分散式全域性ID生成方案彙總和對比
1. 為什麼需要全域性ID
當業務量不大的時候,單庫單表使用資料庫自增ID就可以解決絕不多數問題,可是隨著業務的增長,勢必涉及到分庫分表,此時使用資料庫的主鍵ID就會出現問題,因此我們需要一個全域性唯一的ID。
2. 全域性ID的要求
- 全域性唯一
- 支援高併發
- 能夠體現一定屬性
- 高可靠,容錯單點故障
- 高效能
3. 生成方案
- UUID
- 資料庫自增ID
- 號段模式
- Redis
- twitter 雪花演算法(SnowFlake)
- 滴滴出品(TinyID)
- 百度 (Uidgenerator)
- 美團(Leaf)
1. 2. UUID
常見的方式。可以利用資料庫也可以利用程式生成,一般來說全球唯一。
優點:
- 簡單,程式碼方便。
- 生成ID效能非常好,基本不會有效能問題。
- 全球唯一,在遇見資料遷移,系統資料合併,或者資料庫變更等情況下,可以從容應對。
缺點:
- 沒有排序,無法保證趨勢遞增。
- UUID往往是使用字串儲存,查詢的效率比較低。
- 儲存空間比較大,如果是海量資料庫,就需要考慮儲存量的問題。
- 傳輸資料量大。
- 不可讀。
2. 資料庫自增ID
可以維護一個單獨的表用於生成分散式ID
CREATE TABLE SEQ.SEQUENCE (
id bigint(20) unsigned NOT NULL auto_increment
PRIMARY KEY (id),
) ENGINE=MyISAM;
複製程式碼優點:
- 簡單
- 數值型,趨勢遞增
缺點:
- 資料庫壓力大,效率低,DB可能存在當機風險
- 當機風險的解決辦法是使用叢集模式,設定不同庫表的起始值和步長,但是這種模式擴容困難
set @@auto_increment_offset = 1; -- 起始值
set @@auto_increment_increment = 2; -- 步長
...
複製程式碼
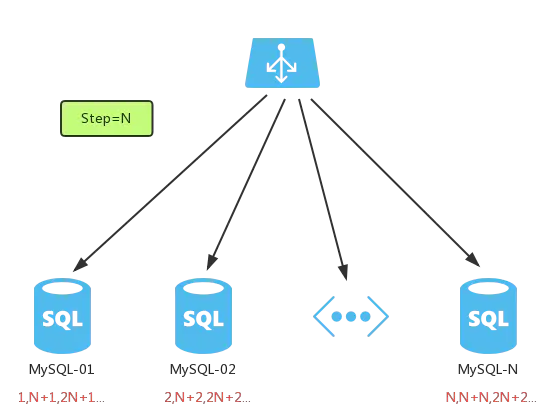
3. 基於資料庫的號段模式
號段模式是當下分散式ID生成器的主流實現方式之一,號段模式可以理解為從資料庫批量的獲取自增ID,每次從資料庫取出一個號段範圍,例如 (1,1000] 代表1000個ID,具體的業務服務將本號段,生成1~1000的自增ID並載入到記憶體。表結構如下:
CREATE TABLE id_generator (
id int(10) NOT NULL,
max_id bigint(20) NOT NULL COMMENT '當前最大id',
step int(20) NOT NULL COMMENT '號段的步長',
biz_type int(20) NOT NULL COMMENT '業務型別',
version int(20) NOT NULL COMMENT '版本號,樂觀鎖,,每次都更新version,保證併發時資料的正確性',
PRIMARY KEY (`id`)
)
複製程式碼等這批號段ID用完,再次向資料庫申請新號段,對max_id欄位做一次update操作,update max_id= max_id + step,update成功則說明新號段獲取成功,新的號段範圍是(max_id ,max_id +step]
update id_generator set max_id = #{max_id+step}, version = version + 1 where version = # {version} and biz_type = XXX
複製程式碼4. 基於redis
Redis實現了一個原子操作INCR和INCRBY實現遞增的操作。當使用資料庫效能不夠時,可以採用Redis來代替,同時使用Redis叢集來提高吞吐量。可以初始化每臺Redis的初始值為1,2,3,4,5,然後步長為5。各個Redis生成的ID為
A:1,6,11,16,21
B:2,7,12,17,22
C:3,8,13,18,23
D:4,9,14,19,24
E:5,10,15,20,25
複製程式碼優點
- 不依賴於資料庫,靈活方便,且效能優於資料庫。
- 數字ID天然排序,對分頁或者需要排序的結果很有幫助。
缺點:
- 如果系統中沒有Redis,還需要引入新的元件,增加系統複雜度。
- 需要編碼和配置的工作量比較大。這個都不是最大的問題。
- redis資料持久化問題
5. snowflake方案
snowflake是Twitter開源的分散式ID生成演算法,結果是一個long型的ID。
這種方案大致來說是一種以劃分名稱空間(UUID也算,由於比較常見,所以單獨分析)來生成ID的一種演算法,這種方案把64-bit分別劃分成多段,分開來標示機器、時間等。
其核心思想是:使用41bit作為毫秒數,10bit作為機器的ID(5個bit是資料中心,5個bit的機器ID),12bit作為毫秒內的流水號,最後還有一個符號位,永遠是0。
比如在snowflake中的64-bit分別表示如下圖(圖片來自網路)所示:
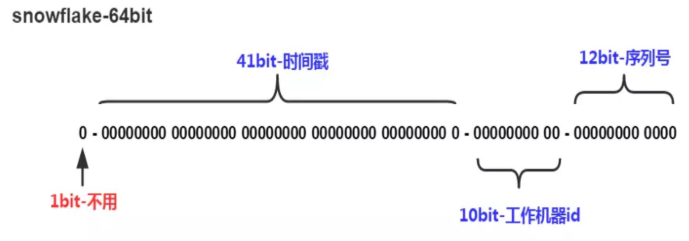
整個結構是64位,所以我們在Java中可以使用long來進行儲存。 該演算法實現基本就是二進位制操作,單機每秒內理論上最多可以生成1024*(2^12),也就是409.6萬個ID(1024 X 4096 = 4194304)
優點:
整體上按照時間自增排序,並且整個分散式系統內不會產生ID碰撞(由資料中心ID和機器ID作區分),並且效率較高,經測試,SnowFlake每秒能夠產生26萬ID左右。
