Python3.X 爬蟲實戰(併發爬取)
【工匠若水 http://blog.csdn.net/yanbober 未經允許嚴禁轉載,請尊重作者勞動成果。私信聯絡我】
1 背景
在這一系列開始前我們就說過,簡單的爬蟲很容易,但是要完成一個高效健壯的爬蟲不是一個簡單的事情,這一系列我們已經明白了爬蟲相關的如下核心知識點。
《正規表示式基礎》
《Python3.X 爬蟲實戰(先爬起來嗨)》
《Python3.X 爬蟲實戰(靜態下載器與解析器)》
基於上面這幾篇其實我們把爬蟲當作自己便利的開發工具來使用基本上是夠了(譬如老闆讓你定期留意觀察自己做的應用功能上線後的使用者行為資料,方便開發把握功能潛在風險,這個其實我們就可以寫個 Python 爬蟲小程式去後臺定期查,然後定期郵件傳送到我的郵箱,這樣就不用自己老記著這回事然後去上網頁操作了),但是對於動態網頁爬取我們還未探討、對於爬取資料處理我們也沒探討、對於爬取效能問題我們也沒探討。。。我靠,還有很多東西等待我們去發掘,MLGB,那我們這一篇就先探討下 Python 爬蟲的併發爬取,其實就是 Python 的併發,嗚嗚!
之所以討論這個話題是為了解決《Python3.X 爬蟲實戰(靜態下載器與解析器)》一文中 LXml 解析爬取美圖錄美女圖片網站的效率問題,你會發現我們上一篇中那個程式的執行效率非常低,爬取完那些妹子圖需要很就,因為他們是順序的,加上我們還沒有對妹子圖網站進行全站爬取,如果要全站爬取那就是個相當恐怖的事情了,不信我們可以通過《Python3.X 爬蟲實戰(先爬起來嗨)》一文介紹的 site 方式檢視這個站點有多少頁面可以爬取,如下:
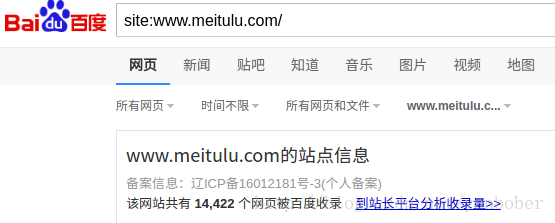
這還不算特別多,但我們已經無法忍受這麼慢的爬取速度了,所以我們就要想辦法解決這個問題,也就是這一篇要探討的問題,不過首先你得具備 Python 併發程式設計的基礎,如果還不 OK 可以看看知乎上 Python 之美的 Python 併發程式設計系列文章,講的不錯,或者去看看 Python 核心程式設計一書。

【工匠若水 http://blog.csdn.net/yanbober 未經允許嚴禁轉載,請尊重作者勞動成果。私信聯絡我】
2 Python 3.X 併發鋪墊
其實這一小節沒必要存在的,但是為了補全就列出來了(注意:如果自己具備併發基礎就直接移步 Part3 併發爬蟲實戰)。對於程式的程式、執行緒關係及區別的概念其實是不區分具體程式語言的,也就說如果我們過去在計算機基礎、Unix 高階 C 語言程式設計、Java 程式設計、Android 程式設計等學習過程式與執行緒的概念,那麼 Python 的併發也就好理解了,唯一區別是他們的語法和 API 名字及用法不同而已。
Python3 使用 POSIX 相容的(pthreads)執行緒,提供了多個多執行緒程式設計模組,譬如 _thread、threading、Queue、concurrent.futures 包等,其中 _thread、threading 允許我們建立管理執行緒,主要區別就是 _thread (以前 Python 中的 thread,Python3 中已經不能再使用 thread 模組,為了相容 Python3 將它重新命名為 _thread 了)只提供了基本的執行緒及鎖支援;而 threading 提供了更加牛逼的執行緒管理機制;Queue 為我們提供了一個用於多執行緒共享資料的佇列;concurrent.futures包從 Python3.2 開始被納入了標準庫,其提供的ThreadPoolExecutor 和 ProcessPoolExecutor 是對 threading 和 multiprocessing 的高階抽象,暴露統一的介面來方便實現非同步呼叫。
2-1 Python 3.X _thread 模組
這是個備受大家拋棄的 Python 併發模組,在 Python 低版本中叫 thread,高版本為了相容叫 _thread,但是不推薦使用了,具體不推薦的原因大致如下:
- _thread 模組的同步原語只有一個,比較弱,threading 卻有很多;
- _thread 模組之後出現了更加高階的 threading,你說你選哪個呢;
- 不支援守護執行緒等,使用 _thread 模組對於程式該何時結束基本無法控制(主執行緒結束後所有執行緒被沒有任何警告和清理的情況下強制結束),而 threading 模組基本可以保證重要子執行緒結束後才退出主執行緒;
說到底就是因為我是個渣渣,駕馭不了 _thread 模組,哈哈,所以我無恥的選擇了 threading 模組;多說無用,直接給段程式碼演示下吧,這段程式碼在各種語言的多執行緒中都是經典,沒啥特殊的,如下:
[本例項完整原始碼點我獲取 demo_thread.py]
import _thread
import time
'''
Python 3.X _thread 模組演示 Demo
當註釋掉 self.lock.acquire() 和 self.lock.release() 後執行程式碼會發現最後的 count 為 467195 等隨機值,併發問題。
