概要
在大資料量高併發訪問時,經常會出現服務或介面面對暴漲的請求而不可用的情況,甚至引發連鎖反映導致整個系統崩潰。此時你需要使用的技術手段之一就是限流,當請求達到一定的併發數或速率,就進行等待、排隊、降級、拒絕服務等。
在開發高併發系統時有三把利器用來保護系統:快取、降級和限流。
快取
快取比較好理解,在大型高併發系統中,如果沒有快取資料庫將分分鐘被爆,系統也會瞬間癱瘓。使用快取不單單能夠提升系統訪問速度、提高併發訪問量,也是保護資料庫、保護系統的有效方式。大型網站一般主要是“讀”,快取的使用很容易被想到。在大型“寫”系統中,快取也常常扮演者非常重要的角色。比如累積一些資料批量寫入,記憶體裡面的快取佇列(生產消費),以及HBase寫資料的機制等等也都是通過快取提升系統的吞吐量或者實現系統的保護措施。甚至訊息中介軟體,你也可以認為是一種分散式的資料快取。
降級
服務降級是當伺服器壓力劇增的情況下,根據當前業務情況及流量對一些服務和頁面有策略的降級,以此釋放伺服器資源以保證核心任務的正常執行。降級往往會指定不同的級別,面臨不同的異常等級執行不同的處理。根據服務方式:可以拒接服務,可以延遲服務,也有時候可以隨機服務。根據服務範圍:可以砍掉某個功能,也可以砍掉某些模組。總之服務降級需要根據不同的業務需求採用不同的降級策略。主要的目的就是服務雖然有損但是總比沒有好。
限流
限流可以認為服務降級的一種,限流就是限制系統的輸入和輸出流量已達到保護系統的目的。一般來說系統的吞吐量是可以被測算的,為了保證系統的穩定執行,一旦達到的需要限制的閾值,就需要限制流量並採取一些措施以完成限制流量的目的。比如:延遲處理,拒絕處理,或者部分拒絕處理等等。
限流演算法
令牌桶(Token Bucket)、漏桶(leaky bucket)和計數器演算法是最常用的三種限流的演算法。
計數器限流演算法也是比較常用的,主要用來限制總併發數,比如資料庫連線池大小、執行緒池大小、程式訪問併發數等都是使用計數器演算法。也是最簡單粗暴的演算法。
使用計數器限流示例1:
public class CountRateLimiterDemo {
private static AtomicInteger count = new AtomicInteger(0);
public static void exec() {
if (count.get() >= 5) {
System.out.println("請求使用者過多,請稍後在試!"+System.currentTimeMillis()/1000);
} else {
count.incrementAndGet();
try {
//處理核心邏輯
TimeUnit.SECONDS.sleep(1);
System.out.println("--"+System.currentTimeMillis()/1000);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
count.decrementAndGet();
}
}
}
}
使用AomicInteger來進行統計當前正在併發執行的次數,如果超過域值就簡單粗暴的直接響應給使用者,說明系統繁忙,請稍後再試或其它跟業務相關的資訊。
弊端:使用 AomicInteger 簡單粗暴超過域值就拒絕請求,可能只是瞬時的請求量高,也會拒絕請求。
使用計數器限流示例2
public class CountRateLimiterDemo {
private static Semaphore semphore = new Semaphore(50);