- 毫秒數在高位,自增序列在低位,整個ID都是趨勢遞增的。
- 不依賴資料庫等第三方系統,以服務的方式部署,穩定性更高,生成ID的效能也是非常高的。
- 可以根據自身業務特性分配bit位,非常靈活。
缺點:
- 強依賴機器時鐘,如果機器上時鐘回撥,會導致發號重複或者服務會處於不可用狀態。
- 針對此,美團做出了改進:github.com/Meituan-Dia…
package com.example.demo.service;
/**
* @Author: dawang
* @Desc:
* @Date: 20:51 2020/2/16
*/
public class SnowFlake {
// ==============================Fields==================
/**
* 開始時間截 (2019-08-06)
*/
private final long START_TIMESTAMP = 1565020800000L;
/**
* 機器id所佔的位數
*/
private final long workerIdBits = 5L;
/**
* 資料標識id所佔的位數
*/
private final long datacenterIdBits = 5L;
/**
* 支援的最大機器id,結果是31 (這個移位演算法可以很快的計算出幾位二進位制數所能表示的最大十進位制數)
*/
private final long maxWorkerId = -1L ^ (-1L << workerIdBits);
/**
* 支援的最大資料標識id,結果是31
*/
private final long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);
/**
* 序列在id中佔的位數
*/
private final long sequenceBits = 12L;
/**
* 機器ID向左移12位
*/
private final long workerIdShift = sequenceBits;
/**
* 資料標識id向左移17位(12+5)
*/
private final long datacenterIdShift = sequenceBits + workerIdBits;
/**
* 時間截向左移22位(5+5+12)
*/
private final long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;
/**
* 生成序列的掩碼,這裡為4095 (0b111111111111=0xfff=4095)
*/
private final long sequenceMask = -1L ^ (-1L << sequenceBits);
/**
* 工作機器ID(0~31)
*/
private long workerId;
/**
* 資料中心ID(0~31)
*/
private long datacenterId;
/**
* 毫秒內序列(0~4095)
*/
private long sequence = 0L;
/**
* 上次生成ID的時間截
*/
private long lastTimestamp = -1L;
//==============================Constructors====================
/**
* 建構函式
*
* @param workerId 工作ID (0~31)
* @param datacenterId 資料中心ID (0~31)
*/
SnowFlake(long workerId, long datacenterId) {
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0", maxWorkerId));
}
if (datacenterId > maxDatacenterId || datacenterId < 0) {
throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0", maxDatacenterId));
}
this.workerId = workerId;
this.datacenterId = datacenterId;
}
// ==============================Methods=================================
/**
* 獲得下一個ID (該方法是執行緒安全的)
*
* @return SnowflakeId
*/
public synchronized long nextId() {
long timestamp = timeGen();
//如果當前時間小於上一次ID生成的時間戳,說明系統時鐘回退過這個時候應當丟擲異常
if (timestamp < lastTimestamp) {
throw new RuntimeException(
String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));
}
//如果是同一時間生成的,則進行毫秒內序列
if (lastTimestamp == timestamp) {
sequence = (sequence + 1) & sequenceMask;
//毫秒內序列溢位
if (sequence == 0) {
//阻塞到下一個毫秒,獲得新的時間戳