當保留 self.lock.acquire() 和 self.lock.release() 後執行程式碼會發現最後的 count 為 1000000,鎖機制保證了併發。
time.sleep(5) 就是為了解決 _thread 模組的詬病,註釋掉的話子執行緒沒機會執行了
'''
class ThreadTest(object):
def __init__(self):
self.count = 0
self.lock = None
def runnable(self):
self.lock.acquire()
print('thread ident is '+str(_thread.get_ident())+', lock acquired!')
for i in range(0, 100000):
self.count += 1
print('thread ident is ' + str(_thread.get_ident()) + ', pre lock release!')
self.lock.release()
def test(self):
self.lock = _thread.allocate_lock()
for i in range(0, 10):
_thread.start_new_thread(self.runnable, ())
if __name__ == '__main__':
test = ThreadTest()
test.test()
print('thread is running...')
time.sleep(5)
print('test finish, count is:' + str(test.count))所以很直觀的看見咯,確實值得唾棄,我們還是看看 threading 吧。
2-2 Python 3.X threading 模組
關於 threading 模組提供的物件其實我們可以直接看看 threading.py 原始碼的__all__定義,裡面有具體列舉,如下:
__all__ = ['get_ident', 'active_count', 'Condition', 'current_thread',
'enumerate', 'main_thread', 'TIMEOUT_MAX',
'Event', 'Lock', 'RLock', 'Semaphore', 'BoundedSemaphore', 'Thread',
'Barrier', 'BrokenBarrierError', 'Timer', 'ThreadError',
'setprofile', 'settrace', 'local', 'stack_size']看了這個定義和官網 API 後順手搜到這篇文章不錯(點我檢視),感興趣的可以自己去琢磨下咯,下面我們先給出 threading 模組下 Thread 類的一般用法,如下:
[本例項完整原始碼點我獲取 demo_threading.py]
import threading
from threading import Thread
import time
'''
Python 3.X threading 模組演示 Demo
threading 的 Thread 類基本使用方式(繼承重寫 run 方法及直接傳遞方法)
'''
class NormalThread(Thread):
'''
重寫類比 Java 的 Runnable 中 run 方法方式
'''
def __init__(self, name=None):
Thread.__init__(self, name=name)
self.counter = 0
def run(self):
print(self.getName() + ' thread is start!')
self.do_customer_things()
print(self.getName() + ' thread is end!')
def do_customer_things(self):
while self.counter < 10:
time.sleep(1)
print('do customer things counter is:'+str(self.counter))
self.counter += 1
def loop_runner(max_counter=5):
'''
直接被 Thread 呼叫方式
'''
print(threading.current_thread().getName() + " thread is start!")
cur_counter = 0
while cur_counter < max_counter:
time.sleep(1)
print('loop runner current counter is:' + str(cur_counter))
cur_counter += 1
print(threading.current_thread().getName() + " thread is end!")
if __name__ == '__main__':
print(threading.current_thread().getName() + " thread is start!")
