機器之心釋出
來源:騰訊優圖實驗室
被譽為計算機視覺領域三大頂級會議之一的 ICCV(另外兩個為 CVPR、ECCV)不久之前揭曉了收錄論文名單,騰訊優圖共有 12 篇論文入選,居業界實驗室前列,其中 3 篇被選做口頭報告(Oral),該類論文僅佔總投稿數的 2.1%(45/2143)。
本屆 ICCV 共收到 2143 篇論文投稿,其中 621 篇被選為大會論文,錄用比例 29%。其中有 45 篇口頭報告(Oral)和 56 篇亮點報告(Spotlight)。今年參會人數預計將超過 3000 人。

ICCV 作為計算機視覺領域最高階別的會議之一,其論文集代表了計算機視覺領域最新的發展方向和水平。此次騰訊優圖入選的論文提出了諸多亮點:全球首個 AI 卸妝效果的演算法;現今最準確的單張影象深度估計演算法;完美解決多幀資訊融合困難的多幀超解析度視訊結果;史無前例的手機雙攝影象匹配和分割研究成果。這些論文呈現了有趣且可擴充套件應用的技術,讓視覺 AI 成為了一個工業界和學術界的交叉熱點。其中,騰訊優圖的智慧卸妝超解析度、雙攝融合、濾鏡還原和智慧影象縮放都是具有極大應用前景的技術。它們創造出新應用的同時也改進了現有演算法,為後續的研究提供了更多的經驗和指導。
下文對騰訊優圖 12 篇入選論文進行解析:
1. Oral 論文:美化人像的盲復原
Makeup-Go: Blind Reversion of Portrait Edit
http://open.youtu.qq.com/research/publications

本文與香港中文大學合作完成。目前市面上有很多關於人臉美化的應用,如騰訊天天 P 圖等。由於這些應用的流行,網路上的人像很多與真人不符。本文提出一種影象盲復原的演算法,用於將美化過的人像復原為真實的人像。為了簡化問題,本文著重闡述如何解決全域性美化操作的復原問題,例如膚色美白,去皺,磨皮等。由於這些操作是在影象的不同尺度上完成的,而我們又無法得到人臉美化應用中所使用的操作型別和引數,直接使用現有的模型並無法解決這個問題。我們提出了一種新的深度網路結構,成分迴歸網路,來對美化影象進行盲復原。即使在不知道美化系統具體引數的情況下,該網路結構亦能更好地將美化後的影象對映為原始影象。實驗表明,該網路在不同尺度上均可以得到較高的還原度。
本文入選 ICCV 2017 口頭報告(Oral),該類論文僅佔總投稿數的 2.1%。
2. Oral 論文:細節還原深度視訊超解析度
Detail-revealing Deep Video Super-resolution
http://open.youtu.qq.com/research/publications
