一、模組簡介
模組是實現了某個功能的程式碼集合,比如幾個.py檔案可以組成程式碼集合即模組。其中常見的模組有os模組(系統相關),file模組(檔案操作相關)
模組主要分三類:
- 自定義模組 :所謂自定義模組,即自己編寫Python檔案組成的模組。
- 第三方模組 :採用其他人編寫的模組,即第三方提供的模組
- 內建模組:python內建的模組
二、模組匯入
匯入模組的方法有好幾種方式,其中可以直接匯入,也可匯入模組的方法
import module
from module.xx.xx import xx
from module.xx.xx import xx as rename
from module.xx.xx import *
匯入模組其實就是告訴Python直譯器去解釋那個py檔案
- 匯入一個py檔案,直譯器解釋該py檔案
- 匯入一個包,直譯器解釋該包下的 __init__.py 檔案 【py2.7】
注意:
匯入模組時候,預設讀取的路徑為sys.path,可以通過下面的方法檢視當前系統預設路徑:
import sys print sys.path
輸出結果如下:
['', '/usr/lib64/python2.7/site-packages/MySQL_python-1.2.5-py2.7-linux-x86_64.egg', '/usr/lib/python2.7/site-packages/setuptools-19.4-py2.7.egg', '/usr/lib/python2.7/site-packages/Django-1.8.8-py2.7.egg', '/usr/lib/python2.7/site-packages/django_pagination-1.0.7-py2.7.egg', '/usr/lib64/python27.zip', '/usr/lib64/python2.7', '/usr/lib64/python2.7/plat-linux2', '/usr/lib64/python2.7/lib-tk', '/usr/lib64/python2.7/lib-old', '/usr/lib64/python2.7/lib-dynload', '/usr/lib64/python2.7/site-packages', '/usr/lib/python2.7/site-packages']
匯入模組時候,如果其不再預設路徑裡,則可以通過以下方法將其加入預設路徑
import sys import os project_path = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) sys.path.append(project_path)
三、常用內建模組
內建模組是Python自帶的功能,在使用時,需要先匯入再使用
1、sys模組
用於提供python直譯器相關操作
import sys
sys.argv 命令列引數List,第一個元素是程式本身路徑
sys.exit(n) 退出程式,正常退出時exit(0)
sys.version 獲取Python解釋程式的版本資訊
sys.maxint 最大的Int值
sys.path 返回模組的搜尋路徑,初始化時使用PYTHONPATH環境變數的值
sys.platform 返回作業系統平臺名稱
sys.stdin 輸入相關
sys.stdout 輸出相關
sys.stderror 錯誤相關
2、os模組
提供系統級別的操作
os.getcwd() 獲取當前工作目錄,即當前python指令碼工作的目錄路徑 os.chdir("dirname") 改變當前指令碼工作目錄;相當於shell下cd os.curdir 返回當前目錄: ('.') os.pardir 獲取當前目錄的父目錄字串名:('..') os.makedirs('dir1/dir2') 可生成多層遞迴目錄 os.removedirs('dirname1') 若目錄為空,則刪除,並遞迴到上一級目錄,如若也為空,則刪除,依此類推 os.mkdir('dirname') 生成單級目錄;相當於shell中mkdir dirname os.rmdir('dirname') 刪除單級空目錄,若目錄不為空則無法刪除,報錯;相當於shell中rmdir dirname os.listdir('dirname') 列出指定目錄下的所有檔案和子目錄,包括隱藏檔案,並以列表方式列印 os.remove() 刪除一個檔案 os.rename("oldname","new") 重新命名檔案/目錄 os.stat('path/filename') 獲取檔案/目錄資訊 os.sep 作業系統特定的路徑分隔符,win下為"\\",Linux下為"/" os.linesep 當前平臺使用的行終止符,win下為"\t\n",Linux下為"\n" os.pathsep 用於分割檔案路徑的字串 os.name 字串指示當前使用平臺。win->'nt'; Linux->'posix' os.system("bash command") 執行shell命令,直接顯示 os.environ 獲取系統環境變數 os.path.abspath(path) 返回path規範化的絕對路徑 os.path.split(path) 將path分割成目錄和檔名二元組返回 os.path.dirname(path) 返回path的目錄。其實就是os.path.split(path)的第一個元素 os.path.basename(path) 返回path最後的檔名。如何path以/或\結尾,那麼就會返回空值。即os.path.split(path)的第二個元素 os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False os.path.isabs(path) 如果path是絕對路徑,返回True os.path.isfile(path) 如果path是一個存在的檔案,返回True。否則返回False os.path.isdir(path) 如果path是一個存在的目錄,則返回True。否則返回False os.path.join(path1[, path2[, ...]]) 將多個路徑組合後返回,第一個絕對路徑之前的引數將被忽略 os.path.getatime(path) 返回path所指向的檔案或者目錄的最後存取時間 os.path.getmtime(path) 返回path所指向的檔案或者目錄的最後修改時間
3、hashlib模組
用於加密相關的操作,代替了md5模組和sha模組,主要提供SHA1,SHA224,SHA256,SHA384,SHA512,MD5演算法