public static void exec() {
if(semphore.getQueueLength()>100){
System.out.println("當前等待排隊的任務數大於100,請稍候再試...");
}
try {
semphore.acquire();
// 處理核心邏輯
TimeUnit.SECONDS.sleep(1);
System.out.println("--" + System.currentTimeMillis() / 1000);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
semphore.release();
}
}
}
使用Semaphore訊號量來控制併發執行的次數,如果超過域值訊號量,則進入阻塞佇列中排隊等待獲取訊號量進行執行。如果阻塞佇列中排隊的請求過多超出系統處理能力,則可以在拒絕請求。相對Atomic優點:如果是瞬時的高併發,可以使請求在阻塞佇列中排隊,而不是馬上拒絕請求,從而達到一個流量削峰的目的。
漏桶演算法
漏桶演算法即leaky bucket是一種非常常用的限流演算法,可以用來實現流量整形(Traffic Shaping)和流量控制(Traffic Policing)。貼了一張維基百科上示意圖幫助大家理解:
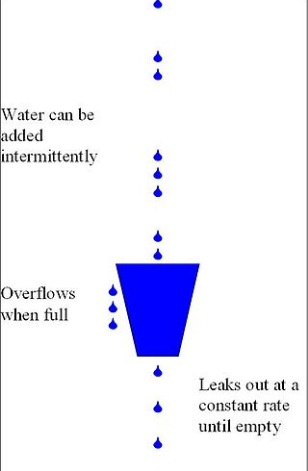
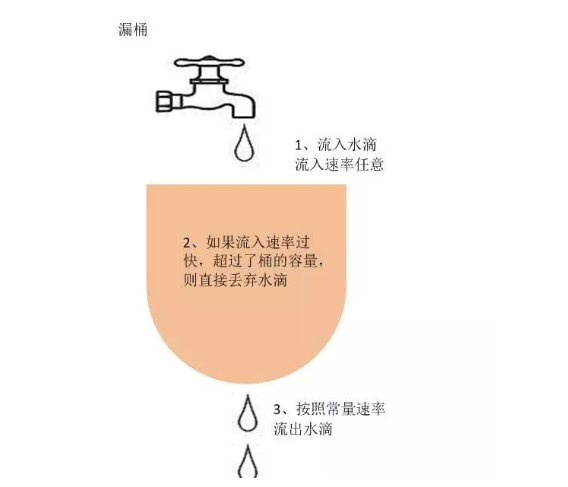
漏桶演算法的主要概念如下:
它的主要目的是控制資料注入到網路的速率,平滑網路上的突發流量,資料可以以任意速度流入到漏桶中。漏桶演算法提供了一種機制,通過它,突發流量可以被整形以便為網路提供一個穩定的流量。 漏桶可以看作是一個帶有常量服務時間的單伺服器佇列,如果漏桶為空,則不需要流出水滴,如果漏桶(包快取)溢位,那麼水滴會被溢位丟棄。
漏桶演算法比較好實現,在單機系統中可以使用佇列來實現(.Net中TPL
DataFlow可以較好的處理類似的問題,你可以在這裡找到相關的介紹),在分散式環境中訊息中介軟體或者Redis都是可選的方案。
令牌桶演算法
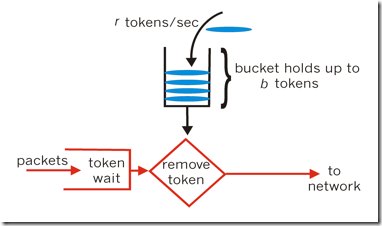
令牌桶演算法的原理是系統會以一個恆定的速度往桶裡放入令牌,而如果請求需要被處理,則需要先從桶裡獲取一個令牌,當桶裡沒有令牌可取時,則拒絕服務。 當桶滿時,新新增的令牌被丟棄或拒絕。
令牌桶演算法是一個存放固定容量令牌(token)的桶,按照固定速率往桶裡新增令牌。令牌桶演算法基本可以用下面的幾個概念來描述:
- 令牌將按照固定的速率被放入令牌桶中。比如每秒放10個。
- 桶中最多存放b個令牌,當桶滿時,新新增的令牌被丟棄或拒絕。
- 當一個n個位元組大小的資料包到達,將從桶中刪除n個令牌,接著資料包被髮送到網路上。
- 如果桶中的令牌不足n個,則不會刪除令牌,且該資料包將被限流(要麼丟棄,要麼緩衝區等待)。
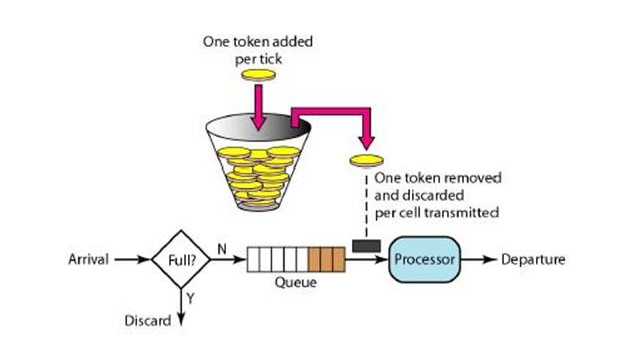
令牌演算法是根據放令牌的速率去控制輸出的速率,也就是上圖的to network的速率。to network我們可以理解為訊息的處理程式,執行某段業務或者呼叫某個RPC。
漏桶和令牌桶的比較
令牌桶可以在執行時控制和調整資料處理的速率,處理某時的突發流量。放令牌的頻率增加可以提升整體資料處理的速度,而通過每次獲取令牌的個數增加或者放慢令牌的發放速度和降低整體資料處理速度。而漏桶不行,因為它的流出速率是固定的,程式處理速度也是固定的。
整體而言,令牌桶演算法更優,但是實現更為複雜一些。