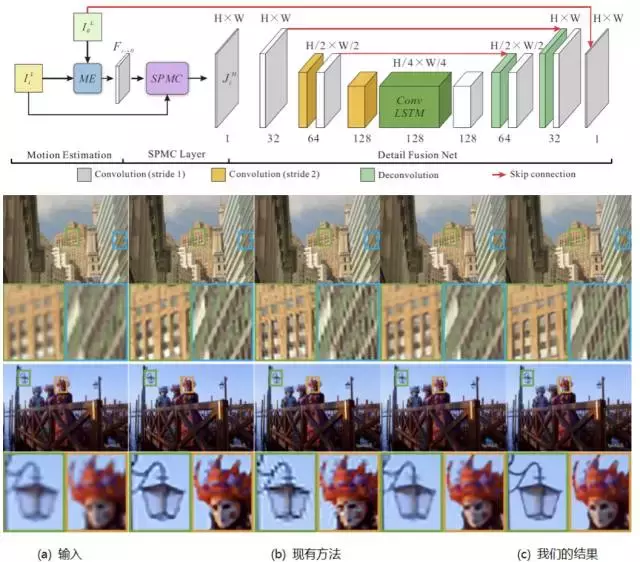
本論文與香港中文大學、多倫多大學和 Adobe 合作完成。本論文關注解決視訊超解析度的問題,即利用視訊中低解析度的多幀資訊,恢復出清晰而真實的高解析度影象。傳統的超解析度演算法處理速度慢,恢復效果嚴重依賴於繁瑣的引數調整,因此難以實用。近期的基於深度學習的演算法則由於運動估計不夠準確,難以恢復足夠豐富的真實細節。
本文作者從原理和實驗上發現並指出:正確的運動估計對於影象細節恢復至關重要,並基於此設計了亞畫素運動補償網路層 SPMC Layer。本文提出的適用於視訊超解析度的網路結構能夠實現:單模型處理任意尺寸輸入,任意倍率放大,任意多幀處理。同時,本文演算法能夠在取得豐富的真實細節情況下,達到很快的處理速度(百倍於同等效果的傳統方法)。本文演算法在效果、速度和實用性上均能超過現有其他演算法。
本文入選 ICCV 2017 口頭報告(Oral),該類論文僅佔總投稿數的 2.1%。
3. Oral 論文:基於圖的 RGBD 影象分割網路
3D Graph Neural Networks for RGBD Semantic Segmentation
http://open.youtu.qq.com/research/publications
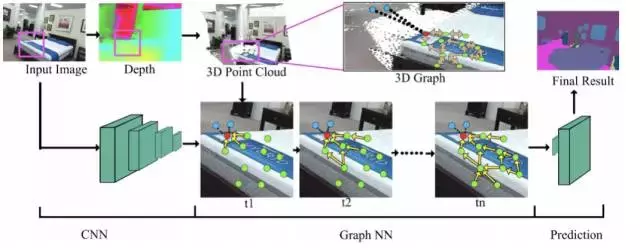
本論文與香港中文大學、多倫多大學合作完成。本論文專注解決 RGBD 影象的語義分割問題。與比較常見的 RGB 影象分割問題相比,這個問題又有了深度的資訊。深度資訊能夠表徵物體的幾何形狀,並且能夠更精確的描述畫素件的幾何連結。因此如何利用深度資訊做到更精確的影象分割成為這個問題最核心的模組。在此之前的方法都是先將深度圖編碼成 HHA 影象,然後再把 HHA 圖當作另外一張影象並輸入到神經網路裡抽取特徵。這種方法在本質上還是一個基於 2D 的解決思路,無法更好的融合點之間在真實空間的聯絡,並不能使得到的結果很好的利用深度資訊。本文作者提出在把深度資訊轉化為點真實的三維座標,然後建立基於點實際座標的 knn 圖。並且利用基於圖的神經網路,能夠讓影象特徵可以根據 knn 圖相互迭代更新每個點的特徵。最後再利用分類網路對更新過的特徵進行分類完成影象 RGBD 影象分割的問題。本文演算法在效果上超過現在的基於 2d 卷積的方法,體現了該方法利用幾何資訊完成特徵迭代更新的有效性。
本文入選 ICCV 2017 口頭報告(Oral),該類論文僅佔總投稿數的 2.1%。