normal_thread = NormalThread("Normal Thread")
normal_thread.start()
loop_thread = Thread(target=loop_runner, args=(10,), name='LOOP THREAD')
loop_thread.start()
loop_thread.join()
normal_thread.join()
print(threading.current_thread().getName() + " thread is end!")怎麼樣,最直接的感觸就是再也不用像 _thread 那樣讓主執行緒預估結束時間等待子執行緒結束,使用 Thread 類以後直接可以使用 join 方式等待子執行緒結束,當然還有別的方式,自己可以琢磨;我們會發現其兩種寫法和 Java 執行緒非常類似,很棒,下面我們再給出簡單的同步鎖處理案例,如下:
[本例項完整原始碼點我獲取 demo_threading_lock.py]
'''
Python 3.X threading 模組演示 Demo
threading 鎖同步機制
當註釋掉 self.lock.acquire() 和 self.lock.release() 後執行程式碼會發現最後的 count 為 467195 等,併發問題。
當保留 self.lock.acquire() 和 self.lock.release() 後執行程式碼會發現最後的 count 為 1000000,鎖機制保證了併發。
'''
import threading
from threading import Thread
class LockThread(Thread):
count = 0
def __init__(self, name=None, lock=None):
Thread.__init__(self, name=name)
self.lock = lock
def run(self):
self.lock.acquire()
print('thread is '+threading.current_thread().getName()+', lock acquired!')
for i in range(0, 100000):
LockThread.count += 1
print('thread is '+threading.current_thread().getName()+', pre lock release!')
self.lock.release()
if __name__ == '__main__':
threads = list()
lock = threading.Lock()
for i in range(0, 10):
thread = LockThread(name=str(i), lock=lock)
thread.start()
threads.append(thread)
for thread in threads:
thread.join()
print('Main Thread finish, LockThread.count is:'+str(LockThread.count))對於一般的併發同步使用 Lock 就足夠了,簡單吧,關於其他的鎖機制(上面__all__ 的定義)自己可以參考其他資料進行學習,這裡點到為止,下面我們再來看看爬蟲中常用的執行緒優先順序佇列,如下:
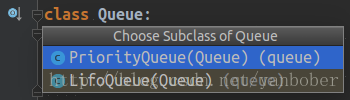
Python3 的 Queue 模組提供了同步、執行緒安全佇列類,包括先入先出佇列 Queue、後入先出佇列 LifoQueue 和優先順序佇列 PriorityQueue,這些佇列都實現了鎖機制,可以在多執行緒中直接使用,也可以用這些佇列來實現執行緒間的同步,下面給出一個簡單但是經典的示例(生產消費者問題),如下:
[本例項完整原始碼點我獲取 demo_threading_queue.py]
from queue import Queue
from random import randint
from threading import Thread
from time import sleep
'''
Python 3.X threading 與 Queue 結合演示 Demo
經典的併發生產消費者模型
'''
class TestQueue(object):
def __init__(self):
self.queue = Queue(2)
def writer(self):
print('Producter start write to queue.')
self.queue.put('key', block=1)
print('Producter write to queue end. size is:'+str(self.queue.qsize()))
def reader(self):
value = self.queue.get(block=1)
print('Consumer read from queue end. size is:'+str(self.queue.qsize()))
def producter(self):
for i in range(5):
self.writer()
sleep(randint(0, 3))
def consumer(self):
for i in range(5):
self.reader()
sleep(randint(2, 4))
def go(self):
print('TestQueue Start!')
threads = []
functions = [self.consumer, self.producter]
for func in functions:
thread = Thread(target=func, name=func.__name__)
thread.start()
threads.append(thread)
for thread in threads:
thread.join()
print('TestQueue Done!')
