學習Opencv2.4.9(四)---SVM支援向量機
作者:咕唧咕唧liukun321
來自:http://blog.csdn.net/liukun321
- 先來看一下什麼是SVM(支援向量機)
SVM是一種訓練機器學習的演算法,可以用於解決分類和迴歸問題,同時還使用了一種稱之為kernel trick(支援向量機的核函式)的技術進行資料的轉換,然後再根據這些轉換資訊,在可能的輸出之中找到一個最優的邊界(超平面)。簡單來說,就是做一些非常複雜的資料轉換工作,然後根據預定義的標籤或者輸出進而計算出如何分離使用者的資料。
支援向量機方法是建立在統計學習理論的VC 維理論和結構風險最小原理基礎上的,根據有限的樣本資訊在模型的複雜性(即對特定訓練樣本的學習精度,Accuracy)和學習能力(即無錯誤地識別任意樣本的能力)之間尋求最佳折衷,以期獲得最好的推廣能力(或稱泛化能力)。
- 支援向量機較其他傳統機器學習演算法的優點:
1、小樣本,並不是說樣本的絕對數量少(實際上,對任何演算法來說,更多的樣本幾乎總是能帶來更好的效果),而是說與問題的複雜度比起來,SVM演算法要求的樣本數是相對比較少的。SVM解決問題的時候,和樣本的維數是無關的(甚至樣本是上萬維的都可以,這使得SVM很適合用來解決文字分類的問題,當然,有這樣的能力也因為引入了核函式)。
2、結構風險最小。(對問題真實模型的逼近與問題真實解之間的誤差,就叫做風險,更嚴格的說,誤差的累積叫做風險)。
3、非線性,是指SVM擅長應付樣本資料線性不可分的情況,主要通過鬆弛變數(也有人叫懲罰變數)和核函式技術來實現,這一部分是SVM的精髓。(關於文字分類這個問題究竟是不是線性可分的,尚沒有定論,因此不能簡單的認為它是線性可分的而作簡化處理,在水落石出之前,只好先當它是線性不可分的反正線性可分也不過是線性不可分的一種特例而已,我們向來不怕方法過於通用)。
- SVM的強大離不開一個很重要的東西--核函式:
1、為何需要核函式?
很多情況下低維空間向量集是難於劃分的,解決辦法是將它們對映到高維空間。但這個辦法帶來的艱苦就是策畫錯雜度的增長,而核函式正好奇妙地解決了這個問題。也就是說,只要選用恰當的核函式,就可以獲得高維空間的分類函式(超平面)。在SVM理論中,採取不合的核函式將導致不合的SVM演算法。在斷定了核函式之後,因為斷定核函式的已知資料也存在必然的誤差,推敲到推廣性題目,是以引入了敗壞係數以及處罰係數兩個參變數來加以校訂。
其實核函式的本質作用可以簡練概括為:將低維空間的線性不可分類問題,藉助核函式轉化為高維空間的線性可分,進而可以在高維空間找到分類的最優邊界(超平面)。(下圖引自July‘s 支援向量機通俗導論(理解SVM的三層境界))。若要要分類下圖紅色和藍色樣本點:

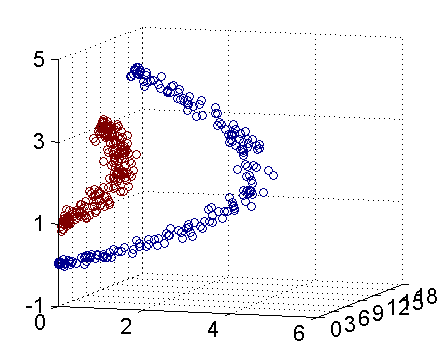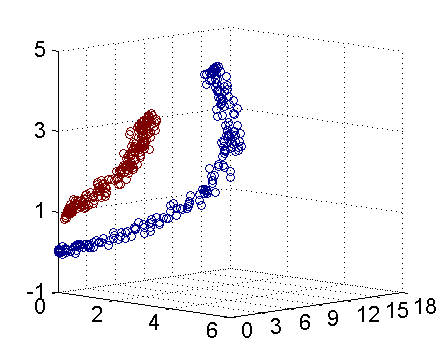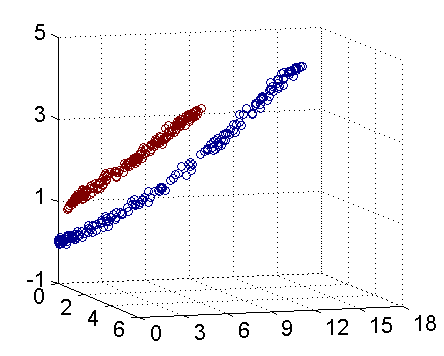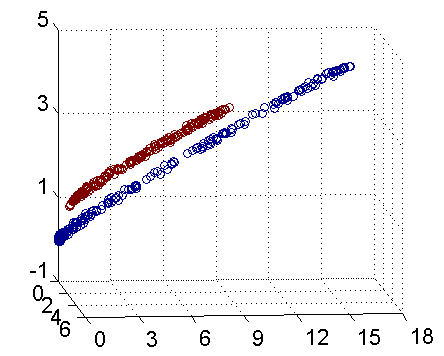
二維線性不可分 三維線性可分
2、核函式的分類
(1)線性核函式
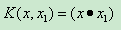
(2)多項式核函式
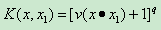
(3)徑向基(RBF)核函式(高斯核函式)
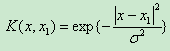
(4)Sigmoid核函式(二層神經收集核函式)
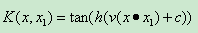
3、Opencv中的核函式定義:
CvSVM::LINEAR : 線性核心,沒有任何向對映至高維空間,線性區分(或迴歸)在原始特點空間中被完成,這是最快的選擇。
.
