opencv中的SVM影像分類(二)
原創作品 轉載請註明出http://blog.csdn.net/always2015/article/details/47107129
上一篇博文對影像分類理論部分做了比較詳細的講解,這一篇主要是對影像分類程式碼的實現進行分析。理論部分我們談到了使用BOW模型,但是BOW模型如何構建以及整個步驟是怎麼樣的呢?可以參考下面的部落格http://www.cnblogs.com/yxy8023ustc/p/3369867.html,這一篇部落格很詳細講解了BOW模型的步驟了,主要包含以下四個步驟:
- 提取訓練集中圖片的feature
- 將這些feature聚成n類。這n類中的每一類就相當於是圖片的“單詞”,所有的n個類別構成“詞彙表”。我的實現中n取1000,如果訓練集很大,應增大取值。
- 對訓練集中的圖片構造bag of words,就是將圖片中的feature歸到不同的類中,然後統計每一類的feature的頻率。這相當於統計一個文字中每一個單詞出現的頻率
- 訓練一個多類分類器,將每張圖片的bag of words作為feature vector,將該張圖片的類別作為label。
對於未知類別的圖片,計算它的bag of words,使用訓練的分類器進行分類。
上面整個工程步驟所涉及到的函式,我都放在一個類categorizer裡,
下面按步驟說明具體實現,程式示例有所省略,完整的程式可看工程原始碼。
NO.1、特徵提取
對圖片特徵的提取包括對每張訓練圖片的特徵提取和每張待檢測圖片特徵的提取,我使用的是surf,所以使用opencv的SurfFeatureDetector檢測特徵點,然後再用SurfDescriptorExtractor抽取特徵點描述符。對於特徵點的檢測和特徵描述符的講解可以參考中文opencv中文官網http://www.opencv.org.cn/opencvdoc/2.3.2/html/doc/tutorials/features2d/feature_detection/feature_detection.html#feature-detection以及http://www.opencv.org.cn/opencvdoc/2.3.2/html/doc/tutorials/features2d/feature_description/feature_description.html#feature-description
我訓練圖片特徵提取的示例程式碼如下:
Mat vocab_descriptors;
// 對於每一幅模板,提取SURF運算元,存入到vocab_descriptors中
multimap<string,Mat> ::iterator i=train_set.begin();
for(;i!=train_set.end();i++)
{
vector<KeyPoint>kp;
Mat templ=(*i).second;
Mat descrip;
featureDecter->detect(templ,kp);
descriptorExtractor->compute(templ,kp,descrip);
//push_back(Mat);在原來的Mat的最後一行後再加幾行,元素為Mat時, 其型別和列的數目 必須和矩陣容器是相同的
vocab_descriptors.push_back(descrip);
}注意:上述程式碼只是工程的一個很小的部分,有些變數在類中已經定義,在這裡沒有貼出來,例如上述的train_set訓練圖片的對映,定義為:
//從類目名稱到訓練圖集的對映,關鍵字可以重複出現
multimap<string,Mat> train_set;將每張圖片的特徵描述符儲存起來vocab_descriptors,然後為後面聚類和構造訓練圖片詞典做準備。
NO.2、feature聚類
由於opencv封裝了一個類BOWKMeansExtractor[2],這一步非常簡單,將所有圖片的feature vector丟給這個類,然後呼叫cluster()就可以訓練(使用KMeans方法)出指定數量(步驟介紹中提到的n)的類別。輸入vocab_descriptors就是第1步計算得到的結果,返回的vocab是一千個向量,每個向量是某個類別的feature的中心點。
示例程式碼如下:
//將每一副圖的Surf特徵利用add函式加入到bowTraining中去,就可以進行聚類訓練了
bowtrainer->add(vocab_descriptors);
// 對SURF描述子進行聚類
vocab=bowtrainer->cluster();bowtrainer的定義如下:
bowtrainer=new BOWKMeansTrainer(clusters);NO.3、構造bag of words