if __name__ == '__main__':
TestQueue().go()可以看到,一般與爬蟲相關常見和常用的 Python3 執行緒相關東西主要就上面這些,當然還有一些高階的用法和高階的執行緒類我們沒有提到,這些需要我們自己去積累和依據自己爬蟲需求選擇合適的執行緒輔助類;這裡我們篇幅有限不再展開,因為對於任何語言用好執行緒併發本來就是一個非常有深度的方向,涉及的問題也很多,但是對於一般業務來說上面的足矣。
2-3 Python 3.X 程式模組
上面我們介紹了 Python3 的 thread 併發相關基礎,我們都知道除過多執行緒還有多程式,其記憶體空間劃分等機制都是不一樣的,這是在別的語言我們都知道的。然而在 Python 中如果我們想充分使用多核 CPU 資源,那就得使用多程式,Python 給我們提供了非常好用的多程式模組包 multiprocessing,其支援子程式、通訊和共享資料等工具操作,非常棒。
下面先來看下 multiprocessing 的 Process 一般用法套路吧(其實完全類似 threading 用法,只不過含義和實質不同而已),如下:
[本例項完整原始碼點我獲取 demo_multiprocessing.py]
import multiprocessing
import time
from multiprocessing import Process
'''
Python 3.X multiprocess 模組演示 Demo
其實完全類似 threading 用法,只不過含義和實質不同而已
multiprocess 的 Process 類基本使用方式(繼承重寫 run 方法及直接傳遞方法)
'''
class NormalProcess(Process):
def __init__(self, name=None):
Process.__init__(self, name=name)
self.counter = 0
def run(self):
print(self.name + ' process is start!')
self.do_customer_things()
print(self.name + ' process is end!')
def do_customer_things(self):
while self.counter < 10:
time.sleep(1)
print('do customer things counter is:'+str(self.counter))
self.counter += 1
def loop_runner(max_counter=5):
print(multiprocessing.current_process().name + " process is start!")
cur_counter = 0
while cur_counter < max_counter:
time.sleep(1)
print('loop runner current counter is:' + str(cur_counter))
cur_counter += 1
print(multiprocessing.current_process().name + " process is end!")
if __name__ == '__main__':
print(multiprocessing.current_process().name + " process is start!")
print("cpu count:"+str(multiprocessing.cpu_count())+", active chiled count:"+str(len(multiprocessing.active_children())))
normal_process = NormalProcess("NORMAL PROCESS")
normal_process.start()
loop_process = Process(target=loop_runner, args=(10,), name='LOOP PROCESS')
loop_process.start()
print("cpu count:" + str(multiprocessing.cpu_count()) + ", active chiled count:" + str(len(multiprocessing.active_children())))
normal_process.join()
loop_process.join()
print(multiprocessing.current_process().name + " process is end!")怎麼樣,給出的兩種 Process 使用方式很像上面的 Thread,只是含義和原理及記憶體概念有了區別。有了這個基礎我們一樣可以來看看 Process 的併發鎖和多程式資料共享機制使用(與 Thread 的記憶體區別,任何語言通用),如下:
[本例項完整原始碼點我獲取 demo_multiprocessing_lock.py]
'''
Python 3.X multiprocess 模組演示 Demo
multiprocess 鎖同步機制及程式資料共享機制
當註釋掉 self.lock.acquire() 和 self.lock.release() 後執行程式碼會發現最後的 count 為 467195 等,併發問題。
當保留 self.lock.acquire() 和 self.lock.release() 後執行程式碼會發現最後的 count 為 1000000,鎖機制保證了併發。
'''
import multiprocessing
from multiprocessing import Process
class LockProcess(Process):
def __init__(self, name=None, lock=None, m_count=None):
Process.__init__(self, name=name)
self.lock = lock
self.m_count = m_count
def run(self):
self.lock.acquire()
print('process is '+multiprocessing.current_process().name+', lock acquired!')
#效能問題,100000次迴圈,所以這裡優化為先從多程式共享拿出來計算完再放回多程式共享
count = self.m_count.value;
for i in range(0, 100000):
count += 1
self.m_count.value = count
print('process is '+multiprocessing.current_process().name+', pre lock release!')
