NMF 非負矩陣分解(Non-negative Matrix Factorization)實踐
1. NMF-based 推薦演算法
在例如Netflix或MovieLens這樣的推薦系統中,有使用者和電影兩個集合。給出每個使用者對部分電影的打分,希望預測該使用者對其他沒看過電影的打分值,這樣可以根據打分值為其做出推薦。使用者和電影的關係,可以用一個矩陣來表示,每一列表示使用者,每一行表示電影,每個元素的值表示使用者對已經看過的電影的打分。下面來簡單介紹一下基於NMF的推薦演算法。
在python當中有一個包叫做sklearn,專門用來做機器學習,各種大神的實現演算法都在裡面。本文使用
from sklearn.decomposition import NMF
資料
電影的名稱,使用10個電影作為例子:
item = [
'希特勒回來了', '死侍', '房間', '龍蝦', '大空頭',
'極盜者', '裁縫', '八惡人', '實習生', '間諜之橋',
]使用者名稱稱,使用15個使用者作為例子:
user = ['五柳君', '帕格尼六', '木村靜香', 'WTF', 'airyyouth',
'橙子c', '秋月白', 'clavin_kong', 'olit', 'You_某人',
'凜冬將至', 'Rusty', '噢!你看!', 'Aron', 'ErDong Chen']使用者評分矩陣:
RATE_MATRIX = np.array(
[[5, 5, 3, 0, 5, 5, 4, 3, 2, 1, 4, 1, 3, 4, 5],
[5, 0, 4, 0, 4, 4, 3, 2, 1, 2, 4, 4, 3, 4, 0],
[0, 3, 0, 5, 4, 5, 0, 4, 4, 5, 3, 0, 0, 0, 0],
[5, 4, 3, 3, 5, 5, 0, 1, 1, 3, 4, 5, 0, 2, 4],
[5, 4, 3, 3, 5, 5, 3, 3, 3, 4, 5, 0, 5, 2, 4],
[5, 4, 2, 2, 0, 5, 3, 3, 3, 4, 4, 4, 5, 2, 5],
[5, 4, 3, 3, 2, 0, 0, 0, 0, 0, 0, 0, 2, 1, 0],
[5, 4, 3, 3, 2, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1],
[5, 4, 3, 3, 1, 0, 0, 0, 0, 0, 0, 0, 0, 2, 2],
[5, 4, 3, 3, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1]]
)使用者和電影的NMF分解矩陣,其中nmf_model為NMF的類,user_dis為W矩陣,item_dis為H矩陣,R設定為2:
nmf_model = NMF(n_components=2) # 設有2個主題
item_dis = nmf_model.fit_transform(RATE_MATRIX)
user_dis = nmf_model.components_先來看看我們的矩陣最後是什麼樣子:
print('使用者的主題分佈:')
print(user_dis)
print('電影的主題分佈:')
print(item_dis)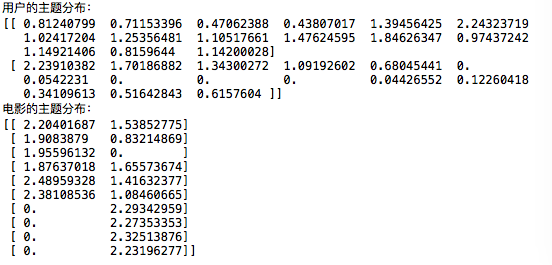
