來源:鄧侃
昨天,2012年1月11日,網友 @fenng 寫了一篇文章,批評鐵道部火車票網上訂購系統,http://www.12306.cn [1]。同時在新浪發了一條言辭激烈的微博,“去你媽的‘海量事務高速處理系統’”,引起熱議 [2]。
春節將到,大家買不著車票,趕不上大年三十與家人團聚,急切心情可以理解。但是拍桌子開罵,只能宣洩情緒,解決不了實際問題。
開發一套訂票系統並不難,難在應對春運期間,日均 10 億級別的洪峰流量。日均 10 億級別的洪峰請求,在中國這個人口全球第一大國,不算稀罕,不僅火車票訂票系統會遇到,而且電子商務在促銷時,也會遇到,社交網站遇到新聞熱點時,也會遇到。
所以,能夠在中國成功執行的雲端計算系統,推廣到全球,一定也能成功。但是在美國成功執行的雲端計算系統,移植到中國,卻不一定成功。
如果我們能夠設計建造一套,穩定而高效的鐵路訂票系統,不僅解決了中國老百姓的實際問題,而且在全球高科技業界,也是一大亮點,而且是貼著中國標籤的前沿科技的亮點。
於是軟體工程師們獻計獻策,討論如何改進 12306 網上購票系統 [3]。其中比較有代表性的,有兩篇 [4,5]。
網友的評論中,有觀點認為,[4] 利用“虛擬排隊”的手段,將過程拉長負載降低,是網遊的設計思路。而 [5] 利用快取技術,一層層地降低系統負荷, 是網際網路的設計思路。
個人認為,[4] 和 [5] 並不是相互排斥的兩種路線,兩者著重解決的問題不同,不妨結合起來使用,取長補短。下面介紹一下我們的設計草案,追求實用,擯棄花哨。拋磚引玉,歡迎拍磚。

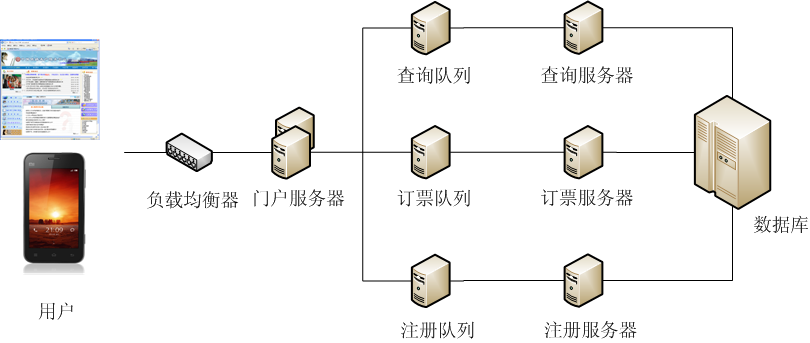
圖一。12306.cn 網站系統架構設想圖。
Courtesy http://i879.photobucket.com/albums/ab351/kan_deng/12306.png
{kind=link}
圖一是系統架構圖,典型的“展現層”/ “業務層”/ “資料層”的三段論。
使用者接入有兩類,一個是執行在電腦裡的瀏覽器,例如 IE,另一個是手機。
無論使用者用電腦瀏覽器,還是手機訪問 http://www.12306.cn 網站,使用者請求首先被網站的負載均衡器接收。負載均衡器連線著一群門戶伺服器,根據各個門戶伺服器的負載輕重,負載均衡器把使用者請求,轉發到某一相對清閒的門戶伺服器。
門戶伺服器的任務類似於收發室老頭兒,它只讀每個使用者請求的前幾個 bytes,目的是確定使用者請求的型別,然後把請求投放到相應型別的佇列中去。門戶伺服器的處理邏輯非常簡單,這樣做的好處,是讓它能夠快速處理大批量使用者請求。
根據 [5] 的分析,12306 處理的使用者請求,大致分為三類,
1. 查詢。使用者訂票前,查詢車次以及餘票。使用者下訂單後,查詢是否已經訂上票。
2. 訂票,包括確定車次和票數,然後付款。使用者付款時,需要在網銀等網站上操作。
3. 第一次訪問的使用者,需要登記,包括姓名和信用卡等資訊。
三類請求的業務處理過程,被分為兩個階段,
1. 執行於快取中的任務佇列。設定佇列的目的,是防止處理過程耗時太長,導致大量使用者請求擁塞於門戶伺服器,導致系統癱瘓。
2. 業務處理處理器,對於每一類業務,分別有一群業務伺服器。不同業務的處理流程,各不相同。

圖二。12306.cn 網站查詢和訂票業務流程設想圖。
Courtesy http://i879.photobucket.com/albums/ab351/kan_deng/12306-1.png
{kind=link}
圖二描述了查詢和訂票,兩個業務的處理流程。登記業務流程從略。
查詢的業務流程,參見圖二上半部,分五步。這裡有兩個問題需要注意,
1. 使用者發出請求後,經過短暫的等待時間,能夠迅速看到結果。平均等待時間不能超過 1 秒。
2. 影響整個查詢速度的關鍵,是“查詢伺服器”的設計。
查詢任務可以進一步細化,大致分成三種。
1. 查詢車次和時間表,這是靜態內容,很少與資料庫互動,資料量也不大,可以快取在記憶體中。
車次和時間表的資料結構,不妨採用 Key-Value 的方式,開發簡單,使用效率高。Key-Value 的具體實現有很多產品,[5] 建議使用 Redis。
這些是技術細節,不妨通過對比實驗,針對火車票訂票系統的實際流量,以及峰值波動,確定哪一個產品最合適。