self.lock.release()
if __name__ == '__main__':
processes = list()
lock = multiprocessing.Lock()
m_count = multiprocessing.Manager().Value('count', 0)
for i in range(0, 10):
process = LockProcess(name=str(i), lock=lock, m_count=m_count)
process.start()
processes.append(process)
for process in processes:
process.join()
print('Main Process finish, LockProcess.count is:' + str(m_count.value))哎呀呀,矯情一把,受不了自己,都和 threading 類似是一個套路,唯一區別都是以為執行緒和程式本質區別導致的,而使用方式卻沒區別,所以 multiprocessing 的 Queue 類似 threading 的,不再舉例了,具體自己實戰吧。
2-4 Python 3.X 併發池
從 Python 併發執行緒到併發程式一步一步走到這你會發現 Python 標準庫給我們們提供的 _thread、threading 和 multiprocessing 模組是非常棒的,但是你有沒有想過(在其他語言也會遇到,譬如 C\Java 等)在實際專案中大規模的頻繁建立、銷燬執行緒或者程式是一件非常消耗資源的事情,所以池的概念就這麼誕生了(空間換時間)。好在 Python3.2 開始內建標準庫為我們提供了 concurrent.futures 模組,模組包含了 ThreadPoolExecutor 和 ProcessPoolExecutor 兩個類(其基類是 Executor 抽象類,不可直接使用),實現了對 threading 和 multiprocessing 的高階抽象,對編寫執行緒池、程式池提供了直接的支援,我們只用將相應的 tasks 放入執行緒池、程式池中讓其自動排程而不用自己去維護 Queue 來擔心死鎖問題。
先來看看執行緒池樣例:
[本例項完整原始碼點我獲取 demo_thread_pool_executor.py]
'''
Python 3.X ThreadPoolExecutor 模組演示 Demo
'''
import concurrent
from concurrent.futures import ThreadPoolExecutor
from urllib import request
class TestThreadPoolExecutor(object):
def __init__(self):
self.urls = [
'https://www.baidu.com/',
'http://blog.jobbole.com/',
'http://www.csdn.net/',
'https://juejin.im/',
'https://www.zhihu.com/'
]
def get_web_content(self, url=None):
print('start get web content from: '+url)
try:
headers = {"User-Agent": "Mozilla/5.0 (X11; Linux x86_64)"}
req = request.Request(url, headers=headers)
return request.urlopen(req).read().decode("utf-8")
except BaseException as e:
print(str(e))
return None
print('get web content end from: ' + str(url))
def runner(self):
thread_pool = ThreadPoolExecutor(max_workers=2, thread_name_prefix='DEMO')
futures = dict()
for url in self.urls:
future = thread_pool.submit(self.get_web_content, url)
futures[future] = url
for future in concurrent.futures.as_completed(futures):
url = futures[future]
try:
data = future.result()
except Exception as e:
print('Run thread url ('+url+') error. '+str(e))
else:
print(url+'Request data ok. size='+str(len(data)))
print('Finished!')
if __name__ == '__main__':
TestThreadPoolExecutor().runner()再來看看程式池例項,如下:
[本例項完整原始碼點我獲取 demo_process_pool_executor.py]
'''
Python 3.X ProcessPoolExecutor 模組演示 Demo
'''
import concurrent
from concurrent.futures import ProcessPoolExecutor
from urllib import request
class TestProcessPoolExecutor(object):
def __init__(self):
self.urls = [
'https://www.baidu.com/',
'http://blog.jobbole.com/',
'http://www.csdn.net/',
'https://juejin.im/',
'https://www.zhihu.com/'
]
def get_web_content(self, url=None):
print('start get web content from: '+url)
try:
headers = {"User-Agent": "Mozilla/5.0 (X11; Linux x86_64)"}
req = request.Request(url, headers=headers)
return request.urlopen(req).read().decode("utf-8")
except BaseException as e:
print(str(e))
return None
print('get web content end from: ' + str(url))
def runner(self):
process_pool = ProcessPoolExecutor(max_workers=4)
futures = dict()
for url in self.urls:
future = process_pool.submit(self.get_web_content, url)
futures[future] = url
for future in concurrent.futures.as_completed(futures):
url = futures[future]
try:
data = future.result()
except Exception as e:
print('Run process url ('+url+') error. '+str(e))
else:
print(url+'Request data ok. size='+str(len(data)))
print('Finished!')
