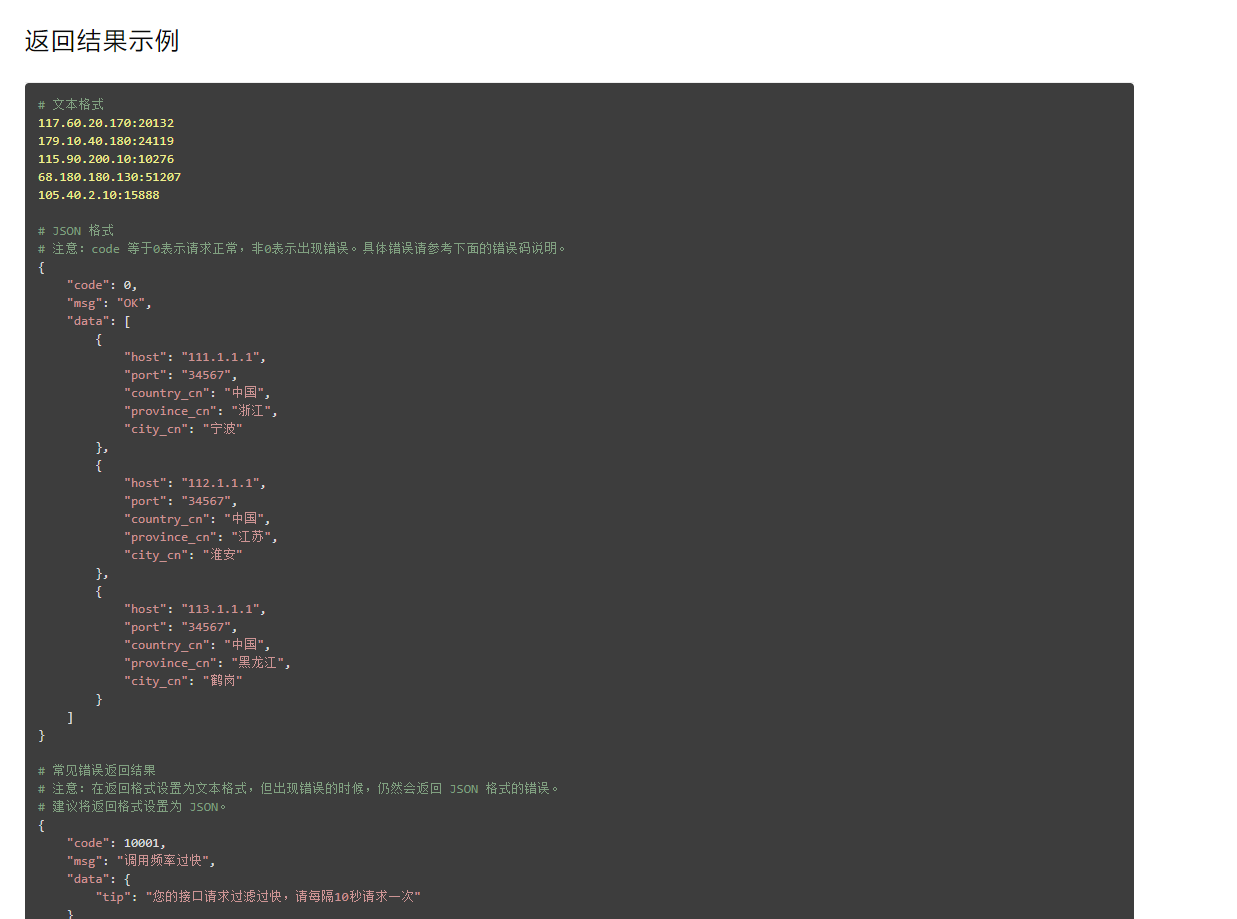
一:對返回ip格式的操作,很顯然XX代理是給出json格式的資料,可以直接請求後返回json資料進行操作包過提取,刪除,增加。當然,在實際使用ip代理的時候最好先在瀏覽器中請求一次,複製下來新建一個py檔案練習對其操作。
二:ip的有效期,現在大部分的ip代理都是有有效期的,(本文的ip處理,是一次性拿5個就扔了.所以沒有處理過期,因為我這一個ip只能用幾次就封了),當ip失效後你需要將此ip從ip池中刪除。當ip不夠的時候又要引入新的ip新增到當前的ip池中。要動態維護ip池。
三:python3使用代理ip的方式:下文會介紹,以前我的python3使用代理ip也有格式,你爬取的是http用http,是https用https就行。
四:異常處理,再寫爬蟲的時候一定要對所有可能產生異常的操作進行try except的異常處理。異常又要注意是否為超時異常,還是ip不可用,過期的異常,還是操作dom樹的時候產生的異常。不同的異常要採用不同的策略。(可用狀態碼,全域性變數判斷)。
五:注意使用資訊和要求:我買的那個蘑菇代理不能請求頻率超過5s。還有就要有新增本地ip地址。(可能是基於安全考慮)
六:分析目標網站對ip的需求。你需要設定ip池的最小和請求ip的個數不至於太大或太小,可以預先測試。打個比方你爬的網站同一個時段10個ip更換就不夠了。你不至於開100個ip去爬吧,ip過期而沒咋麼用就是對資源的浪費(當然土豪請隨意。)
自行找一個,人家會給你api. 你呼叫即可.
我這裡用的是json格式的api

程式碼
1.配置環境,匯入包
from bs4 import BeautifulSoup
import requests
import random
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36'}2.獲取網頁內容函式
def getHTMLText(url,proxies):
try:
r = requests.get(url,proxies=proxies)
r.raise_for_status()
r.encoding = r.apparent_encoding
except:
return 0
else:
return r.text3.從代理ip網站獲取代理ip列表函式,並檢測可用性,返回ip列表
def get_ip_list(url):
web_data = requests.get(url,headers)
soup = BeautifulSoup(web_data.text, 'html')
ips = soup.find_all('tr')
ip_list = []
for i in range(1, len(ips)):
ip_info = ips[i]
tds = ip_info.find_all('td')
ip_list.append(tds[1].text + ':' + tds[2].text)
#檢測ip可用性,移除不可用ip:(這裡其實總會出問題,你移除的ip可能只是暫時不能用,剩下的ip使用一次後可能之後也未必能用)
for ip in ip_list:
try:
proxy_host = "https://" + ip
proxy_temp = {"https": proxy_host}
res = urllib.urlopen(url, proxies=proxy_temp).read()
except Exception as e:
ip_list.remove(ip)
continue
return ip_list4.從ip池中隨機獲取ip列表
def get_random_ip(ip_list):
proxy_list = []
for ip in ip_list:
proxy_list.append('http://' + ip)
proxy_ip = random.choice(proxy_list)
proxies = {'http': proxy_ip}
return proxies5.呼叫代理
if __name__ == '__main__':
url = 'http://www.xicidaili.com/nn/'
ip_list = get_ip_list(url)
proxies = get_random_ip(ip_list)
print(proxies)gitee.com/bobobobbb/proxy_scraby
本作品採用《CC 協議》,轉載必須註明作者和本文連結