import hashlib # ######## md5 ######## hash = hashlib.md5() # help(hash.update) hash.update(bytes('admin', encoding='utf-8')) print(hash.hexdigest()) print(hash.digest()) ######## sha1 ######## hash = hashlib.sha1() hash.update(bytes('admin', encoding='utf-8')) print(hash.hexdigest()) # ######## sha256 ######## hash = hashlib.sha256() hash.update(bytes('admin', encoding='utf-8')) print(hash.hexdigest()) # ######## sha384 ######## hash = hashlib.sha384() hash.update(bytes('admin', encoding='utf-8')) print(hash.hexdigest()) # ######## sha512 ######## hash = hashlib.sha512() hash.update(bytes('admin', encoding='utf-8')) print(hash.hexdigest())
hashlib直接加密可能會被裝庫破解密碼,所以這裡我們可以通過在加密演算法中自定義key做加密,具體示例如下:
import hashlib # ######## md5 ######## hash = hashlib.md5(bytes('898oaFs09f',encoding="utf-8")) hash.update(bytes('admin',encoding="utf-8")) print(hash.hexdigest())
Python內建模組hmac可以對我們建立key和內容進行進一步的處理,然後加密
import hmac h = hmac.new(bytes('898oaFs09f',encoding="utf-8")) h.update(bytes('admin',encoding="utf-8")) print(h.hexdigest())
4、random模組
用於產生隨機數的模組
import random
random.random() ##隨機取(0-1)之間的數值 0.9151227988883402 random.randint(1,3) ##隨機取[m-n]之間的整數 3 random.randrange(1,5) ##隨機取[m-n)之間的整數 1 random.choice('chinese') ##隨機取一個字元或列表數值 's' random.choice([1,5,'abc']) 1 random.sample('hello',2) ##從字串中隨機取出N個字元 ['h', 'l'] random.uniform(3,10) ##從區間(m,n)中取浮點數 7.797497264321265 l=[1,2,3,4,5] ##讓有序列表變無序 random.shuffle(l) l [2, 4, 1, 5, 3]
編寫由數字和字母組成的4位驗證碼程式:(##大寫字母ascii:65-90,小寫字母:97-122)
#!/usr/bin/env python # -*- UTF-8 -*- # Author:Rangle ##大寫字母ascii:65-90,小寫字母:97-122 import random check_code='' for i in range(4): num=random.randint(0,3) if num==i: num1=random.randint(0,3) if num==num1: code = chr(random.randint(65, 90)) else: code = chr(random.randint(97,122)) else: code=random.randint(1,9) check_code+=str(code) print(check_code)
5、re模組
re提供正規表示式相關操作
字元:
. 匹配除換行符以外的任意字元
\w 匹配字母或數字或下劃線或漢字
\s 匹配任意的空白符
\d 匹配數字
\b 匹配單詞的開始或結束
^ 匹配字串的開始
$ 匹配字串的結束
次數:
* 重複零次或更多次
+ 重複一次或更多次
? 重複零次或一次
{n} 重複n次
{n,} 重複n次或更多次
{n,m} 重複n到m次
match:
match,從起始位置開始匹配,匹配成功返回一個物件,未匹配成功返回None
match(pattern, string, flags=0)


# match,從起始位置開始匹配,匹配成功返回一個物件,未匹配成功返回None match(pattern, string, flags=0) # pattern: 正則模型 # string : 要匹配的字串 # falgs : 匹配模式 X VERBOSE Ignore whitespace and comments for nicer looking RE's. I IGNORECASE Perform case-insensitive matching. M MULTILINE "^" matches the beginning of lines (after a newline) as well as the string. "$" matches the end of lines (before a newline) as well as the end of the string. S DOTALL "." matches any character at all, including the newline. A ASCII For string patterns, make \w, \W, \b, \B, \d, \D match the corresponding ASCII character categories (rather than the whole Unicode categories, which is the default). For bytes patterns, this flag is the only available behaviour and needn't be specified. L LOCALE Make \w, \W, \b, \B, dependent on the current locale. U UNICODE For compatibility only. Ignored for string patterns (it is the default), and forbidden for bytes patterns.
# 無分組 r = re.match("h\w+", origin) print(r.group()) # 獲取匹配到的所有結果 print(r.groups()) # 獲取模型中匹配到的分組結果 print(r.groupdict()) # 獲取模型中匹配到的分組結果 # 有分組 # 為何要有分組?提取匹配成功的指定內容(先匹配成功全部正則,再匹配成功的區域性內容提取出來) r = re.match("h(\w+).*(?P<name>\d)$", origin) print(r.group()) # 獲取匹配到的所有結果 print(r.groups()) # 獲取模型中匹配到的分組結果 print(r.groupdict()) # 獲取模型中匹配到的分組中所有執行了key的組 Demo
search:
search,瀏覽整個字串去匹配第一個,未匹配成功返回None
search(pattern, string, flags=0)
# 無分組 r = re.search("a\w+", origin) print(r.group()) # 獲取匹配到的所有結果 print(r.groups()) # 獲取模型中匹配到的分組結果 print(r.groupdict()) # 獲取模型中匹配到的分組結果 # 有分組 r = re.search("a(\w+).*(?P<name>\d)$", origin) print(r.group()) # 獲取匹配到的所有結果 print(r.groups()) # 獲取模型中匹配到的分組結果 print(r.groupdict()) # 獲取模型中匹配到的分組中所有執行了key的組 demo
findall:
findall,獲取非重複的匹配列表;如果有一個組則以列表形式返回,且每一個匹配均是字串;如果模型中有多個組,則以列表形式返回,且每一個匹配均是元祖;
空的匹配也會包含在結果中
findall(pattern, string, flags=0)
# 無分組 r = re.findall("a\w+",origin) print(r) # 有分組 origin = "hello alex bcd abcd lge acd 19" r = re.findall("a((\w*)c)(d)", origin) print(r) Demo
sub:
替換匹配成功的指定位置字串
sub(pattern, repl, string, count=0, flags=0)
pattern: 正則模型
repl : 要替換的字串或可執行物件
string : 要匹配的字串
count : 指定匹配個數
flags : 匹配模式
# 與分組無關 origin = "hello alex bcd alex lge alex acd 19" r = re.sub("a\w+", "999", origin, 2) print(r)
split:
split,根據正則匹配分割字串
split(pattern, string, maxsplit=0, flags=0)
pattern: 正則模型
string : 要匹配的字串
maxsplit:指定分割個數
flags : 匹配模式
# 無分組 origin = "hello alex bcd alex lge alex acd 19" r = re.split("alex", origin, 1) print(r) # 有分組 origin = "hello alex bcd alex lge alex acd 19" r1 = re.split("(alex)", origin, 1) print(r1) r2 = re.split("(al(ex))", origin, 1) print(r2) Demo
常用正則匹配:
IP: ^(25[0-5]|2[0-4]\d|[0-1]?\d?\d)(\.(25[0-5]|2[0-4]\d|[0-1]?\d?\d)){3}$ 手機號: ^1[3|4|5|8][0-9]\d{8}$ 郵箱: [a-zA-Z0-9_-]+@[a-zA-Z0-9_-]+(\.[a-zA-Z0-9_-]+)+
6、序列化模組
Python中用於序列化的兩個模組
- json 用於【字串】和 【python基本資料型別】 間進行轉換
- pickle 用於【python特有的型別】 和 【python基本資料型別】間進行轉換
Json模組提供了四個功能:dumps、dump、loads、load
pickle模組提供了四個功能:dumps、dump、loads、load
#!/usr/bin/env python # -*- UTF-8 -*- # Author:Rangle import json import pickle data={'k1':123,'k2':'lucy'} p_str=pickle.dumps(data) ##將資料通過特殊形式轉化為只有Python語言認識的字串 print(p_str) with open('F:\\python_project\\Day03\\test.txt','wb+') as fp: p_str=pickle.dump(data,fp) ##將資料通過特殊形式轉化為只有Python語言認識的字串,並寫入檔案 j_str=json.dumps(data) ##將資料通過特殊形式轉為所有程式都認識的字串 print(j_str) with open('F:\\python_project\\Day03\\test1.txt','w+') as fp: j_str=json.dump(data,fp) ##將資料通過特殊形式轉化為所有程式認識的字串,並寫入檔案
7、configparser模組
configparser用於處理特定格式的檔案,其本質上是利用open來操作檔案。
檔名為xxx000的內容如下:
# 註釋1 ; 註釋2 [section1] # 節點 k1 = v1 # 值 k2:v2 # 值 [section2] # 節點 k1 = v1 # 值 指定格式
具體操作示例如下:
(1)獲取檔案中所有節點 import configparser config = configparser.ConfigParser() config.read('xxxooo', encoding='utf-8') ret = config.sections() print(ret) (2)獲取指定節點的所有鍵值對 import configparser config = configparser.ConfigParser() config.read('xxxooo', encoding='utf-8') ret = config.items('section1') print(ret) (3)獲取指定節點的所有的鍵 import configparser config = configparser.ConfigParser() config.read('xxxooo', encoding='utf-8') ret = config.options('section1') print(ret) (4)獲取指定節點下指定key的值 import configparser config = configparser.ConfigParser() config.read('xxxooo', encoding='utf-8') v = config.get('section1', 'k1') # v = config.getint('section1', 'k1') # v = config.getfloat('section1', 'k1') # v = config.getboolean('section1', 'k1') print(v) (5)檢查、刪除、新增節點 import configparser config = configparser.ConfigParser() config.read('xxxooo', encoding='utf-8') # 檢查 has_sec = config.has_section('section1') print(has_sec) # 新增節點 config.add_section("SEC_1") config.write(open('xxxooo', 'w')) # 刪除節點 config.remove_section("SEC_1") config.write(open('xxxooo', 'w')) (6)檢查、刪除、設定指定組內的鍵值對 import configparser config = configparser.ConfigParser() config.read('xxxooo', encoding='utf-8') # 檢查 has_opt = config.has_option('section1', 'k1') print(has_opt) # 刪除 config.remove_option('section1', 'k1') config.write(open('xxxooo', 'w')) # 設定 config.set('section1', 'k10', "123") config.write(open('xxxooo', 'w'))
8、xml模組
XML是實現不同語言或程式之間進行資料交換的協議,XML檔案格式如下:
<data> <country name="Liechtenstein"> <rank updated="yes">2</rank> <year>2023</year> <gdppc>141100</gdppc> <neighbor direction="E" name="Austria" /> <neighbor direction="W" name="Switzerland" /> </country> <country name="Singapore"> <rank updated="yes">5</rank> <year>2026</year> <gdppc>59900</gdppc> <neighbor direction="N" name="Malaysia" /> </country> <country name="Panama"> <rank updated="yes">69</rank> <year>2026</year> <gdppc>13600</gdppc> <neighbor direction="W" name="Costa Rica" /> <neighbor direction="E" name="Colombia" /> </country> </data>
(1)解析xml
#!/usr/bin/env python
# -*- UTF-8 -*-
# Author:Rangle
from xml.etree import ElementTree as ET
# 開啟檔案,讀取XML內容
str_xml = open('xo.xml', 'r').read()
# 將字串解析成xml特殊物件,root代指xml檔案的根節點
root = ET.XML(str_xml)
print(str_xml)
#利用ElementTree.XML將字串解析成xml物件
#!/usr/bin/env python
# -*- UTF-8 -*-
# Author:Rangle
from xml.etree import ElementTree as ET
# 直接解析xml檔案
tree = ET.parse("xo.xml")
# 獲取xml檔案的根節點
root = tree.getroot()
#利用ElementTree.parse將檔案直接解析成xml物件
(2)操作xml
XML格式型別是節點巢狀節點,對於每一個節點均有以下功能,以便對當前節點進行操作:
class Element: """An XML element. This class is the reference implementation of the Element interface. An element's length is its number of subelements. That means if you want to check if an element is truly empty, you should check BOTH its length AND its text attribute. The element tag, attribute names, and attribute values can be either bytes or strings. *tag* is the element name. *attrib* is an optional dictionary containing element attributes. *extra* are additional element attributes given as keyword arguments. Example form: <tag attrib>text<child/>...</tag>tail """ 當前節點的標籤名 tag = None """The element's name.""" 當前節點的屬性 attrib = None """Dictionary of the element's attributes.""" 當前節點的內容 text = None """ Text before first subelement. This is either a string or the value None. Note that if there is no text, this attribute may be either None or the empty string, depending on the parser. """ tail = None """ Text after this element's end tag, but before the next sibling element's start tag. This is either a string or the value None. Note that if there was no text, this attribute may be either None or an empty string, depending on the parser. """ def __init__(self, tag, attrib={}, **extra): if not isinstance(attrib, dict): raise TypeError("attrib must be dict, not %s" % ( attrib.