verilog實現乘法器
以下介紹兩種實現乘法器的方法:序列乘法器和流水線乘法器。
兩個N位二進位制數x、y的乘積用簡單的方法計算就是利用移位操作來實現。
其框圖如下:
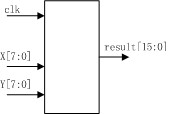
其狀態圖如下:
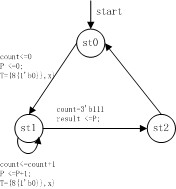
其實現的程式碼如下:
modulemulti_CX(clk, x, y, result); |
02 | |
03 | inputclk; |
04 | input[7:0] x, y; |
05 | output[15:0] result; |
06 |
07 | reg[15:0] result; |
08 |
09 | parameters0 = 0, s1 = 1, s2 = 2; |
10 | reg[2:0] count = 0; |
11 | reg[1:0] state = 0; |
12 | reg[15:0] P, T; |
13 | reg[7:0] y_reg; |
14 |
15 | always@(posedgeclk)begin |
16 | case(state) |
17 | s0:begin |
18 | count <= 0; |
19 | P <= 0; |
20 | y_reg <= y; |
21 | T <= {{8{1'b0}}, x}; |
22 | state <= s1; |
23 | end |
24 | s1:begin |
25 | if(count ==3'b111) |
26 | state <= s2; |
27 | elsebegin |
28 | if(y_reg[0] ==1'b1) |
29 | P <= P + T; |
30 | else |
31 | P <= P; |
32 | y_reg <= y_reg >> 1; |
33 | T <= T << 1; |
34 | count <= count + 1; |
35 | state <= s1; |
36 | end |
37 | end |
38 | s2:begin |
39 | result <= P; |
40 | state <= s0; |
41 | end |
42 | default: ; |
43 | endcase |
44 | end |
45 |
46 | endmodule |
優點:該乘法器所佔用的資源是所有型別乘法器中最少的,在低速的訊號處理中有廣泛的使用。
2)流水線乘法器
一般的快速乘法器通常採用逐位並行的迭代陣列結構,將每個運算元的N位都並行地提交給乘法器。但是一般對於FPGA來講,進位的速度快於加法的速度,這種陣列結構並不是最優的。所以可以採用多級流水線的形式,將相鄰的兩個部分乘積結果再加到最終的輸出乘積上,即排成一個二叉樹形式的結構,這樣對於N位乘法器需要log2(N)級來實現,
一個8位乘法器,其原理圖如下圖所示:
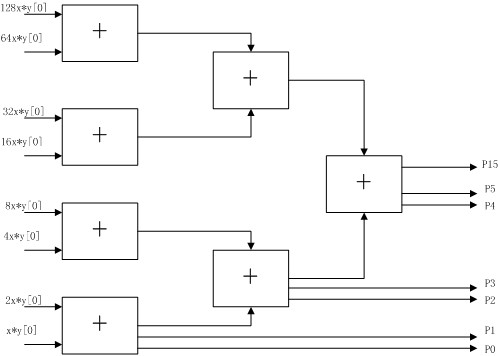
其實現的程式碼如下:
module multi_4bits_pipelining(mul_a, mul_b, clk, rst_n, mul_out);
input [3:0] mul_a, mul_b;
input clk;
input rst_n;
output [15:0] mul_out;
reg [15:0] mul_out;
reg [15:0] stored0;
reg [15:0] stored1;
reg [15:0] stored2;
reg [15:0] stored3;
reg [15:0] stored4;
reg [15:0] stored5;
reg [15:0] stored6;
reg [15:0] stored7;
reg [15:0] mul_out01;
reg [15:0] mul_out23;
reg [15:0] add01;
reg [15:0] add23;
reg [15:0] add45;
reg [15:0] add67;
always @(posedge clk or negedge rst_n) begin
if(!rst_n) begin
mul_out <= 0;
stored0 <= 0;
stored1 <= 0;
stored2 <= 0;
stored3 <= 0;
stored4 <= 0;
stored5 <= 0;
stored6 <= 0;
stored7 <= 0;
add01 <= 0;
add23 <= 0;
add45 <= 0;