timestamp = tilNextMillis(lastTimestamp);
}
}
//時間戳改變,毫秒內序列重置
else {
sequence = 0L;
}
//上次生成ID的時間截
lastTimestamp = timestamp;
//移位並通過或運算拼到一起組成64位的ID
return ((timestamp - START_TIMESTAMP) << timestampLeftShift) //
| (datacenterId << datacenterIdShift) //
| (workerId << workerIdShift) //
| sequence;
}
/**
* 阻塞到下一個毫秒,直到獲得新的時間戳
*
* @param lastTimestamp 上次生成ID的時間截
* @return 當前時間戳
*/
protected long tilNextMillis(long lastTimestamp) {
long timestamp = timeGen();
while (timestamp <= lastTimestamp) {
timestamp = timeGen();
}
return timestamp;
}
/**
* 返回以毫秒為單位的當前時間
*
* @return 當前時間(毫秒)
*/
protected long timeGen() {
return System.currentTimeMillis();
}
//==============================Test=============================================
/**
* 測試
*/
public static void main(String[] args) {
SnowFlake idWorker = new SnowFlake(0, 0);
for (int i = 0; i < 1000; i++) {
long id = idWorker.nextId();
System.out.println(Long.toBinaryString(id));
System.out.println(id);
}
}
}
複製程式碼6. 百度(uid-generator)
uid-generator是基於Snowflake演算法, 專案地址:github.com/baidu/uid-g…
粉絲福利
福利一:
長按掃碼關注下方二維碼,回覆「後端愛碼士」四個字,即可領取後端技術資料包(由號主(阿里p7)和另外四位BAT等網際網路大廠技術專家級朋友傾力總結,包括java併發,mysql,redis,kafka,zookeeper原理以及面試套路等)

福利二:
長按掃描下方二維碼,加號主微信,然後將本文轉發朋友圈,攢夠30個贊,截圖反饋給號主,就能獲得如下福利:
-
獲邀進入號主建立的網際網路大廠面試討論群。
-
以6折優惠價(原價1499元/個)獲得筆者一對一收徒第三期的名額(前提是需要有一定的基礎,需要通過考核),先到先得,每期5個名額,前兩期10名學徒全部收穫大廠offer,平均月薪28k以上。
-
阿里,騰訊,美團,滴滴,位元組,百度等大廠內推機會。

相關文章
- 分散式全域性ID生成方案分散式
- 分散式全域性唯一ID分散式
- 框架篇:分散式全域性唯一ID框架分散式
- 分散式ID生成器的解決方案總結分散式
- 聽說:分散式ID不能全域性遞增?分散式
- 搞懂分散式技術12:分散式ID生成方案分散式
- 【高併發】之分散式全域性唯一 ID分散式
- 5 大分散式 ID 生成器優缺點簡單對比分散式
- 分散式唯一ID的幾種生成方案分散式
- 分散式事務解決方案彙總分散式
- 分散式ID設計方案分散式
- 分散式唯一id生成策略分散式
- 分散式事務的理解和常見解決方案彙總分散式
- 生成分散式唯一ID的幾種解決方案分散式
- redis實現分散式id方案Redis分散式
- Leaf-分散式ID生成系統分散式
- 分散式唯一 ID 生成器分散式
- 分散式 ID 生成演算法 — SnowFlake分散式演算法
- 探討分散式ID生成系統分散式
- 探索 PHP 如何生成全域性唯一的 idPHP
- 分散式系統全域性唯一Id(SnowFlake)雪花演算法實現分散式演算法
- 面試基礎之:叢集高併發情況下如何保證分散式唯一全域性Id生成面試分散式
- 冰河開源了全網首個完全開源的分散式全域性有序序列號(分散式ID)框架!!分散式框架
- 分散式唯一 ID 生成器 - IDGen分散式
- 怎樣生成分散式的流水ID分散式
- 如何在Java服務中實現分散式ID生成:雪花演算法與UUID的對比Java分散式演算法UI
- Spring Boot 工程整合全域性唯一ID生成器 VestaSpring Boot
- 圖解Janusgraph系列-分散式id生成策略分析圖解分散式
- 分散式id分散式
- PHP 實現 Snowflake 生成分散式唯一 IDPHP分散式
- Leaf:美團分散式ID生成服務開源分散式
- 分散式 ID 解決方案之美團 Leaf分散式
- 分散式ID系列(2)——UUID適合做分散式ID嗎分散式UI
- 分庫分表的 9種分散式主鍵ID 生成方案,挺全乎的分散式
- 分散式唯一ID生成方案選型!詳細解析雪花演算法Snowflake分散式演算法
- Java使用雪花演算法實現生成全域性唯一idJava演算法
- 分散式系統唯一主鍵識別符號ID生成機制比較 - Encore分散式符號
- ShardingSphere-proxy-5.0.0分散式雪花ID生成(三)分散式