雖然把矩陣都顯示出來了,但是仍然看著不太好觀察,於是我們可以把電影主題分佈矩陣和使用者分佈矩陣畫出來:
plt1 = plt
plt1.plot(item_dis[:, 0], item_dis[:, 1], 'ro')
plt1.draw()#直接畫出矩陣,只打了點,下面對圖plt1進行一些設定
plt1.xlim((-1, 3))
plt1.ylim((-1, 3))
plt1.title(u'the distribution of items (NMF)')#設定圖的標題
count = 1
zipitem = zip(item, item_dis)#把電影標題和電影的座標聯絡在一起
for item in zipitem:
item_name = item[0]
data = item[1]
plt1.text(data[0], data[1], item_name,
fontproperties=fontP,
horizontalalignment='center',
verticalalignment='top')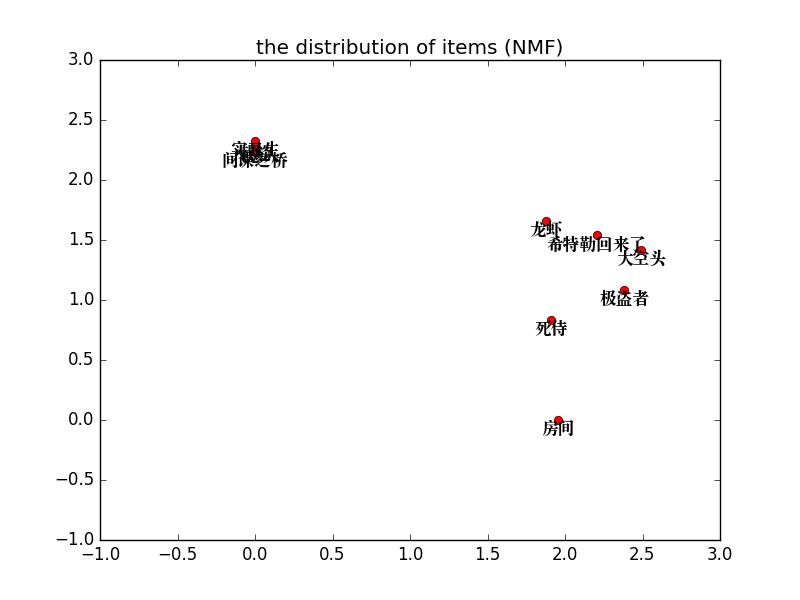
做到這裡,我們從上面的圖可以看出電影主題劃分出來了,使用KNN或者其他距離度量演算法可以把電影分為兩大類,也就是根據之前的NMF矩陣分解時候設定的n_components=2有關。後面對這個n_components的值進行解釋。
好我們再來看看使用者的主題劃分:
user_dis = user_dis.T #把轉置使用者分佈矩陣
plt1 = plt
plt1.plot(user_dis[:, 0], user_dis[:, 1], 'ro')
plt1.xlim((-1, 3))
plt1.ylim((-1, 3))
plt1.title(u'the distribution of user (NMF)')#設定圖的標題
zipuser = zip(user, user_dis)#把電影標題和電影的座標聯絡在一起
for user in zipuser:
user_name = user[0]
data = user[1]
plt1.text(data[0], data[1], user_name,
fontproperties=fontP,
horizontalalignment='center',
verticalalignment='top')
plt1.show()#直接畫出矩陣,只打了點,下面對圖plt1進行一些設定
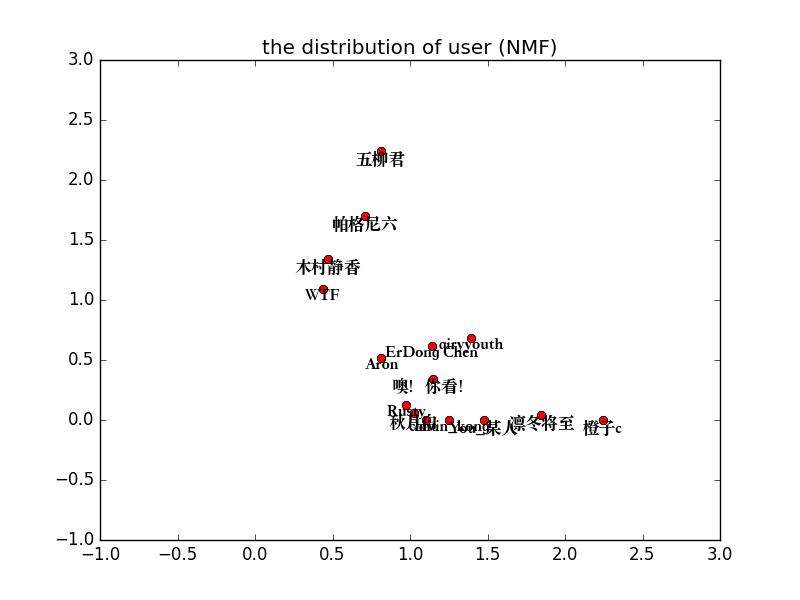
從上圖可以看出來,使用者’五柳君’, ‘帕格尼六’, ‘木村靜香’, ‘WTF’具有類似的距離度量相似度,其餘11個使用者具有類似的距離度量相似度。
推薦
對於NMF的推薦很簡單
- 1.求出使用者沒有評分的電影,因為在numpy的矩陣裡面保留小數位8位,判斷是否為零使用1e-8(後續可以方便調節引數),當然你沒有那麼嚴謹的話可以用 = 0。
- 2.求過濾評分的新矩陣,使用NMF分解的使用者特徵矩陣和電影特徵矩陣點乘。
- 3.求出要求得使用者沒有評分的電影列表並根據大小排列,就是最後要推薦給使用者的電影id了。
filter_matrix = RATE_MATRIX < 1e-8
rec_mat = np.dot(item_dis, user_dis)
print('重建矩陣,並過濾掉已經評分的物品:')