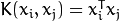
CvSVM::POLY : 多項式核心:
.
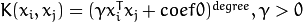
CvSVM::RBF : 基於徑向的函式,對於大多半景象都是一個較好的選擇:
.
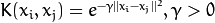
CvSVM::SIGMOID : Sigmoid函式核心:
.
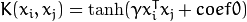
- Opencv中SVM引數設定:
Opencv中SVM引數設定使用CvSVMParams方法定義如下:
CvSVMParams::CvSVMParams(int svm_type,
int kernel_type,
double degree,
double gamma,
double coef0,
double Cvalue,
double nu,
double p,
CvMat* class_weights,
CvTermCriteria term_crit
)CvSVMParams方法如果不傳自定義引數會按如下程式碼進行預設初始化:
CvSVMParams::CvSVMParams() : svm_type(CvSVM::C_SVC), kernel_type(CvSVM::RBF), degree(0),
gamma(1), coef0(0), C(1), nu(0), p(0), class_weights(0)
{
term_crit = cvTermCriteria( CV_TERMCRIT_ITER+CV_TERMCRIT_EPS, 1000, FLT_EPSILON );
}kernel_type:SVM的核心型別(4種):
上面已經介紹過了就不再多說了。
svm_type:指定SVM的型別(5種):
1、CvSVM::C_SVC : C類支撐向量分類機。 n類分組 (n≥2),容許用異常值處罰因子C進行不完全分類。
2、CvSVM::NU_SVC :
類支撐向量分類機。n類似然不完全分類的分類器。引數為
3、CvSVM::ONE_CLASS : 單分類器,所有的練習資料提取自同一個類裡,然後SVM建樹了一個分界線以分別該類在特點空間中所佔區域和其它類在特點空間中所佔區域。
4、CvSVM::EPS_SVR :
類支撐向量迴歸機。練習集中的特點向量和擬合出來的超平面的間隔須要小於p。異常值處罰因子C被採取。
5、CvSVM::NU_SVR :
degree:核心函式(POLY)的引數degree。
gamma:核心函式(POLY/ RBF/ SIGMOID)的引數 。
。
coef0:核心函式(POLY/ SIGMOID)的引數coef0。
Cvalue:SVM型別(C_SVC/ EPS_SVR/ NU_SVR)的引數C。
nu:SVM型別(NU_SVC/ ONE_CLASS/ NU_SVR)的引數 。
p:SVM型別(EPS_SVR)的引數 。
。
class_weights:C_SVC中的可選權重,賦給指定的類,乘以C今後變成  。所以這些權重影響不合類此外錯誤分類處罰項。權重越大,某一類此外誤分類資料的處罰項就越大。
。所以這些權重影響不合類此外錯誤分類處罰項。權重越大,某一類此外誤分類資料的處罰項就越大。
term_crit:SVM的迭代練習過程的中斷前提,解決專案組受束縛二次最優題目。您可以指定的公差和/或最大迭代次數。
- Opencv中SVM訓練函式:
CvSVM::train(const CvMat* trainData,
const CvMat* responses,
const CvMat* varIdx=0,
const CvMat* sampleIdx=0,
CvSVMParams params=CvSVMParams()