4. Poster 論文:高質量的手機雙攝影象匹配和分割估計
High-Quality Correspondence and Segmentation Estimation for Dual-Lens Smart-Phone Portraits
http://open.youtu.qq.com/research/publications
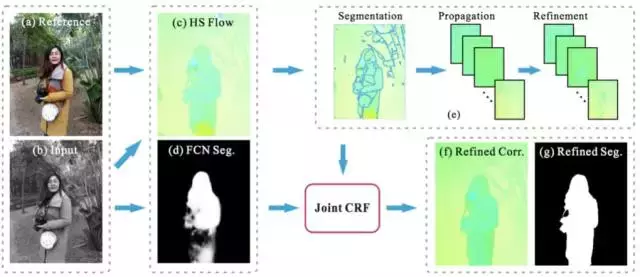
本文提出了一個高質量的手機雙攝影象匹配以及分割的演算法。同時解決了影象匹配和物體分割這兩大計算機視覺裡的難題。隨著雙攝逐漸成為手機的標配,怎樣更好的匹配雙攝影象一直以來都是學術界和工業界關心的問題。為了解決這一難題,作者提出了一種聯合優化匹配和分割的框架,為了讓優化高效,還提出了一種區域的匹配演算法。作者建立了一個 2000 對雙攝影象的資料集用於演算法的評估和測試。
5. Poster 論文:立體匹配的無監督機器學習
Unsupervised Learning of Stereo Matching
http://open.youtu.qq.com/research/publications
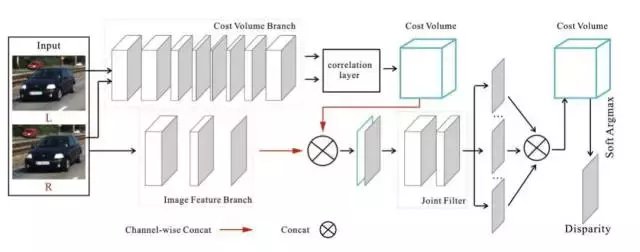
本論文與香港中文大學合作完成,主要提出了全新的立體匹配(Stereo Matching)的無監督學習(Unsupervised Learning)框架。深度神經網路在立體匹配問題中被廣泛應用,與傳統方法相比較下,精度和效率都有顯著的提高。然而現有的方法大多基於有監督學習(Supervised Learning),另外少有的一些通過無監督學習得到的模型的精度也不甚理想。
在這篇論文中,作者提出了一種簡單又高效的對立體匹配問題的無監督學習方法。通過左右一致性檢測,此方法在每一次迭代中都會篩選出正確的匹配。這些正確的匹配會被用作下一次迭代的訓練資料。經過數次迭代,此方法收斂到穩定狀態。實驗結果證明了此方法的精度遠優於現有的無監督方法,且十分接近有監督方法。
6. Poster 論文:基於零階優化的影象濾鏡還原
Zero-order Reverse Filtering
http://open.youtu.qq.com/research/publications
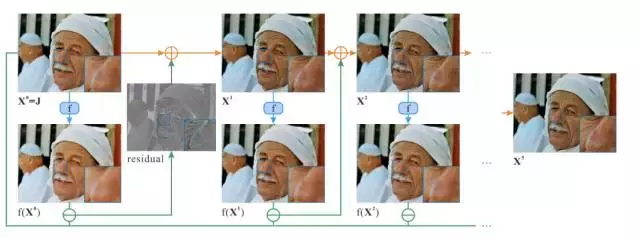
本論文與香港中文大學、多倫多大學和 Adobe 合作完成。在影象處理領域,研究者們設計了種類的繁多的濾鏡用來消除噪聲,去除紋理等。本文另闢蹊徑,首次提出並探討了濾鏡問題的一個新方向:能否恢復經過影象濾鏡處理之後的圖片?
