什麼是字符集
在介紹字符集之前,我們先了解下為什麼要有字符集。我們在計算機螢幕上看到的是實體化的文字,而在計算機儲存介質中存放的實際是二進位制的位元流。那麼在這兩者之間的轉換規則就需要一個統一的標準,否則把我們的U盤插到老闆的電腦上,文件就亂碼了;小夥伴QQ上傳過來的檔案,在我們本地開啟又亂碼了。於是為了實現轉換標準,各種字符集標準就出現了。簡單的說字符集就規定了某個文字對應的二進位制數字存放方式(編碼)和某串二進位制數值代表了哪個文字(解碼)的轉換關係。
那麼為什麼會有那麼多字符集標準呢?這個問題實際非常容易回答。問問自己為什麼我們的插頭拿到英國就不能用了呢?為什麼顯示器同時有DVI,VGA,HDMI,DP這麼多介面呢?很多規範和標準在最初制定時並不會意識到這將會是以後全球普適的準則,或者處於組織本身利益就想從本質上區別於現有標準。於是,就產生了那麼多具有相同效果但又不相互相容的標準了。
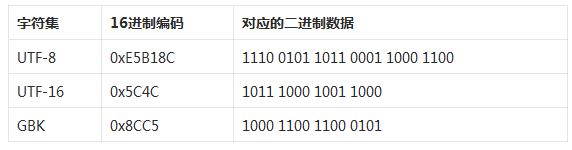
說了那麼多我們來看一個實際例子,下面就是屌這個字在各種編碼下的十六進位制和二進位制編碼結果,怎麼樣有沒有一種很屌的感覺?
什麼是字元編碼
字符集只是一個規則集合的名字,對應到真實生活中,字符集就是對某種語言的稱呼。例如:英語,漢語,日語。對於一個字符集來說要正確編碼轉碼一個字元需要三個關鍵元素:字型檔表(character repertoire)、編碼字符集(coded character set)、字元編碼(character encoding form)。其中字型檔表是一個相當於所有可讀或者可顯示字元的資料庫,字型檔表決定了整個字符集能夠展現表示的所有字元的範圍。編碼字符集,即用一個編碼值code point來表示一個字元在字型檔中的位置。字元編碼,將編碼字符集和實際儲存數值之間的轉換關係。一般來說都會直接將code point的值作為編碼後的值直接儲存。例如在ASCII中A在表中排第65位,而編碼後A的數值是0100 0001也即十進位制的65的二進位制轉換結果。
看到這裡,可能很多讀者都會有和我當初一樣的疑問:字型檔表和編碼字符集看來是必不可少的,那既然字型檔表中的每一個字元都有一個自己的序號,直接把序號作為儲存內容就好了。為什麼還要多此一舉通過字元編碼把序號轉換成另外一種儲存格式呢?其實原因也比較容易理解:統一字型檔表的目的是為了能夠涵蓋世界上所有的字元,但實際使用過程中會發現真正用的上的字元相對整個字型檔表來說比例非常低。例如中文地區的程式幾乎不會需要日語字元,而一些英語國家甚至簡單的ASCII字型檔表就能滿足基本需求。而如果把每個字元都用字型檔表中的序號來儲存的話,每個字元就需要3個位元組(這裡以Unicode字型檔為例),這樣對於原本用僅佔一個字元的ASCII編碼的英語地區國家顯然是一個額外成本(儲存體積是原來的三倍)。算的直接一些,同樣一塊硬碟,用ASCII可以存1500篇文章,而用3位元組Unicode序號儲存只能存500篇。於是就出現了UTF-8這樣的變長編碼。在UTF-8編碼中原本只需要一個位元組的ASCII字元,仍然只佔一個位元組。而像中文及日語這樣的複雜字元就需要2個到3個位元組來儲存。
UTF-8和Unicode的關係