rec_filter_mat = (filter_matrix * rec_mat).T
print(rec_filter_mat)
rec_user = '凜冬將至' # 需要進行推薦的使用者
rec_userid = user.index(rec_user) # 推薦使用者ID
rec_list = rec_filter_mat[rec_userid, :] # 推薦使用者的電影列表
print('推薦使用者的電影:')
print(np.nonzero(rec_list))
通過上面結果可以看出來,推薦給使用者’凜冬將至’的電影可以有’極盜者’, ‘裁縫’, ‘八惡人’, ‘實習生’。
誤差
下面看一下分解後的誤差
a = NMF(n_components=2) # 設有2個主題
W = a.fit_transform(RATE_MATRIX)
H = a.components_
print(a.reconstruction_err_)
b = NMF(n_components=3) # 設有3個主題
W = b.fit_transform(RATE_MATRIX)
H = b.components_
print(b.reconstruction_err_)
c = NMF(n_components=4) # 設有4個主題
W = c.fit_transform(RATE_MATRIX)
H = c.components_
print(c.reconstruction_err_)
d = NMF(n_components=5) # 設有5個主題
W = d.fit_transform(RATE_MATRIX)
H = d.components_
print(d.reconstruction_err_)上面的誤差分別是13.823891101850649, 10.478754611794432, 8.223787135382624, 6.120880939704367
在矩陣分解當中忍受誤差是有必要的,但是對於誤差的多少呢,筆者認為通過NMF計算出來的誤差不用太著迷,更要的是看你對於主題的設定分為多少個。很明顯的是主題越多,越接近原始的矩陣誤差越少,所以先確定好業務的需求,然後定義應該聚類的主題個數。
總結
以上雖使用NMF實現了推薦演算法,但是根據Netfix的CTO所說,NMF他們很少用來做推薦,用得更多的是SVD。對於矩陣分解的推薦演算法常用的有SVD、ALS、NMF。對於那種更好和對於文字推薦系統來說很重要的一點是搞清楚各種方法的內在含義啦。這裡推薦看一下《SVD和SVD++的區別》、《ALS推薦演算法》、《聚類和協同過濾的區別》三篇文章(後面補上)。
好啦,簡單來說一下SVD、ALS、NMF三種演算法在實際工程應用中的區別。
- 對於一些明確的資料使用SVD(例如使用者對item 的評分)
- 對於隱含的資料使用ALS(例如 purchase history購買歷史,watching habits瀏覽興趣 and browsing activity活躍記錄等)
- NMF用於聚類,對聚類的結果進行特徵提取。在上面的實踐當中就是使用了聚類的方式對不同的使用者和物品進行特徵提取,剛好特徵可以看成是推薦間的相似度,所以可以用來作為推薦演算法。但是並不推薦這樣做,因為對比起SVD來說,NMF的精確率和召回率並不顯著。
關於NMF更詳細的解釋請見我的另外一篇文章《NMF 非負矩陣分解(Non-negative Matrix Factorization)解釋》