對每張圖片的特徵點,將其歸到前面計算的類別中,統計這張圖片各個類別出現的頻率,作為這張圖片的bag of words。由於opencv封裝了BOWImgDescriptorExtractor[2]這個類,這一步也走得十分輕鬆,只需要把上面計算的vocab丟給它,然後用一張圖片的特徵點作為輸入,它就會計算每一類的特徵點的頻率。
allsamples_bow這個map的key就是某個類別,value就是這個類別中所有圖片的bag of words,即Mat中每一行都表示一張圖片的bag of words。
//對每張圖片的特徵點,統計這張圖片各個類別出現的頻率,作為這張圖片的bag of words
bowDescriptorExtractor->setVocabulary(vocab);
}
// 對於每一幅模板,提取SURF運算元,存入到vocab_descriptors中
multimap<string,Mat> ::iterator i=train_set.begin();
for(;i!=train_set.end();i++)
{
vector<KeyPoint>kp;
string cate_nam=(*i).first;
Mat tem_image=(*i).second;
Mat imageDescriptor;
featureDecter->detect(tem_image,kp);
bowDescriptorExtractor->compute(tem_image,kp,imageDescriptor);
//push_back(Mat);在原來的Mat的最後一行後再加幾行,元素為Mat時, 其型別和列的數目 必須和矩陣容器是相同的
allsamples_bow[cate_nam].push_back(imageDescriptor);
}上面部分變數的定義如下:
//存放所有訓練圖片的BOW
map<string,Mat> allsamples_bow;
//特徵檢測器detectors與描述子提取器extractors 泛型控制程式碼類Ptr
Ptr<FeatureDetector> featureDecter;
Ptr<DescriptorExtractor> descriptorExtractor;
Ptr<BOWKMeansTrainer> bowtrainer;
Ptr<BOWImgDescriptorExtractor> bowDescriptorExtractor;
Ptr<FlannBasedMatcher> descriptorMacher;NO.4、訓練分類器
我使用的分類器是svm,用經典的1 vs all方法實現多類分類。對每一個類別都訓練一個二元分類器。訓練好後,對於待分類的feature vector,使用每一個分類器計算分在該類的可能性,然後選擇那個可能性最高的類別作為這個feature vector的類別。
訓練二元分類器
allsamples_bow:第3步中得到的結果。
category_name:針對哪個類別訓練分類器。
svmParams:訓練svm使用的引數。
stor_svms:針對category_name的分類器。
屬於category_name的樣本,label為1;不屬於的為-1。準備好每個樣本及其對應的label之後,呼叫CvSvm的train方法就可以了。
示例程式碼如下:
stor_svms=new CvSVM[categories_size];
//設定訓練引數
SVMParams svmParams;
svmParams.svm_type = CvSVM::C_SVC;
svmParams.kernel_type = CvSVM::LINEAR;
svmParams.term_crit = cvTermCriteria(CV_TERMCRIT_ITER, 100, 1e-6);
cout<<"訓練分類器..."<<endl;
for(int i=0;i<categories_size;i++)
{
Mat tem_Samples( 0, allsamples_bow.at( category_name[i] ).cols, allsamples_bow.at( category_name[i] ).type() );
Mat responses( 0, 1, CV_32SC1 );
tem_Samples.push_back( allsamples_bow.at( category_name[i] ) );
Mat posResponses( allsamples_bow.at( category_name[i]).rows, 1, CV_32SC1, Scalar::all(1) );
responses.push_back( posResponses );