if __name__ == '__main__':
TestProcessPoolExecutor().runner()唉,任何程式語言都是互通的,真的是這樣,你只要深入理解一門語言,其他的都很容易,要適應的只是語法;對於 Python 3 的併發其實還有很多知識點需要我們探索的,譬如非同步 IO、各種特性鎖等等,我們要依據自己的需求去選擇使用合適的併發處理,只有這樣才是最合適的,總之學習併發就一個套路—–實戰觀察思考。
【工匠若水 http://blog.csdn.net/yanbober 未經允許嚴禁轉載,請尊重作者勞動成果。私信聯絡我】
3 併發爬蟲實戰
屌爆了吧,上面我們 BB 了那麼多關於 Python 併發的東西(雖然很多沒 BB 到,畢竟不是專門介紹 Python 3 併發的)就是為了特麼的這個 Part 的實戰爬蟲例子,不然有啥意義呢,廢話不多說了,我們之前寫的爬蟲都是單個主執行緒的,他們有個很要命的問題就是一旦一個連結爬取卡住不動了,其他就真的只能乾瞪眼了,還有一個問題就是我的電腦這麼牛逼為毛我的爬蟲還是序列爬取那麼慢,所以下面兩個例項片段就是用來終結這兩個詬病的。
3-1 多執行緒爬蟲實戰
啥都別和老夫說,上來就是幹,上來就扔程式碼,別再告訴我用多執行緒演示了,直接上執行緒池,爬蟲不多解釋,具體看如下程式碼的註釋或者自己跑一下就明白了。
[本例項完整原始碼點我獲取 spider_multithread.py]
import os
from concurrent.futures import ThreadPoolExecutor
from urllib import request
import re
from urllib.parse import urljoin
from bs4 import BeautifulSoup
'''
使用單獨併發執行緒池爬取解析及單獨併發執行緒池儲存解析結果示例
爬取百度百科Android詞條簡介及該詞條連結詞條的簡介資訊,將結果輸出到當前目錄下output目錄
'''
class CrawlThreadPool(object):
'''
啟用最大併發執行緒數為5的執行緒池進行URL連結爬取及結果解析;
最終通過crawl方法的complete_callback引數進行爬取解析結果回撥
'''
def __init__(self):
self.thread_pool = ThreadPoolExecutor(max_workers=5)
def _request_parse_runnable(self, url):
print('start get web content from: ' + url)
try:
headers = {"User-Agent": "Mozilla/5.0 (X11; Linux x86_64)"}
req = request.Request(url, headers=headers)
content = request.urlopen(req).read().decode("utf-8")
soup = BeautifulSoup(content, "html.parser", from_encoding='utf-8')
new_urls = set()
links = soup.find_all("a", href=re.compile(r"/item/\w+"))
for link in links:
new_urls.add(urljoin(url, link["href"]))
data = {"url": url, "new_urls": new_urls}
data["title"] = soup.find("dd", class_="lemmaWgt-lemmaTitle-title").find("h1").get_text()
data["summary"] = soup.find("div", class_="lemma-summary").get_text()
except BaseException as e:
print(str(e))
data = None
return data
def crawl(self, url, complete_callback):
future = self.thread_pool.submit(self._request_parse_runnable, url)
future.add_done_callback(complete_callback)
class OutPutThreadPool(object):
'''
啟用最大併發執行緒數為5的執行緒池對上面爬取解析執行緒池結果進行併發處理儲存;
'''
def __init__(self):
self.thread_pool = ThreadPoolExecutor(max_workers=5)
def _output_runnable(self, crawl_result):
try:
url = crawl_result['url']
title = crawl_result['title']
summary = crawl_result['summary']
save_dir = 'output'
print('start save %s as %s.txt.' % (url, title))
if os.path.exists(save_dir) is False:
os.makedirs(save_dir)
save_file = save_dir + os.path.sep + title + '.txt'
if os.path.exists(save_file):
print('file %s is already exist!' % title)
return
with open(save_file, "w") as file_input:
file_input.write(summary)
except Exception as e:
print('save file error.'+str(e))
def save(self, crawl_result):
self.thread_pool.submit(self._output_runnable, crawl_result)
class CrawlManager(object):
'''
爬蟲管理類,負責管理爬取解析執行緒池及儲存執行緒池
'''
def __init__(self):
self.crawl_pool = CrawlThreadPool()
self.output_pool = OutPutThreadPool()
def _crawl_future_callback(self, crawl_url_future):
try:
data = crawl_url_future.result()
for new_url in data['new_urls']:
self.start_runner(new_url)
self.output_pool.save(data)
except Exception as e:
print('Run crawl url future thread error. '+str(e))
def start_runner(self, url):
self.crawl_pool.crawl(url, self._crawl_future_callback)
if __name__ == '__main__':
root_url = 'http://baike.baidu.com/item/Android'
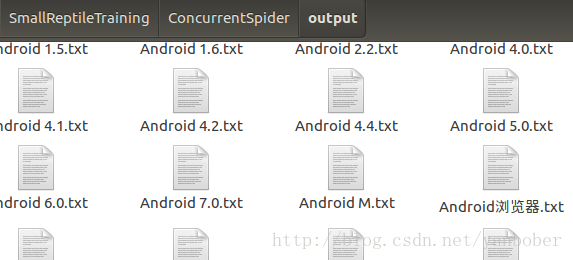
CrawlManager().start_runner(root_url)這效率比起該系列第一篇講的百科爬蟲簡直高的不能再高了,嗖嗖的,輸出結果部分截圖如下:
3-2 多程式爬蟲實戰
啥也不多說,看完多執行緒爬蟲的牛逼效率自然就該看多程式爬蟲的牛逼之處了,也一樣,別給我說啥概念,上面說的足夠多了,下面擼起袖子就是上程式碼,也別問是啥爬蟲,看註釋就行,如下:
[本例項完整原始碼點我獲取 spider_multiprocess.py]
import os
from concurrent.futures import ProcessPoolExecutor
from urllib import request
import re
from urllib.parse import urljoin
from bs4 import BeautifulSoup
'''
使用程式池爬取解析及儲存解析結果示例
爬取百度百科Android詞條簡介及該詞條連結詞條的簡介資訊,將結果輸出到當前目錄下output目錄
'''
class CrawlProcess(object):
'''
配合程式池進行URL連結爬取及結果解析;
最終通過crawl方法的complete_callback引數進行爬取解析結果回撥
'''
def _request_parse_runnable(self, url):
print('start get web content from: ' + url)
try:
headers = {"User-Agent": "Mozilla/5.0 (X11; Linux x86_64)"}
req = request.Request(url, headers=headers)
content = request.urlopen(req).read().decode("utf-8")
soup = BeautifulSoup(content, "html.parser", from_encoding='utf-8')
new_urls = set()
links = soup.find_all("a", href=re.compile(r"/item/\w+"))
for link in links:
new_urls.add(urljoin(url, link["href"]))
data = {"url": url, "new_urls": new_urls}
data["title"] = soup.find("dd", class_="lemmaWgt-lemmaTitle-title").find("h1").get_text()
data["summary"] = soup.find("div", class_="lemma-summary").get_text()
except BaseException as e:
print(str(e))
data = None
return data
def crawl(self, url, complete_callback, process_pool):
future = process_pool.submit(self._request_parse_runnable, url)
future.add_done_callback(complete_callback)
class OutPutProcess(object):
'''
配合程式池對上面爬取解析程式結果進行程式池處理儲存;
'''
def _output_runnable(self, crawl_result):
try:
url = crawl_result['url']
title = crawl_result['title']
summary = crawl_result['summary']
save_dir = 'output'
print('start save %s as %s.txt.' % (url, title))
if os.path.exists(save_dir) is False:
os.makedirs(save_dir)
save_file = save_dir + os.path.sep + title + '.txt'
if os.path.exists(save_file):
print('file %s is already exist!' % title)
return None
with open(save_file, "w") as file_input:
file_input.write(summary)
except Exception as e:
print('save file error.'+str(e))
return crawl_result
def save(self, crawl_result, process_pool):
process_pool.submit(self._output_runnable, crawl_result)
class CrawlManager(object):
'''
爬蟲管理類,程式池負責統一管理排程爬取解析及儲存程式
'''
def __init__(self):
self.crawl = CrawlProcess()
self.output = OutPutProcess()
self.crawl_pool = ProcessPoolExecutor(max_workers=8)
self.crawl_deep = 100 #爬取深度
self.crawl_cur_count = 0
def _crawl_future_callback(self, crawl_url_future):
try:
data = crawl_url_future.result()
self.output.save(data, self.crawl_pool)
for new_url in data['new_urls']:
self.start_runner(new_url)
except Exception as e:
print('Run crawl url future process error. '+str(e))
def start_runner(self, url):
if self.crawl_cur_count > self.crawl_deep:
return
self.crawl_cur_count += 1
self.crawl.crawl(url, self._crawl_future_callback, self.crawl_pool)
if __name__ == '__main__':
root_url = 'http://baike.baidu.com/item/Android'
CrawlManager().start_runner(root_url)唉,效果就不多說了,和上面執行緒池爬取效果類似,只是換為了程式池爬取而已。
【工匠若水 http://blog.csdn.net/yanbober 未經允許嚴禁轉載,請尊重作者勞動成果。私信聯絡我】
5 併發爬蟲總結
啥都不說,這一篇一下搞得有點不像在介紹併發爬蟲,而成了 Python3 併發程式設計基礎了,坑爹啊,無論怎樣最後我們還是給出了兩個基於 Python3 執行緒池、程式池的併發爬蟲小案例,麻雀雖小,五臟俱全。雖然本篇對併發爬蟲(Python3 併發)沒有進行深入介紹,但是基本目的達到了,關於併發深入學習不是一兩天的功夫,併發在大型專案中是個很有學問的東西,要走的路還有很長,不過有了這篇的鋪墊我們就可以自己去摸索分散式爬蟲的基本原理,其實就是多程式爬蟲,還有就是我們可以自己去摸索下 Python 的非同步 IO 機制,那才是核心,那也不是一兩篇就能說明白的東西。
^-^當然咯,看到這如果發現對您有幫助的話不妨掃描二維碼賞點買羽毛球的小錢(現在球也挺貴的),既是一種鼓勵也是一種分享,謝謝!