__class__.__name__,)) attrib = attrib.copy() attrib.update(extra) self.tag = tag self.attrib = attrib self._children = [] def __repr__(self): return "<%s %r at %#x>" % (self.__class__.__name__, self.tag, id(self)) def makeelement(self, tag, attrib): 建立一個新節點 """Create a new element with the same type. *tag* is a string containing the element name. *attrib* is a dictionary containing the element attributes. Do not call this method, use the SubElement factory function instead. """ return self.__class__(tag, attrib) def copy(self): """Return copy of current element. This creates a shallow copy. Subelements will be shared with the original tree. """ elem = self.makeelement(self.tag, self.attrib) elem.text = self.text elem.tail = self.tail elem[:] = self return elem def __len__(self): return len(self._children) def __bool__(self): warnings.warn( "The behavior of this method will change in future versions. " "Use specific 'len(elem)' or 'elem is not None' test instead.", FutureWarning, stacklevel=2 ) return len(self._children) != 0 # emulate old behaviour, for now def __getitem__(self, index): return self._children[index] def __setitem__(self, index, element): # if isinstance(index, slice): # for elt in element: # assert iselement(elt) # else: # assert iselement(element) self._children[index] = element def __delitem__(self, index): del self._children[index] def append(self, subelement): 為當前節點追加一個子節點 """Add *subelement* to the end of this element. The new element will appear in document order after the last existing subelement (or directly after the text, if it's the first subelement), but before the end tag for this element. """ self._assert_is_element(subelement) self._children.append(subelement) def extend(self, elements): 為當前節點擴充套件 n 個子節點 """Append subelements from a sequence. *elements* is a sequence with zero or more elements. """ for element in elements: self._assert_is_element(element) self._children.extend(elements) def insert(self, index, subelement): 在當前節點的子節點中插入某個節點,即:為當前節點建立子節點,然後插入指定位置 """Insert *subelement* at position *index*.""" self._assert_is_element(subelement) self._children.insert(index, subelement) def _assert_is_element(self, e): # Need to refer to the actual Python implementation, not the # shadowing C implementation. if not isinstance(e, _Element_Py): raise TypeError('expected an Element, not %s' % type(e).__name__) def remove(self, subelement): 在當前節點在子節點中刪除某個節點 """Remove matching subelement. Unlike the find methods, this method compares elements based on identity, NOT ON tag value or contents. To remove subelements by other means, the easiest way is to use a list comprehension to select what elements to keep, and then use slice assignment to update the parent element. ValueError is raised if a matching element could not be found. """ # assert