for ( auto itr = allsamples_bow.begin(); itr != allsamples_bow.end(); ++itr )
{
if ( itr -> first == category_name[i] ) {
continue;
}
tem_Samples.push_back( itr -> second );
Mat response( itr -> second.rows, 1, CV_32SC1, Scalar::all( -1 ) );
responses.push_back( response );
}
stor_svms[i].train( tem_Samples, responses, Mat(), Mat(), svmParams );
//儲存svm
string svm_filename=string(DATA_FOLDER) + category_name[i] + string("SVM.xml");
stor_svms[i].save(svm_filename.c_str());
}對於SVM的引數以及函式呼叫的介紹可以參考中文官網http://www.opencv.org.cn/opencvdoc/2.3.2/html/doc/tutorials/ml/introduction_to_svm/introduction_to_svm.html#introductiontosvms
部分變數的定義如下:
// 訓練得到的SVM
CvSVM *stor_svms;
//類目名稱,也就是TRAIN_FOLDER設定的目錄名
vector<string> category_name;
//類目數目
int categories_size;
NO.5、對未知圖片進行分類
分類
使用某張待分類圖片的bag of words作為feature vector輸入,使用每一類的分類器計算判為該類的可能性,然後使用可能性最高的那個類別作為這張圖片的類別。
prediction_category就是結果,test就是某張待分類圖片的bag of words。示例程式碼如下:
Mat input_pic=imread(train_pic_path);
imshow("輸入圖片:",input_pic);
cvtColor(input_pic,gray_pic,CV_BGR2GRAY);
// 提取BOW描述子
vector<KeyPoint>kp;
Mat test;
featureDecter->detect(gray_pic,kp);
bowDescriptorExtractor->compute(gray_pic,kp,test);
float scoreValue = stor_svms[i].predict( test, true );
float classValue = stor_svms[i].predict( test, false );
sign = ( scoreValue < 0.0f ) == ( classValue < 0.0f )? 1 : -1;
curConfidence = sign * stor_svms[i].predict( test, true );
if(curConfidence>best_score)
{
best_score=curConfidence;
prediction_category=cate_na;
}上面就是四個主要步驟的部分示例程式碼,很多其他部分程式碼沒有貼出來,比如說如何遍歷資料夾下面的所有不同類別的圖片,因為訓練圖片的樣本比較多的話,訓練圖片是一個時間比較長久的,那麼如何在對一張待測圖片進行分類的時候,不需要每次都重複訓練樣本,而是直接讀取之前已經訓練好的BOW。。。。很多很多。
我的main函式實現如下:
int main(void)
{
int clusters=1000;
//初始化
categorizer c(clusters);
//特徵聚類
c.bulid_vacab();
//構造BOW
c.compute_bow_image();
//訓練分類器
c.trainSvm();
//將測試圖片分類
c.category_By_svm();
return 0;
}下面來看看我的工程部分執行結果如下:
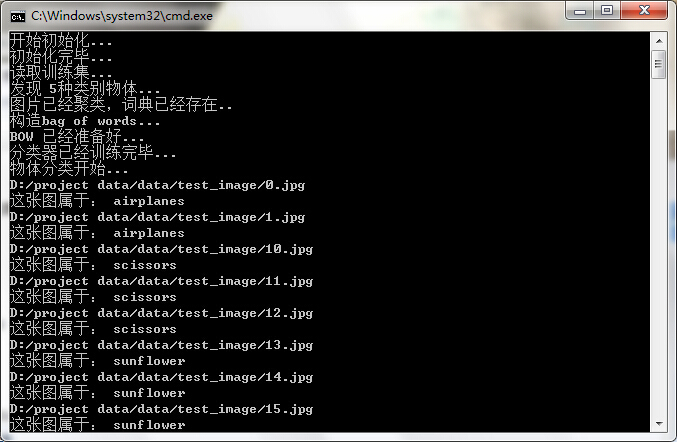
部分分類下圖所示:

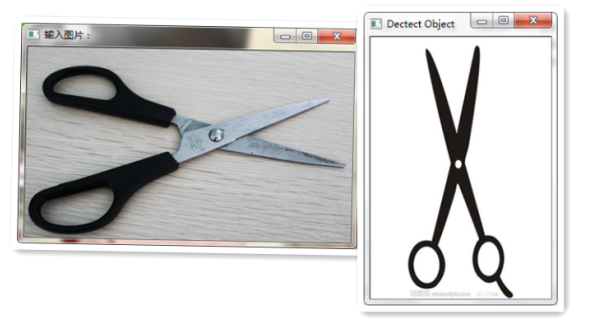
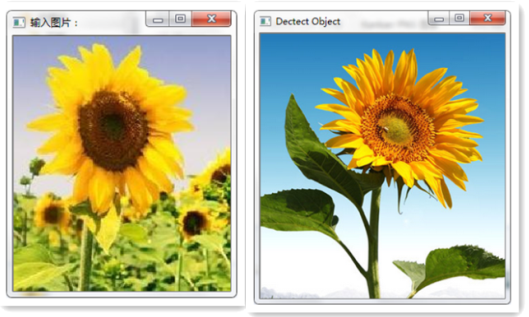
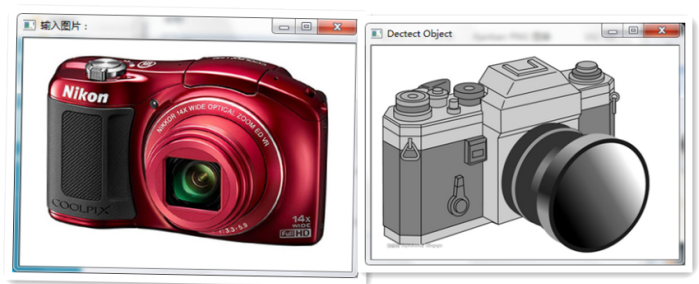
左邊為輸入圖片,右邊為所匹配的類別模型。準確率為百分之八九十。