)1、trainData: 練習資料,必須是CV_32FC1 (32位浮點型別,單通道)。資料必須是CV_ROW_SAMPLE的,即特點向量以行來儲存。
2、responses: 響應資料,凡是是1D向量儲存在CV_32SC1 (僅僅用在分類題目上)或者CV_32FC1格局。
3、varIdx: 指定感愛好的特點。可所以整數(32sC1)向量,例如以0為開端的索引,或者8位(8uC1)的應用的特點或者樣本的掩碼。使用者也可以傳入NULL指標,用來默示練習中應用所有變數/樣本。
4、sampleIdx: 指定感愛好的樣本。描述同上。
5、params: SVM引數。
- Opencv中的SVM識別(預言)函式:
Opencv的預言函式所有過載如下:
float CvSVM::predict(const Mat& sample, bool returnDFVal=false ) const
float CvSVM::predict(const CvMat* sample, bool returnDFVal=false ) const
float CvSVM::predict(const CvMat* samples, CvMat* results) const1、sample: 須要猜測的輸入樣本。
2、samples: 須要猜測的輸入樣本們。
3、returnDFVal: 指定返回值型別。若是值是true,則是一個2類分類題目,該辦法返回的決定計劃函式值是邊沿的符號間隔。
4、results: 響應的樣本輸出猜測的響應。
這個函式用來猜測一個新樣本的響應資料(response)。
在分類題目中,這個函式返回類別編號;在迴歸題目中,返回函式值。
輸入的樣本必須與傳給trainData的練習樣本同樣大小。
若是練習中應用了varIdx引數,必然記住在predict函式中應用跟練習特點一致的特點。
- Opencv中SVM分類問題程式碼流程:
(1)獲得練習樣本及製作其類別標籤(trainingDataMat,labelsMat)
(2)設定練習引數(CvSVMParams)
(3)對SVM進行訓練(CvSVM::train)
(4)對新的輸入樣本進行猜測(CvSVM::predict),並輸出結果型別(對應標籤)
(5)獲取支撐向量(CvSVM::get_support_vector_count,CvSVM::get_support_vector )
- SVM多類分類問題的幾種方法:
目前,構造SVM多類分類器的方法主要有兩類:一類是直接法,直接在目標函式上進行修改,將多個分類面的引數求解合併到一個最優化問題中,通過求解該最優化問題“一次性”實現多類分類。這種方法看似簡單,但其計算複雜度比較高,實現起來比較困難,只適合用於小型問題中;另一類是間接法,主要是通過組合多個二分類器來實現多分類器的構造,常見的方法有one-against-one和one-against-all兩種。
1、一對多法(one-versus-rest,簡稱OVRSVMs)。訓練時依次把某個類別的樣本歸為一類,其他剩餘的樣本歸為另一類,這樣k個類別的樣本就構造出了k個SVM。分類時將未知樣本分類為具有最大分類函式值的那類。
假如我有四類要劃分(也就是4個Label),他們是A、B、C、D。於是我在抽取訓練集的時候,分別抽取A所對應的向量作為正集,B,C,D所對應的向量作為負集;B所對應的向量作為正集,A,C,D所對應的向量作為負集;C所對應的向量作為正集,A,B,D所對應的向量作為負集;D所對應的向量作為正集,A,B,C所對應的向量作為負集,這四個訓練集分別進行訓練,然後的得到四個訓練結果檔案,在測試的時候,把對應的測試向量分別利用這四個訓練結果檔案進行測試,最後每個測試都有一個結果f1(x),f2(x),f3(x),f4(x).於是最終的結果便是這四個值中最大的一個。
PS:這種方法有種缺陷,因為訓練集是1:M,這種情況下存在偏差.因而不是很實用.