2. 查詢某一班次的剩餘車票,這需要呼叫資料庫中不斷更新的資料。
[5] 建議把剩餘車票只分為兩種,“有”或“無”,這樣減少呼叫訪問資料庫的次數,降低資料庫的壓力。但是這樣做,不一定能夠滿足使用者的需求,說不定會招致網友的批評譏諷。
[4] 建議在訂票佇列中,增加測算訂票佇列長度的功能,根據訂票佇列長度以及佇列中每個請求的購票數量,可以計算出每個車次的剩餘座位。如果 12306.cn 網站只有一個後臺系統,這個辦法行之有效。
但是假如 12306.cn 網站採用分散式結構,每個鐵路分局設有子系統,分別管理各個鐵路分局轄區內的各個車次。在分散式系統下,這個辦法面臨任務轉發的麻煩。不僅開發工作量大,而且會延長查詢流程處理時間,導致使用者長久等待。
3. 已經下單的使用者,查詢是否已經成功地訂上票。
每個使用者通常只關心自己訂的票。如果把每個使用者訂購的車票的所有內容,都快取在記憶體裡,不僅非常耗用記憶體空間,記憶體空間使用效率低下,更嚴重的問題是,訪問資料庫過於頻繁,資料量大,增大資料庫的壓力。
解決上述分散式同步,以及資料庫壓力的兩個問題,不妨從訂票的流程設計和資料結構設計入手。
假如有個北京使用者在網上訂購了一套聯票,途經北京鐵路局和鄭州鐵路局轄區的兩個車次。使用者從北京上網,由北京鐵路局的子系統,處理他的請求。北京鐵路局的訂票伺服器把他的請求一分為二,北京鐵路局的車次的訂票,在北京子系統完成,鄭州鐵路局的車次在鄭州子系統完成。
每個子系統處理四種 Key-Value 資料組。
1. 使用者ID:多個 (訂單ID)s。
2. 訂單ID:多個 (訂票結果ID)s。
3. 訂票結果ID: 一個 (使用者ID,車次ID)。
4. 車次ID:一個(日期),多個 (座位,使用者ID)。
北京訂票伺服器完成訂票後,把上述四個資料組,寫入北京子系統的資料庫,同時快取進北京的查詢伺服器,參見圖二下半部第6步和第7步。
鄭州訂票伺服器完成訂票後,把上述四個資料組,寫入鄭州子系統的資料庫,同時快取進北京的查詢伺服器,而不是鄭州的伺服器。
讓訂票伺服器把訂票資料,同時寫入資料庫和查詢伺服器的快取,目的是讓資料庫永久保留訂票記錄,而讓大多數查詢,只訪問快取,降低資料庫的壓力。
北京使用者的訂票資料,只快取在北京的查詢伺服器,不跨域快取,從而降低快取空間的佔用,和同步的麻煩。這樣做,有個前提假設,查詢使用者與訂票使用者,基本上是同一個人,而且從同一個城市上網。
但是這裡有個缺陷,某使用者在北京上網訂了票。過了幾天,他在北京上網,輸入使用者ID和密碼後,就會看到他訂購的所有車票。可是又過了幾天,他去了鄭州,從鄭州上網,同樣輸入使用者ID和密碼,卻看不到他訂購的所有車票。
解決這個缺陷的辦法並不麻煩,在使用者查詢訂票資訊時,需要註明訂票地點,系統根據訂票地點,把查詢請求轉發到相應區域的子系統。
另外,每次訂票的時候,網站會給他的手機傳送簡訊,提供訂票資訊,參見圖二下半部第8步和第9步。
以上是一個初步設計,還有不少細節需要完善,例如防火牆如何佈置等等。這個設計不僅適用於單一的集中式部署,而且也適合分散式部署。
或許有讀者會問,為什麼沒有用到雲端計算?其實上述架構設計,為將來向雲端計算演變,留下了伏筆。
在上述架構設計中,我們假定每個環節需要用多少伺服器,需要多大容量的資料庫,預先都已經規劃好。但是假如事先的規劃,低於實際承受的流量和資料量,那麼系統就會崩潰。所以,事先的規劃,只能以峰值為基準設立。
但是峰值將會是多少?事先難以確定。即便能夠確定峰值,然後以峰值為基準,規劃系統的能力,那麼春運過後,就會有大量資源冗餘,造成資源浪費?
如何既能抗洪,又不造成資源浪費?解決方案是雲端計算,而且目前看來,除了雲端計算,沒有別的辦法。
Reference,
[1] 海量事務高速處理系統。
http://www.douban.com/note/
[2] 去你媽的‘海量事務高速處理系統’。
http://weibo.com/1577826897/
[3] 火車訂票系統的設想。
http://weibo.com/1570303725/
[4] 鐵路訂票系統的簡單設計。
http://blog.codingnow.com/
[5] 鐵路訂票網站個人的設計淺見。
http://hi.baidu.com/caoz/blog/