看完上面兩個概念解釋,那麼解釋UTF-8和Unicode的關係就比較簡單了。Unicode就是上文中提到的編碼字符集,而UTF-8就是字元編碼,即Unicode規則字型檔的一種實現形式。隨著網際網路的發展,對同一字型檔集的要求越來越迫切,Unicode標準也就自然而然的出現。它幾乎涵蓋了各個國家語言可能出現的符號和文字,並將為他們編號。詳見:Unicode on Wikipedia。Unicode的編號從0000開始一直到10FFFF共分為16個Plane,每個Plane中有65536個字元。而UTF-8則只實現了第一個Plane,可見UTF-8雖然是一個當今接受度最廣的字符集編碼,但是它並沒有涵蓋整個Unicode的字型檔,這也造成了它在某些場景下對於特殊字元的處理困難(下文會有提到)。
UTF-8編碼簡介
為了更好的理解後面的實際應用,我們這裡簡單的介紹下UTF-8的編碼實現方法。即UTF-8的物理儲存和Unicode序號的轉換關係。
UTF-8編碼為變長編碼。最小編碼單位(code unit)為一個位元組。一個位元組的前1-3個bit為描述性部分,後面為實際序號部分。
- 如果一個位元組的第一位為0,那麼代表當前字元為單位元組字元,佔用一個位元組的空間。0之後的所有部分(7個bit)代表在Unicode中的序號。
- 如果一個位元組以110開頭,那麼代表當前字元為雙位元組字元,佔用2個位元組的空間。110之後的所有部分(7個bit)代表在Unicode中的序號。且第二個位元組以10開頭
- 如果一個位元組以1110開頭,那麼代表當前字元為三位元組字元,佔用2個位元組的空間。110之後的所有部分(7個bit)代表在Unicode中的序號。且第二、第三個位元組以10開頭
- 如果一個位元組以10開頭,那麼代表當前位元組為多位元組字元的第二個位元組。10之後的所有部分(6個bit)代表在Unicode中的序號。
具體每個位元組的特徵可見下表,其中x代表序號部分,把各個位元組中的所有x部分拼接在一起就組成了在Unicode字型檔中的序號

我們分別看三個從一個位元組到三個位元組的UTF-8編碼例子:
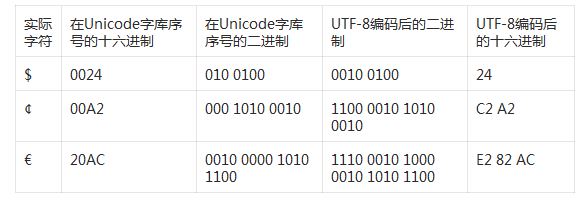
細心的讀者不難從以上的簡單介紹中得出以下規律:
- 3個位元組的UTF-8十六進位制編碼一定是以E開頭的
- 2個位元組的UTF-8十六進位制編碼一定是以C或D開頭的
- 1個位元組的UTF-8十六進位制編碼一定是以比8小的數字開頭的
為什麼會出現亂碼
先科普下亂碼的英文native說法是mojibake
簡單的說亂碼的出現是因為:編碼和解碼時用了不同或者不相容的字符集。對應到真實生活中,就好比是一個英國人為了表示祝福在紙上寫了bless(編碼過程)。而一個法國人拿到了這張紙,由於在法語中bless表示受傷的意思,所以認為他想表達的是受傷(解碼過程)。這個就是一個現實生活中的亂碼情況。在電腦科學中一樣,一個用UTF-8編碼後的字元,用GBK去解碼。由於兩個字符集的字型檔表不一樣,同一個漢字在兩個字元表的位置也不同,最終就會出現亂碼。
我們來看一個例子:假設我們用UTF-8編碼儲存很屌兩個字,會有如下轉換:

於是我們得到了E5BE88E5B18C這麼一串數值。而顯示時我們用GBK解碼進行展示,通過查表我們獲得以下資訊:
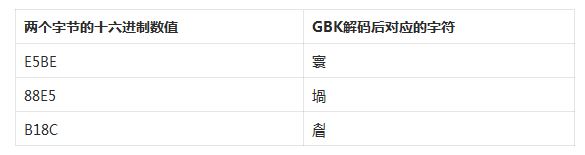
解碼後我們就得到了寰堝睂這麼一個錯誤的結果,更要命的是連字元個數都變了。
如何識別亂碼的本來想要表達的文字
要從亂碼字元中反解出原來的正確文字需要對各個字符集編碼規則有較為深刻的掌握。但是原理很簡單,這裡用最常見的UTF-8被錯誤用GBK展示時的亂碼為例,來說明具體反解和識別過程。
第1步 編碼
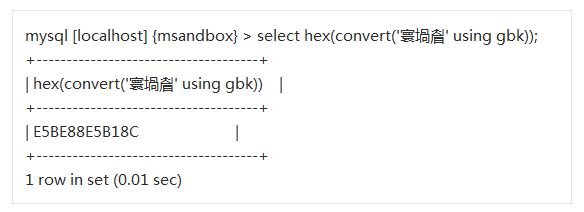
假設我們在頁面上看到寰堝睂這樣的亂碼,而又得知我們的瀏覽器當前使用GBK編碼。那麼第一步我們就能先通過GBK把亂碼編碼成二進位制表示式。當然查表編碼效率很低,我們也可以用以下SQL語句直接通過MySQL客戶端來做編碼工作:
第2步 識別
現在我們得到了解碼後的二進位制字串E5BE88E5B18C。然後我們將它按位元組拆開。

然後套用之前UTF-8編碼介紹章節中總結出的規律,就不難發現這6個位元組的資料符合UTF-8編碼規則。如果整個資料流都符合這個規則的話,我們就能大膽假設亂碼之前的編碼字符集是UTF-8
第3步 解碼
然後我們就能拿著E5BE88E5B18C用UTF-8解碼,檢視亂碼前的文字了。當然我們可以不查表直接通過SQL獲得結果:
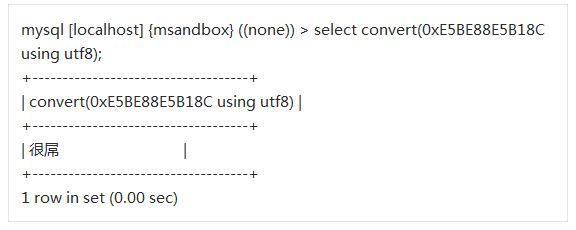
常見問題處理之Emoji
所謂Emoji就是一種在Unicode位於\u1F601-\u1F64F區段的字元。這個顯然超過了目前常用的UTF-8字符集的編碼範圍\u0000-\uFFFF。Emoji表情隨著IOS的普及和微信的支援越來越常見。下面就是幾個常見的Emoji:

那麼Emoji字元表情會對我們平時的開發運維帶來什麼影響呢?最常見的問題就在於將他存入MySQL資料庫的時候。一般來說MySQL資料庫的預設字符集都會配置成UTF-8(三位元組),而utf8mb4在5.5以後才被支援,也很少會有DBA主動將系統預設字符集改成utf8mb4。那麼問題就來了,當我們把一個需要4位元組UTF-8編碼才能表示的字元存入資料庫的時候就會報錯:
ERROR 1366: Incorrect string value: '\xF0\x9D\x8C\x86' for column 。 如果認真閱讀了上面的解釋,那麼這個報錯也就不難看懂了。我們試圖將一串Bytes插入到一列中,而這串Bytes的第一個位元組是\xF0意味著這是一個四位元組的UTF-8編碼。但是當MySQL表和列字符集配置為UTF-8的時候是無法儲存這樣的字元的,所以報了錯。
那麼遇到這種情況我們如何解決呢?有兩種方式:升級MySQL到5.6或更高版本,並且將表字符集切換至utf8mb4。第二種方法就是在把內容存入到資料庫之前做一次過濾,將Emoji字元替換成一段特殊的文字編碼,然後再存入資料庫中。之後從資料庫獲取或者前端展示時再將這段特殊文字編碼轉換成Emoji顯示。第二種方法我們假設用-*-1F601-*-來替代4位元組的Emoji,那麼具體實現python程式碼可以參見Stackoverflow上的回答
相關閱讀
評論(1)