我的整個工程檔案以及我的所有訓練的圖片存放在這裡http://download.csdn.net/detail/always2015/8944973以及http://download.csdn.net/detail/always2015/8944959,需要的可以下載,自己在找訓練圖片寫程式碼花了很多時間,下載完後自行解壓,project data資料夾直接放在D盤就行,裡面存放訓練的圖片和待測試圖片,以及訓練過程中生成的中間檔案,另一個資料夾object_classfication_end則是工程檔案,我用的是vs2010開啟即可,下面工程裡有幾個要注意的地方:
1、在這個模組中使用到了c++的boost庫,但是在這裡有一個版本的限制。這個模組的程式碼只能在boost版本1.46以上使用,這個版本以下的就不能用了,直接執行就會出錯,這是最需要注意的。因為在1.46版本以上中對比CsSVM這個類一些成員函式做了一些私有化的修改,所以在使用該類初始化物件時候需要注意。
2、我的模組所使用到的函式和產生的中間結果都是在一個categorizer類中宣告的,由於不同的執行階段中間結果有很多個,例如:訓練圖片聚類後所得到單詞表矩陣,svm分類器的訓練的結果等,中間結果的產生是相當耗時的,所以在剛開始就考慮到第一次執行時候把他以檔案XML的格式儲存下來,下次使用到的時候在讀取。將一個矩陣存入文字的時候可以直接用輸出流的方式將一個矩陣存入,但是讀取時候如果用輸入流直接一個矩陣變數的形式讀取,那就肯定報錯,因為輸入流不支援直接對矩陣的操作,所以這時候只能對矩陣的元素一個一個進行讀取了。
3、在測試的時候,如果輸入的圖片太小,或者全為黑色,當經過特徵提取和單詞構造完成使用svm進行分類時候會出現錯誤。經過除錯程式碼,發現上述圖片在生成該圖片的單詞的時候所得到的單詞矩陣會是一個空矩陣,即該矩陣的行列數都為0,所以在使用svm分類器時候就出錯。所以在使用每個輸入圖片的單詞矩陣的時候先做一個判斷,如果該矩陣行列數都為0,那麼該圖片直接跳過。
相關文章
- opencv中的SVM影像分類(一)OpenCV
- opencv svm分類OpenCV
- opencv SVM分類DemoOpenCV
- 學習SVM(一) SVM模型訓練與分類的OpenCV實現模型OpenCV
- opencv中SVMOpenCV
- opencv中svm原始碼OpenCV原始碼
- OpenCV中的SVM引數優化OpenCV優化
- opencv SVM的使用OpenCV
- OpenCV的SVM用法OpenCV
- Opencv中SVM樣本訓練、歸類流程及實現OpenCV
- OpenCV 與 SVMOpenCV
- opencv SVM 使用OpenCV
- SVM多分類器的實現(Opencv3,C++)OpenCVC++
- opencv-python 影像 二OpenCVPython
- 基於Tensorflow + Opencv 實現CNN自定義影像分類OpenCVCNN
- opencv + SVM 程式碼OpenCV
- 學習OpenCV——SVMOpenCV
- openCV中的影像處理 3 影像閾值OpenCV
- 『sklearn學習』不同的 SVM 分類器
- 「影像分類」 實戰影像分類網路的視覺化視覺化
- OpenCV探索之路(二十八):Bag of Features(BoF)影像分類實踐OpenCV
- python中的scikit-learn庫來實現SVM分類器。Python
- OpenCV進階---介紹SVMOpenCV
- OpenCV中使用SVM簡介OpenCV
- 【Svm機器學習篇】Opencv3.4.1與C++實現對分類問題的訓練與預測】機器學習OpenCVC++
- 分類演算法-支援向量機 SVM演算法
- 樸素貝葉斯/SVM文字分類文字分類
- 手把手教你使用LabVIEW OpenCV dnn實現影像分類(含原始碼)ViewOpenCVDNN原始碼
- 【數字影像處理6】python+opencv使用LBP、HOG提取特徵來分類人臉【更新中】PythonOpenCVHOG特徵
- 演算法影像崗-影像分類與影像分割演算法
- opencv 影像腐蝕、影像的膨脹OpenCV
- Spark MLlib SVM 文字分類器實現Spark文字分類
- opencv 影像的入門OpenCV
- OpenCV與影像處理學習二——影像基礎知識(下)OpenCV
- matlab中的分類器使用小結(SVM、KNN、RF、AdaBoost、Naive Bayes、DAC)MatlabKNNAI
- OPENCV SVM介紹和自帶例子OpenCV
- Opencv 用SVM訓練檢測器OpenCV
- SVM分類器演算法總結&應用演算法