通過對影象濾鏡過程的分析,本文作者發現傳統平滑濾鏡可以近似看做測度理論中的壓縮對映。因此,在無需知道濾鏡實現演算法的情況下,用簡單地零階迭代演算法便可以恢復濾鏡前的效果。作者在常用的數十種濾鏡上測試了演算法,並均能取得很好的效果。本演算法本身實現簡單(無需知道濾鏡演算法,無需計算梯度),效果顯著,其揭示的現象和背後的原理有望引起後續研究者們對濾鏡演算法領域新的理解。
7. Poster 論文:基於圖模型神經網路的情景識別
Situation Recognition with Graph Neural Networks
http://open.youtu.qq.com/research/publications
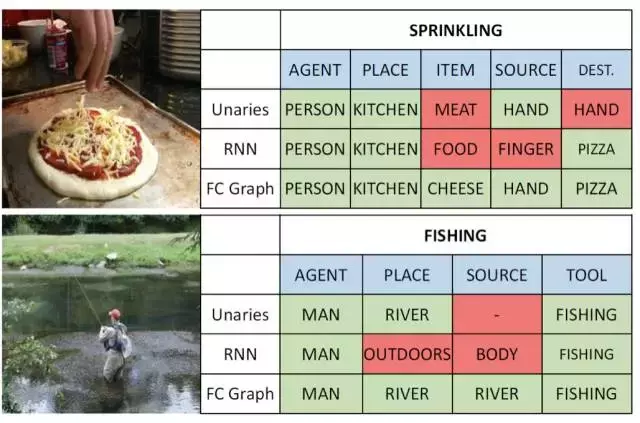
本論文與香港中文大學和多倫多大學合作完成,作者提出了一種基於圖模型的神經網路用於情景識別任務。在情景識別任務中,演算法需要同時識別圖中所展示的動作以及參與完成這個動作的各種角色,比如主語、賓語、目標、工具等等。為了顯式地對不同角色間的關係建模,文中提出的圖模型神經網路將表示不同角色的節點連線在了一起,並通過資訊傳遞的方式使得網路可以輸出一個結構化的結果。作者在實驗中比較了不同的連線方式,比如線形結構,樹形結構和全連線結構,發現在情景識別任務中全連線結構的效果最好。最後,文中還展示網路所學習到的對於不同動作的特有的連線結構。上圖所示的結果圖,比較了不同模型的檢測結果。其中藍底的表示參與動作的角色,綠底表示正確的預測結果,紅底表示錯誤的預測結果。我們可以看到,使用全連線圖模型能夠糾正一些由其他模型產生的錯誤。
8.Poster 論文:基於序列性組合深度網路的例項分割
Sequential Grouping Networks (SGN) for Instance Segmentation
http://open.youtu.qq.com/research/publications

本論文與香港中文大學,多倫多大學和 Uber 合作完成。例項分割是比物體檢測和語義分割更進一步的識別任務,旨在為圖中每個例項都提供一個畫素級別的掩膜,既保持了區分不同例項的能力,又保證了定位例項的精確性。該任務在自動駕駛,機器人等領域有廣闊的應用前景。
在本論文中,作者提出了一種全新的方式,通過一組序列性的不同的深度網路逐步將一些低階的元素不斷組合成更加複雜的結構,最終得到每個例項對應的掩膜。該方法同時解決了一些早期工作中自下而上的方法會把被隔斷的物體錯判為多個物體的問題。該方法在兩個資料集上都取得了比早期工作更好的結果。
9.Spotlight 論文:基於弱監督和自監督的深度卷積神經網路圖片縮放演算法
Weakly- and Self-Supervised Learning for Content-Aware Deep Image Retargeting
http://open.youtu.qq.com/research/publications

本論文與韓國 KAIST 大學一起合作。隨著數字顯示裝置的普及,隨之而來的一個問題就是同一張圖片在不同解析度裝置上顯示效果的適應性問題。傳統的線性縮放,或是簡單裁剪等方法會帶來諸如圖片內容扭曲、內容丟失等負面效果。
作者提出了一種利用弱監督和自監督深度卷積神經網路(WSSDCNN)來進行圖片縮放的演算法。該演算法通過建立一個在輸入圖片與目標解析度圖片之間畫素級別的對映,旨在對圖片大小進行調整的同時,儘量保留圖片中重要語義資訊的比例結構,從而避免了內容扭曲、內容丟失等傳統方法的缺陷,在最大程度上保持了圖片顯示效果的一致性。
10. Poster 論文:分割槽域多人姿態識別演算法
RMPE: Regional Multi-Person Pose Estimation
http://open.youtu.qq.com/research/publications

