很多的JavaScript工具都需要對JavaScript原始碼進行轉換,包括壓縮器(minifier)和轉譯器(transpiler).這些工具所使用的轉換的技術可以分為兩種:對原始碼進行非破壞式的(non-destructive)修改和從語法樹完全再生(full regeneration)出新的原始碼.這兩種技術服務於不同的需求,且往往是相輔相成的.
無論選擇哪種技術,輸入的原始碼都需要先被解析.這項任務可以交給一個解析器(比如Esprima)來做.之後,再對解析器生成的語法樹進行兩種不同的操作,如下圖所示:
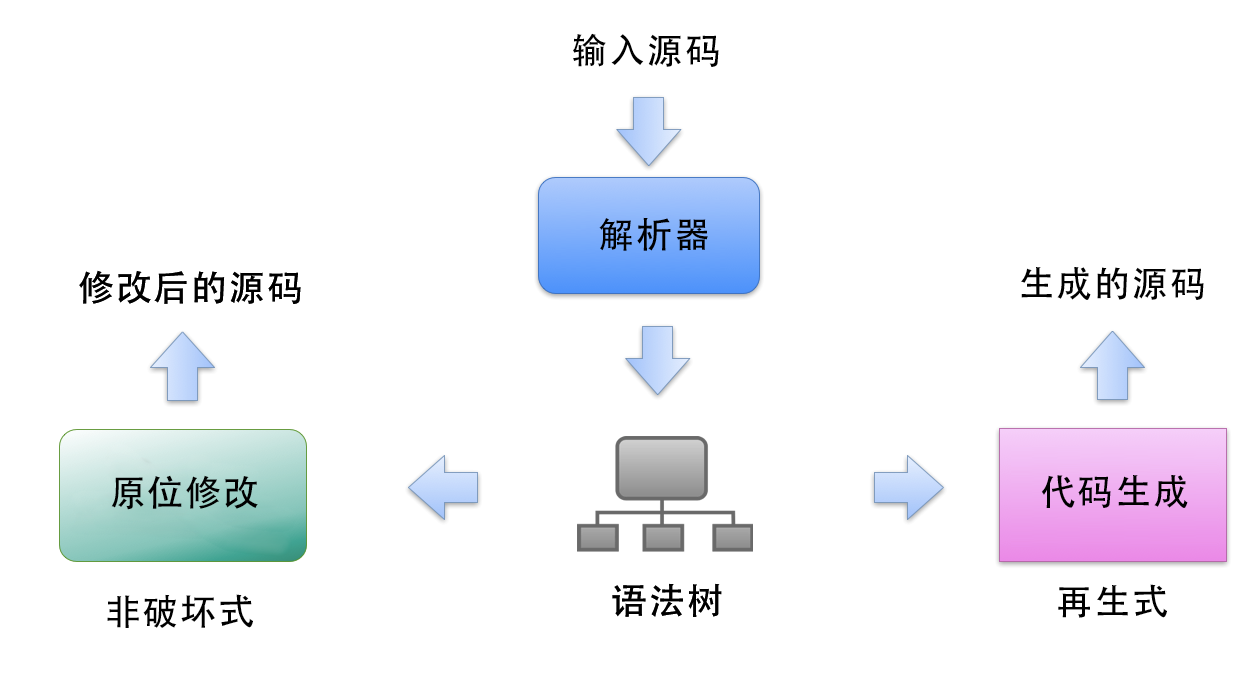
如果使用非破壞式的修改,則我們需要利用語法樹中相關語法節點(syntax node)和詞法單元(tokens)的位置資訊來計算出應該在輸入原始碼的哪段位置處進行修改.舉個簡單的例子,就是把原始碼中字串兩邊的雙引號轉換成單引號(或者反或來):通過定位字串字面量,我們就能知道引號的具體位置,從而能夠對這個引號進行原位替換(in-place replacement),注意字串本身的內容可能需要轉義,因為其中可能包含引號.
完全再生的方式可以用在語法轉譯(syntax transpilation)的需求中.比如,如果我們現在就想使用上ECMAScript 6中的塊級作用域(block scope)特性,則我們需要對自己寫的程式碼進行轉換(已經有了現成的defs.js),讓輸出的程式碼能夠正確的執行在目前更通用的ECMAScript 5環境中.具體要做的就是將let宣告語句轉換成等效的var語句(主要考慮如何對變數的作用域進行限制).
非破壞式轉換的優點是,我們不會丟失那些輸入原始碼中與語法無關且不影響程式執行但也有必要保留的那部分程式碼.比如,在將雙引號轉換成單引號這一需求中,所有已有的縮排,註釋等應當被完全保留.非破壞式轉換工具只對它感興趣的部分程式碼做修改,其他的所有程式碼都應該保持完全不變.
但如果我們想要編寫的這個工具不需要保留輸入原始碼中的註釋和縮排,則完全扔掉原始程式碼,根據語法樹生成一份新原始碼的方式會更簡單點.比如,一個壓縮器生成的原始碼從語義上要完全等同於輸入原始碼,只是少了額外的空白,就應該使用完全再生的方式.另外現在大部分高階壓縮器還會去做一些縮短變數名,移除無用程式碼的一些處理,因為這些處理能讓程式碼變的更短.
譯者注:目前比較有名的三個壓縮器YUI Compressor, Closure Compiler, UglifyJS都是使用再生的方式生成原始碼的.不過前兩者使用的解析器是Mozilla的Rhino(Java編寫),後者使用的解析器是parse-js(JavaScript編寫).