2、一對一法(one-versus-one,簡稱OVOSVMs或者pairwise)。其做法是在任意兩類樣本之間設計一個SVM,因此k個類別的樣本就需要設計k(k-1)/2個SVM。當對一個未知樣本進行分類時,最後得票最多的類別即為該未知樣本的類別。Libsvm中的多類分類就是根據這個方法實現的。
還是假設有四類A,B,C,D四類。在訓練的時候我選擇A,B;A,C; A,D; B,C;B,D;C,D所對應的向量作為訓練集,然後得到六個訓練結果,在測試的時候,把對應的向量分別對六個結果進行測試,然後採取投票形式,最後得到一組結果。
3、層次支援向量機(H-SVMs)。層次分類法首先將所有類別分成兩個子類,再將子類進一步劃分成兩個次級子類,如此迴圈,直到得到一個單獨的類別為止。
4、DAG-SVMS是由Platt提出的決策導向的迴圈圖DDAG匯出的,是針對“一對一”SVMS存在誤分、拒分現象提出的。
這裡僅僅是對幾種多分類方法的簡要說明,如果直接呼叫Opencv的predict方法,並不需要關心多分類演算法的具體實現,來看看下面的例子:
- Opencv中SVM多類分類問題程式設計例項:
#include <cv.h>
#include <highgui.h>
#include <ml.h>
#include <cxcore.h>
#include <iostream>
using namespace std;
int main()
{
// step 1:
//訓練資料的分類標記,即4類
float labels[16] = {1.0, 1.0,1.0,1.0,2.0,2.0,2.0,2.0,3.0,3.0,3.0,3.0,4.0,4.0,4.0,4.0};
CvMat labelsMat = cvMat(16, 1, CV_32FC1, labels);
//訓練資料矩陣
float trainingData[16][2] = { {0, 0}, {4, 1}, {4, 5}, {-1, 6},{3,11},{-2,10},{4,30},{0,25},{10,13},{15,12},{25,40},{11,35},{8,1},{9,6},{15,5},{20,-1} };
CvMat trainingDataMat = cvMat(16, 2, CV_32FC1, trainingData);
// step 2:
//訓練引數設定
CvSVMParams params;
params.svm_type = CvSVM::C_SVC; //SVM型別
params.kernel_type = CvSVM::LINEAR; //核函式的型別
//SVM訓練過程的終止條件, max_iter:最大迭代次數 epsilon:結果的精確性
params.term_crit = cvTermCriteria(CV_TERMCRIT_ITER, 100, FLT_EPSILON );
// step 3:
//啟動訓練過程
CvSVM SVM;
SVM.train( &trainingDataMat, &labelsMat, NULL,NULL, params);
// step 4:
//使用訓練所得模型對新樣本進行分類測試
for (int i=-5; i<15; i++)
{
for (int j=-5; j<15; j++)
{
float a[] = {i,j};
CvMat sampleMat;
cvInitMatHeader(&sampleMat,1,2,CV_32FC1,a);
cvmSet(&sampleMat,0,0,i); // Set M(i,j)
cvmSet(&sampleMat,0,1,j); // Set M(i,j)
float response = SVM.predict(&sampleMat);
cout<<response<<" ";
}
cout<<endl;
}
// step 5:
//獲取支援向量