本論文與上海交通大學合作完成。自然場景下的多人姿態識別一直都是計算機視覺領域中較難攻克的課題之一。儘管目前人物檢測的演算法已經十分穩定,但微小的誤差仍然很難避免。
針對在人物檢測結果不準的情況下進行穩定的多人姿態識別這一問題,作者提出了一種全新的解決方案——分割槽域多人姿態識別演算法(RMPE)。該演算法綜合利用了對稱性空間遷移網路(Symmetric Spatial Transformer Network)和單人姿態估計演算法,從而擺脫了多人姿態識別任務對人物檢測準確性的依賴,並且進一步通過引數化的人物姿態表達對識別結果進行了優化。根據在公開資料集 MPII 上的測試結果,該演算法相較 CMU 提出的 OpenPose 演算法提升了 1 個百分點,尤其是對手肘、手腕、膝蓋、腳踝等細小關鍵點的改善尤為明顯。
11. Poster 論文:學習判別判別資料擬合函式來做影象的去模糊
Learning Discriminative Data Fitting Functions for Blind Image Deblurring
http://open.youtu.qq.com/research/publications

本論文與南京科學技術大學,大連理工大學和加州大學默塞德分校合作完成。本論文是關於一個用資料擬合函式來解決影象的去模糊問題。影象去模糊是一個經典的計算機視覺問題,需要合理定義資料擬合函式和影象先驗知識。但是目前的大部分演算法都是通過更好的定義影象先驗來提高去模糊的效果,對資料擬合函式的研究比較少。本文提出了一種機器學習方法來學習模糊影象和清晰影象之間的關係,從而得到更好的資料擬合函式。該擬合函式能進一步幫助估計更加準確的模糊核。該演算法在非常難的去模糊影象資料集中得到了最好結果。
12. Poster 論文:利用已知物體和物質資訊遷移的弱監督物體檢測演算法
Weakly Supervised Object Localization Using Things and Stuff Transfer
http://open.youtu.qq.com/research/publications
本論文與愛丁堡大學合作完成。本論文關注弱監督的物體檢測問題並利用已知物體(可數)和物質(不可數)資訊遷移來提供幫助。弱監督物體檢測的目標集合的中物體位置資訊未知,而源集合中對應的物體和物質的資訊包括位置、標記等則已知。源集合和目標集合中的物體類別有一定的相似性,比如外形相似或者擁有共同物質背景。 為了遷移利用這種相似性,本文作者從源集合中獲取三種資訊:一個分割模型;源集合與目標集合物體類別之間相似度;源集合中物體與物質類別之間的共生性。作者緊接著利用分割模型對目標集合圖片首先做影象分割,同時利用物體物質類別之間的相似度和共生性來修正分割結果。修正後結果被嵌入到多物體檢測框架中聯合訓練並檢測目標集合中的物體。本文演算法效果在公開資料集上超過其他現有弱監督物體檢測演算法。同時本文特別選擇了目標集和源集合差別很大的物體類別進行測試,顯示本文遷移演算法具有很強大的泛化能力。
ICCV 簡介
ICCV 全稱為 International Conference on Computer Vision(國際計算機視覺大會),由美國電氣和電子工程師學會(IEEE,Institute of Electrical & Electronic Engineers)主辦。作為世界頂級的學術會議,首屆國際計算機視覺大會於 1987 年在倫敦揭幕,其後兩年舉辦一屆。今年 ICCV 將於 10 月 22 日到 29 日在義大利威尼斯舉辦。
ICCV 作為計算機視覺領域最高階別的會議之一,是中國計算機學會推薦的 A 類會議。其論文集代表了計算機視覺領域最新的發展方向和水平。會議的論文收錄率較低,影響力遠超一般 SCI 期刊,大致與中科院 JCR 分割槽 1 區和 Web of Science 的 JCR 分割槽 Q1 中靠前的學術期刊相當。
本文為機器之心釋出,轉載請聯絡本公眾號獲得授權。