Esprima作為目前最好的js parser in js,怎麼會沒有基於Esprima的壓縮器呢.於是我諮詢了本文的作者,也就是Esprima的作者,他讓我看看Escodegen和Esmangle.其中,Escodegen是一個程式碼生成器,可以把AST轉換成JavaScript程式碼,剛好乾了和解析器相反的工作,這裡有一個demo.Esmangle是一個壓縮器,但它和其他的壓縮器不同,它的輸入是解析器生成的AST,返回的是壓縮過的AST,也就是說Esprima + Esmangle + Escodegen配合在一起,才能算是完整的JavaScript程式碼壓縮器,這裡有一個demo.
如果要做程式碼覆蓋率分析,則程式碼插裝(code instrumentation)是最重要的一步操作.一個程式碼覆蓋率工具比如Istanbul會把它的插裝程式碼(instrumentation code)包裝在目的碼的每個語法節點上.通過這種方式,就可以跟蹤到那些真正被JavaScript引擎執行過的語句和程式碼分支了.這樣的插裝器(instrumenter)也是程式碼再生技術的又一個用武之地.在程式碼插裝完畢之後,新生成的程式碼馬上就要被直譯器執行了,也就沒有人會去關心程式碼長什麼樣,有沒有縮排等外觀方面的事情了.
譯者注:講一個我自己的真實案例,情節稍有簡化.就是在公司的專案中,需要在js檔案中拼接mastache模板字串,像這樣
var template =
'<ul>' + '{{#list}}' +
'<li>' +
'{{value}}' +
'</li>' + '{{/list}}' +
'</ul>' +
......顯然,這種寫法可維護性不好.於是我想出了一種解決辦法,就是利用提取函式多行註釋來實現多行字串.像這樣
var template = heredoc(function(){/* <ul> {{#list}} <li> {{value}} </li> {{/list}} </ul>
...... */})兩種寫法下template的值應該是一樣的.heredoc是一個工具函式,負責從引數函式的source裡提取出多行註釋作為字串,怎麼實現的我這裡就不說了.
重點是,在釋出的時候,這樣的程式碼會經過UglifyJS的壓縮.註釋被刪除,程式錯誤,這是可以預料到的.於是我寫了一個node指令碼,負責在釋出的時候把所有js檔案中的heredoc函式的呼叫轉換成單行的字串,轉換之後的程式碼就變成了
......
var template = '<ul>{{#list}}<li>{{value}}</li>{{/list}</ul>'
......省略號代表了其他部分的程式碼,是不會有任何修改的.下一步再交給UglifyJS壓縮,這樣就沒問題了.
這個node指令碼是怎麼寫的,我正是用到了本文中所講的非破壞式修改原始碼的技術,使用的解析器是Esprima.其程式碼比起雙引號轉單引號的那個例子要複雜一些,只遍歷tokens陣列是不夠的,需要遍歷整棵語法樹以及comments陣列.完整的程式碼如下
還有個瀏覽器中的demovar fs = require("fs"); var path = process.argv[2]; var esprima = require("esprima"); var source = fs.readFileSync(path, "utf-8"); var ast = esprima.parse(source, { //將原始碼解析成ast comment: true, //把所有的註釋節點放到ast.comments陣列內 range: true //輸出所有語法節點的位置資訊 }); var collectedDatas = []; JSON.stringify(ast, function (key, value) { //遍歷所有的語法節點,找到heredoc的函式呼叫,抽取出多行註釋 if (value && value.type === "CallExpression" && value.callee.name === "heredoc" && value.arguments.length === 1 && value.arguments[0].type === "FunctionExpression" && value.arguments[0].body.body.length === 0) { //找到heredoc函式呼叫,且引數必須是一個不包含任何語句的空函式 var heredocCallExpression = value; var blockStatementRange = heredocCallExpression.arguments[0].body.range; var blockStatementSource = source.slice(blockStatementRange[0] + 1, blockStatementRange[1] - 1); var offsetLeft = blockStatementSource.match(/^\s*/)[0].length; var offsetRight = blockStatementSource.match(/\s*$/)[0].length; var commentRange = [blockStatementRange[0] + offsetLeft + 1, blockStatementRange[1] - offsetRight - 1]; //假設這個空函式只包含一個多行註釋,計算出該註釋的位置資訊 ast.comments.some(function (comment) { //和解析出來的comments陣列做對比,如果有相同位置資訊的,則說明已經正確定位到了一個約定好的多行字串寫法 if (comment.range[0] == commentRange[0] && comment.range[1] == commentRange[1]) { var commentSourceRange = [commentRange[0] + 2, commentRange[1] - 2]; var commentSource = source.slice(commentSourceRange[0], commentSourceRange[1]); var escapedCommentSource = ("'" + commentSource.replace(/(?=\\|')/g, "\\") + "'").replace(/\s*^\s*/mg, ""); collectedDatas.push({ range: heredocCallExpression.range, replaceString: escapedCommentSource }); } }); } return value; }) for (var i = collectedDatas.length - 1; i >= 0; i--) { //從後往前修改輸入原始碼,就可以不用考慮偏移量的問題了 var range = collectedDatas[i].range; var replaceString = collectedDatas[i].replaceString; source = source.slice(0, range[0]) + replaceString + source.slice(range[1]); } fs.writeFileSync(path, source, "utf-8"); //將修改後的原始碼寫回原始檔