引用
- [1] http://www.csie.ntu.edu.tw/~cjlin/nmf/ Chih-Jen Lin寫的NMF演算法和關於NMF的論文,07年發的論文,極大地提升了NMF的計算過程。
- [2] https://github.com/chenzomi12/NMF-example 本文程式碼
- [3] http://www.nature.com/nature/journal/v401/n6755/abs/401788a0.html神關於NMF1990論文
- [4]NMF非負矩陣分解–原理與應用
相關文章
- 文字主題模型之非負矩陣分解(NMF)模型矩陣
- 人工智慧-機器學習-演算法:非負矩陣分解(NMF)人工智慧機器學習演算法矩陣
- 【程式碼更新】單細胞分析實錄(21): 非負矩陣分解(NMF)的R程式碼實現,只需兩步,啥圖都有矩陣
- 矩陣分解矩陣
- 推薦系統實踐 0x0b 矩陣分解矩陣
- 【矩陣乘法】Matrix Power Series矩陣
- 非科班程式設計師才不知道的矩陣Matrix程式設計師矩陣
- Cellular Matrix 蜂窩矩陣(一)矩陣
- goldengate 認證矩陣matrixGo矩陣
- 奇異矩陣,非奇異矩陣,偽逆矩陣矩陣
- Spark Distributed matrix 分散式矩陣Spark分散式矩陣
- HDU 4920 Matrix multiplication(矩陣相乘)矩陣
- 矩陣分解--超詳細解讀矩陣
- 矩陣分解(MF)方法及程式碼矩陣
- Python Numpy的陣列array和矩陣matrixPython陣列矩陣
- [CareerCup] 1.7 Set Matrix Zeroes 矩陣賦零矩陣
- HDU 4965 Fast Matrix Calculation(矩陣快速冪)AST矩陣
- (原創)一般矩陣 Matrix類矩陣
- Oracle 連線因式分解(Join Factorization)Oracle
- SVD矩陣分解考慮時間因素矩陣
- 「Matrix Factorization Techniques for Recommender Systems」- 論文摘要
- 旋轉矩陣(Rotate Matrix)的性質分析矩陣
- ML.NET 示例:推薦之矩陣分解矩陣
- 推薦系統-矩陣分解原理詳解矩陣
- flutter佈局-5-Matrix4矩陣變換Flutter矩陣
- 分解機(Factorization Machines)推薦演算法原理Mac演算法
- 基於概率的矩陣分解原理詳解(PMF)矩陣
- 矩陣的奇異值分解(SVD)及其應用矩陣
- 動手畫混淆矩陣(Confusion Matrix)(含程式碼)矩陣
- 張量(Tensor)、標量(scalar)、向量(vector)、矩陣(matrix)矩陣
- POJ 3233 Matrix Power Series(矩陣+二分)矩陣
- 用Spark學習矩陣分解推薦演算法Spark矩陣演算法
- ML.NET 示例:推薦之One Class 矩陣分解矩陣
- 奇異矩陣與非奇異矩陣的定義與區別矩陣
- 強大的矩陣奇異值分解(SVD)及其應用矩陣
- 基於矩陣分解的協同過濾演算法矩陣演算法
- 矩陣LU分解---使用MATLAB和DEV-C++實現的程式碼過程矩陣MatlabdevC++
- AD域安全攻防實踐(附攻防矩陣圖)矩陣