add67 <= 0;
end
else begin
stored0 <= mul_b[0]? {8'b0, mul_a} : 16'b0;
stored1 <= mul_b[1]? {7'b0, mul_a, 1'b0} : 16'b0;
stored2 <= mul_b[2]? {6'b0, mul_a, 2'b0} : 16'b0;
stored3 <= mul_b[3]? {5'b0, mul_a, 3'b0} : 16'b0;
stored4 <= mul_b[0]? {4'b0, mul_a, 4'b0} : 16'b0;
stored5 <= mul_b[1]? {3'b0, mul_a, 5'b0} : 16'b0;
stored6 <= mul_b[2]? {2'b0, mul_a, 6'b0} : 16'b0;
stored7 <= mul_b[3]? {1'b0, mul_a, 7'b0} : 16'b0;
add01 <= stored1 + stored0;
add23 <= stored3 + stored2;
add45 <= stored5 + stored4;
add67 <= stored7 + stored6;
mul_out01 <= add01 + add23;
mul_out23 <= add45 + add67;
mul_out <= mul_out01 + mul_out23;
end
end
endmodule
流水線乘法器比序列乘法器的速度快很多很多,在非高速的訊號處理中有廣泛的應用。至於高速訊號的乘法一般需要利用FPGA晶片中內嵌的硬核DSP單元來實現。
注:本文大部分內容轉自http://www.cnblogs.com/shengansong/archive/2011/05/23/2054401.html。
相關文章
- 基於Verilog的陣列乘法器設計陣列
- 用verilog實現搶答器
- verilog 中實現 sram 程式碼
- Verilog實現加減乘除運算
- 基於FPGA的乘法器原理介紹及設計實現FPGA
- 【iCore4 雙核心板_FPGA】例程八:乘法器實驗——乘法器使用FPGA
- 【iCore3 雙核心板_FPGA】例程十一:乘法器實驗——乘法器使用FPGA
- 【iCore1S 雙核心板_FPGA】例程十:乘法器實驗——乘法器的使用FPGA
- verilog實現矩陣卷積運算矩陣卷積
- Verilog設計技巧例項及實現
- FPGA排序模組與verilog實現【含原始碼!!!】FPGA排序原始碼
- VIVADO vhdl verilog 實現矩陣運算矩陣
- verilog使用Mealy電路實現交通燈
- Verilog乘法的實現——幾種使用多級流水實現方法對比(2)
- 移位相加乘法器
- 學習筆記-Verilog實現IIC匯流排協議筆記協議
- RGB2YUV 的verilog實現(RGB轉YUV)
- verilog的RR輪詢排程演算法的程式碼實現演算法
- FSM自動售貨機 verilog 實現及 code 細節講解
- verilog實現格雷碼和二進位制碼的相互轉換
- CORDIC演算法解釋及verilog HDL實現(圓座標系)演算法
- verilog實現基於Cordic演算法的雙曲函式計算演算法函式
- 搭建verilog/systemverilog學習環境
- 用verilog/systemverilog 設計fifo (1)
- 用verilog/systemverilog 設計fifo (2)
- m基於FPGA的Alamouti編碼verilog實現,包含testbench測試檔案FPGA
- 基於FPGA的BPSK數字平方環載波同步verilog實現,包含testbenchFPGA
- USB中TOKEN的CRC5與CRC16校驗(神奇的工具生成Verilog實現)
- Verilog 監控 Monitor
- FPGA學習(第10節)-模組的例化-Verilog層次化設計實現LED流水燈FPGA
- (2)verilog與Systemverilog兩種語言編寫打兩拍
- 八位“Booth二位乘演算法”乘法器boot演算法
- Verilog例項陣列陣列
- Verilog程式碼風格
- m基於FPGA的電子鐘verilog實現,可設定鬧鐘,包含testbench測試檔案FPGA
- 基於FPGA的NC影像質量評估verilog實現,包含testbench和MATLAB輔助驗證程式FPGAMatlab
- SystemVerilog 語言部分(二)
- SystemVerilog 類和物件(三)物件