iselement(element) self._children.remove(subelement) def getchildren(self): 獲取所有的子節點(廢棄) """(Deprecated) Return all subelements. Elements are returned in document order. """ warnings.warn( "This method will be removed in future versions. " "Use 'list(elem)' or iteration over elem instead.", DeprecationWarning, stacklevel=2 ) return self._children def find(self, path, namespaces=None): 獲取第一個尋找到的子節點 """Find first matching element by tag name or path. *path* is a string having either an element tag or an XPath, *namespaces* is an optional mapping from namespace prefix to full name. Return the first matching element, or None if no element was found. """ return ElementPath.find(self, path, namespaces) def findtext(self, path, default=None, namespaces=None): 獲取第一個尋找到的子節點的內容 """Find text for first matching element by tag name or path. *path* is a string having either an element tag or an XPath, *default* is the value to return if the element was not found, *namespaces* is an optional mapping from namespace prefix to full name. Return text content of first matching element, or default value if none was found. Note that if an element is found having no text content, the empty string is returned. """ return ElementPath.findtext(self, path, default, namespaces) def findall(self, path, namespaces=None): 獲取所有的子節點 """Find all matching subelements by tag name or path. *path* is a string having either an element tag or an XPath, *namespaces* is an optional mapping from namespace prefix to full name. Returns list containing all matching elements in document order. """ return ElementPath.findall(self, path, namespaces) def iterfind(self, path, namespaces=None): 獲取所有指定的節點,並建立一個迭代器(可以被for迴圈) """Find all matching subelements by tag name or path. *path* is a string having either an element tag or an XPath, *namespaces* is an optional mapping from namespace prefix to full name. Return an iterable yielding all matching elements in document order. """ return ElementPath.iterfind(self, path, namespaces) def clear(self): 清空節點 """Reset element. This function removes all subelements, clears all attributes, and sets the text and tail attributes to None. """ self.attrib.clear() self._children = [] self.text = self.tail = None def get(self, key, default=None): 獲取當前節點的屬性值 """Get element attribute. Equivalent to attrib.get, but some implementations may handle this a bit more efficiently. *key* is what attribute to look for, and *default* is what to return if the attribute was not found. Returns a string containing the attribute value, or the default if attribute was not found. """ return self.attrib.get(key, default) def set(self, key, value): 為當前節點設定屬性值 """Set element attribute. Equivalent to attrib[key] = value, but some implementations may handle this a bit more efficiently. *key* is what attribute to set, and *value* is the attribute value to set it to. """ self.attrib[key] = value def keys(self): 獲取當前節點的所有屬性的 key """Get list of attribute names. Names are returned in an arbitrary order, just like an ordinary Python dict. Equivalent to attrib.keys() """ return self.attrib.keys() def items(self): 獲取當前節點的所有屬性值,每個屬性都是一個鍵值對 """Get element attributes as a sequence. The attributes are returned in arbitrary order. Equivalent to attrib.items(). Return a list of (name, value) tuples. """ return self.attrib.items() def iter(self, tag=None): 在當前節點的子孫中根據節點名稱尋找所有指定的節點,並返回一個迭代器(可以被for迴圈)。 """Create tree iterator. The iterator loops over the element and all subelements in document order, returning all elements with a matching tag. If the tree structure is modified during iteration, new or removed elements may or may not be included. To get a stable set, use the list() function on the iterator, and loop over the resulting list. *tag* is what tags to look for (default is to return all elements) Return an iterator containing all the matching elements. """ if tag == "*": tag = None if tag is None or self.tag == tag: yield self for e in self._children: yield from e.iter(tag) # compatibility def getiterator(self, tag=None): # Change for a DeprecationWarning in 1.4 warnings.warn( "This method will be removed in future versions. " "Use 'elem.iter()' or 'list(elem.iter())' instead.", PendingDeprecationWarning, stacklevel=2 ) return list(self.iter(tag)) def itertext(self): 在當前節點的子孫中根據節點名稱尋找所有指定的節點的內容,並返回一個迭代器(可以被for迴圈)。 """Create text iterator. The iterator loops over the element and all subelements in document order, returning all inner text. """ tag = self.tag if not isinstance(tag, str) and tag is not None: return if self.text: yield self.text for e in self: yield from e.itertext() if e.tail: yield e.tail 節點功能一覽表
由於 每個節點 都具有以上的方法,並且在上一步驟中解析時均得到了root(xml檔案的根節點),so 可以利用以上方法進行操作xml檔案。
a.遍歷xml文件所有內容
#!/usr/bin/env python
# -*- UTF-8 -*-
# Author:Rangle
from xml.etree import ElementTree as ET
############ 解析方式一 ############
"""
# 開啟檔案,讀取XML內容
str_xml = open('xo.xml', 'r').read()
# 將字串解析成xml特殊物件,root代指xml檔案的根節點
root = ET.XML(str_xml)
"""
############ 解析方式二 ############
# 直接解析xml檔案
tree = ET.parse("xo.xml")
# 獲取xml檔案的根節點
root = tree.getroot()
### 操作
# 頂層標籤
print(root.tag)
# 遍歷XML文件的第二層
for child in root:
# 第二層節點的標籤名稱和標籤屬性
print(child.tag, child.attrib)
# 遍歷XML文件的第三層
for i in child:
# 第二層節點的標籤名稱和內容
print(i.tag,i.text)
b.遍歷xml中指定的節點
from xml.etree import ElementTree as ET
############ 解析方式一 ############
"""
# 開啟檔案,讀取XML內容
str_xml = open('xo.xml', 'r').read()
# 將字串解析成xml特殊物件,root代指xml檔案的根節點
root = ET.XML(str_xml)
"""
############ 解析方式二 ############
# 直接解析xml檔案
tree = ET.parse("xo.xml")
# 獲取xml檔案的根節點
root = tree.getroot()
### 操作
# 頂層標籤
print(root.tag)
# 遍歷XML中所有的year節點
for node in root.iter('year'):
# 節點的標籤名稱和內容
print(node.tag, node.text)
c.修改節點內容
由於修改的節點時,均是在記憶體中進行,其不會影響檔案中的內容。所以,如果想要修改,則需要重新將記憶體中的內容寫到檔案。
解析字串方式修改、儲存
from xml.etree import ElementTree as ET ############ 解析方式一 ############ # 開啟檔案,讀取XML內容 str_xml = open('xo.xml', 'r').read() # 將字串解析成xml特殊物件,root代指xml檔案的根節點 root = ET.XML(str_xml) ############ 操作 ############ # 頂層標籤 print(root.tag) # 迴圈所有的year節點 for node in root.iter('year'): # 將year節點中的內容自增一 new_year = int(node.text) + 1 node.text = str(new_year) # 設定屬性 node.set('name', 'alex') node.set('age', '18') # 刪除屬性 del node.attrib['name'] ############ 儲存檔案 ############ tree = ET.ElementTree(root) tree.write("newnew.xml", encoding='utf-8') 解析字串方式,修改,儲存
