputRow
val pair = (predicates zip projections).find {
case (predicate, _) => predicate.eval(inputRow)
}
pair match {
case Some((_, projections)) => projections.apply(inputRow)
case None => noopAction.apply(inputRow)
}
}
}
val toRow = joinedRowEncoder.createSerializer()
val fromRow = outputRowEncoder.createDeserializer()
rowIterator
.map(toRow)
.map(processRow)
.filter(!shouldDeleteRow(_))
.map { notDeletedInternalRow =>
fromRow(outputProj(notDeletedInternalRow))
}
}
邏輯:(左表為source,右表為target)
- 遍歷join後的分割槽rows,進入processRow方法。1)如果目標row沒有匹配上任何源表的row,即只有右表,左表為null,則直接把輸入進行輸出;2)當左表有值,右表為null,則是未能匹配上,插入左表中對應的資料;3)當左右表都有時,則說明匹配上了,更新右表的row
join後如下表:
|
source |
target |
op |
|
null |
have value |
直接把輸入進行輸出 |
|
have value |
null |
notMatched+插入左表中對應的資料 |
|
have value |
have value |
matched+更新右表的row |