【工匠若水 http://blog.csdn.net/yanbober 未經允許嚴禁轉載,請尊重作者勞動成果。私信聯絡我】
相關文章
- Python3.X 爬蟲實戰(先爬起來嗨)Python爬蟲
- Go語言專案實戰:併發爬蟲Go爬蟲
- 爬蟲實戰——58同城租房資料爬取爬蟲
- 網路爬蟲——爬蟲實戰(一)爬蟲
- Python爬蟲實戰:爬取淘寶的商品資訊Python爬蟲
- 爬蟲實戰(一):爬取微博使用者資訊爬蟲
- 爬蟲實戰爬蟲
- Python爬蟲實戰詳解:爬取圖片之家Python爬蟲
- 爬蟲實戰scrapy爬蟲
- Python爬蟲實戰案例-爬取幣世界標紅快訊Python爬蟲
- python爬蟲實戰教程-Python爬蟲開發實戰教程(微課版)Python爬蟲
- python3網路爬蟲開發實戰_Python3 爬蟲實戰Python爬蟲
- Java 爬蟲專案實戰之爬蟲簡介Java爬蟲
- python爬蟲實戰,爬蟲之路,永無止境Python爬蟲
- 圖靈樣書爬蟲 - Python 爬蟲實戰圖靈爬蟲Python
- 《Python3網路爬蟲開發實戰》教程||爬蟲教程Python爬蟲
- Python爬蟲開發與專案實戰——基礎爬蟲分析Python爬蟲
- Python爬蟲開發與專案實戰 3: 初識爬蟲Python爬蟲
- python爬蟲實戰:爬取西刺代理的代理ip(二)Python爬蟲
- 爬蟲實戰(二):Selenium 模擬登入並爬取資訊爬蟲
- Python爬蟲實戰-使用Scrapy框架爬取土巴兔(一)Python爬蟲框架
- 爬蟲實戰開發學習(一)爬蟲
- Puppeteer爬蟲實戰(三)爬蟲
- 爬蟲技術實戰爬蟲
- Python 爬蟲實戰Python爬蟲
- 爬蟲利器 Puppeteer 實戰爬蟲
- Python 爬蟲實戰(2):股票資料定向爬蟲Python爬蟲
- [Python3網路爬蟲開發實戰] 分散式爬蟲原理Python爬蟲分散式
- 網路爬蟲——專案實戰(爬取糗事百科所有文章)爬蟲
- 爬蟲爬取微信小程式爬蟲微信小程式
- 爬蟲之股票定向爬取爬蟲
- 2個月精通Python爬蟲——3大爬蟲框架+6場實戰+反爬蟲技巧+分散式爬蟲Python爬蟲框架分散式
- python爬蟲---網頁爬蟲,圖片爬蟲,文章爬蟲,Python爬蟲爬取新聞網站新聞Python爬蟲網頁網站
- Python實現微博爬蟲,爬取新浪微博Python爬蟲
- 爬蟲——爬取貴陽房價(Python實現)爬蟲Python
- 爬蟲實戰:探索XPath爬蟲技巧之熱榜新聞爬蟲
- 爬蟲專案實戰(一)爬蟲
- 爬蟲實戰專案集合爬蟲