int c = SVM.get_support_vector_count();
cout<<endl;
for (int i=0; i<c; i++)
{
const float* v = SVM.get_support_vector(i);
cout<<*v<<" ";
}
cout<<endl;
system("pause");
return 0;
}執行結果:
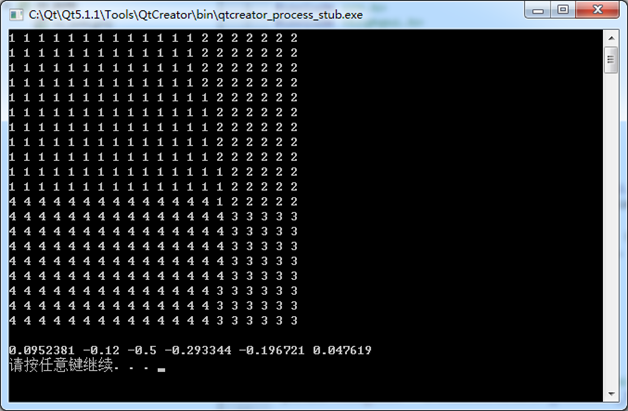
PS: 統計學習泛化誤差界的概念,就是指真實風險應該由兩部分內容刻畫,一是經驗風險,代表了分類器在給定樣本上的誤差;二是置信風險,代表了我們在多大程度上可以信任分類器在未知文字上分類的結果。很顯然,第二部分是沒有辦法精確計算的,因此只能給出一個估計的區間,也使得整個誤差只能計算上界,而無法計算準確的值(所以叫做泛化誤差界,而不叫泛化誤差)。
置信風險與兩個量有關,一是樣本數量,顯然給定的樣本數量越大,我們的學習結果越有可能正確,此時置信風險越小;二是分類函式的VC維,顯然VC維越大,推廣能力越差,置信風險會變大。
泛化誤差界的公式為:R(w)≤Remp(w)+Ф(n/h)
公式中R(w)就是真實風險,Remp(w)就是經驗風險,Ф(n/h)就是置信風險。統計學習的目標從經驗風險最小化變為了尋求經驗風險與置信風險的和最小,即結構風險最小。
SVM正是這樣一種努力最小化結構風險的演算法。
相關文章
- 學習SVM(四) 理解SVM中的支援向量(Support Vector)
- 機器學習:支援向量機(SVM)機器學習
- 機器學習——支援向量機(SVM)機器學習
- [譯] 支援向量機(SVM)教程
- 機器學習——支援向量機SVM(一)機器學習
- 我的OpenCV學習筆記(六):使用支援向量機(SVM)OpenCV筆記
- 支援向量機(Support Vector Machine,SVM)—— 線性SVMMac
- 機器學習(四):通俗理解支援向量機SVM及程式碼實踐機器學習
- 學習SVM(二) 如何理解支援向量機的最大分類間隔
- 人工智慧-機器學習-支援向量機SVM人工智慧機器學習
- 分類演算法-支援向量機 SVM演算法
- 機器學習基礎專題:支援向量機SVM機器學習
- 支援向量機SVM:從數學原理到實際應用
- 支援向量機(SVM)和python實現(二)Python
- SVM 支援向量機演算法-原理篇演算法
- SVM 支援向量機演算法-實戰篇演算法
- OpenCV筆記(3)實現支援向量機(SVM)OpenCV筆記
- 演算法金 | 再見,支援向量機 SVM!演算法
- 監督學習之支援向量機
- 【Python機器學習實戰】感知機和支援向量機學習筆記(三)之SVM的實現Python機器學習筆記
- 機器學習演算法筆記之5:支援向量機SVM機器學習演算法筆記
- 支援向量機 (二): 軟間隔 svm 與 核函式函式
- 《機器學習_07_01_svm_硬間隔支援向量機與SMO》機器學習
- 機器學習基礎篇:支援向量機(SVM)理論與實踐機器學習
- 支援向量機(SVM)從原理到python程式碼實現Python
- 統計學習方法(四) 支撐向量機
- 《機器學習_07_03_svm_核函式與非線性支援向量機》機器學習函式
- 吳恩達《Machine Learning》精煉筆記 7:支援向量機 SVM吳恩達Mac筆記
- 一文讀懂支援向量機SVM(附實現程式碼、公式)公式
- 支援向量機原理(一) 線性支援向量機
- 支援向量機
- 支援向量機原理(四)SMO演算法原理演算法
- 理解支援向量機
- 第八篇:支援向量機 (SVM)分類器原理分析與基本應用
- 《吳恩達機器學習》學習筆記007_支援向量機吳恩達機器學習筆記
- 機器學習之-搞定支援向量機(SVM)【人工智慧工程師--AI轉型必修課】機器學習人工智慧工程師AI
- 支援向量機(SVM)的約束和無約束優化、理論和實現優化
- 學習OpenCV——SVMOpenCV