from xml.etree import ElementTree as ET
############ 解析方式二 ############
# 直接解析xml檔案
tree = ET.parse("xo.xml")
# 獲取xml檔案的根節點
root = tree.getroot()
############ 操作 ############
# 頂層標籤
print(root.tag)
# 迴圈所有的year節點
for node in root.iter('year'):
# 將year節點中的內容自增一
new_year = int(node.text) + 1
node.text = str(new_year)
# 設定屬性
node.set('name', 'alex')
node.set('age', '18')
# 刪除屬性
del node.attrib['name']
############ 儲存檔案 ############
tree.write("newnew.xml", encoding='utf-8')
解析檔案方式,修改,儲存
d.刪除節點內容
解析字串方式刪除、儲存
from xml.etree import ElementTree as ET
############ 解析字串方式開啟 ############
# 開啟檔案,讀取XML內容
str_xml = open('xo.xml', 'r').read()
# 將字串解析成xml特殊物件,root代指xml檔案的根節點
root = ET.XML(str_xml)
############ 操作 ############
# 頂層標籤
print(root.tag)
# 遍歷data下的所有country節點
for country in root.findall('country'):
# 獲取每一個country節點下rank節點的內容
rank = int(country.find('rank').text)
if rank > 50:
# 刪除指定country節點
root.remove(country)
############ 儲存檔案 ############
tree = ET.ElementTree(root)
tree.write("newnew.xml", encoding='utf-8')
解析字串方式開啟,刪除,儲存
from xml.etree import ElementTree as ET
############ 解析檔案方式 ############
# 直接解析xml檔案
tree = ET.parse("xo.xml")
# 獲取xml檔案的根節點
root = tree.getroot()
############ 操作 ############
# 頂層標籤
print(root.tag)
# 遍歷data下的所有country節點
for country in root.findall('country'):
# 獲取每一個country節點下rank節點的內容
rank = int(country.find('rank').text)
if rank > 50:
# 刪除指定country節點
root.remove(country)
############ 儲存檔案 ############
tree.write("newnew.xml", encoding='utf-8')
解析檔案方式開啟,刪除,儲存
(3)建立xml文件
from xml.etree import ElementTree as ET # 建立根節點 root = ET.Element("famliy") # 建立節點大兒子 son1 = ET.Element('son', {'name': '兒1'}) # 建立小兒子 son2 = ET.Element('son', {"name": '兒2'}) # 在大兒子中建立兩個孫子 grandson1 = ET.Element('grandson', {'name': '兒11'}) grandson2 = ET.Element('grandson', {'name': '兒12'}) son1.append(grandson1) son1.append(grandson2) # 把兒子新增到根節點中 root.append(son1) root.append(son1) tree = ET.ElementTree(root) tree.write('oooo.xml',encoding='utf-8', short_empty_elements=False) 建立方式(一)
from xml.etree import ElementTree as ET # 建立根節點 root = ET.Element("famliy") # 建立大兒子 # son1 = ET.Element('son', {'name': '兒1'}) son1 = root.makeelement('son', {'name': '兒1'}) # 建立小兒子 # son2 = ET.Element('son', {"name": '兒2'}) son2 = root.makeelement('son', {"name": '兒2'}) # 在大兒子中建立兩個孫子 # grandson1 = ET.Element('grandson', {'name': '兒11'}) grandson1 = son1.makeelement('grandson', {'name': '兒11'}) # grandson2 = ET.Element('grandson', {'name': '兒12'}) grandson2 = son1.makeelement('grandson', {'name': '兒12'}) son1.append(grandson1) son1.append(grandson2) # 把兒子新增到根節點中 root.append(son1) root.append(son1) tree = ET.ElementTree(root) tree.write('oooo.xml',encoding='utf-8', short_empty_elements=False) 建立方式(二)
from xml.etree import ElementTree as ET # 建立根節點 root = ET.Element("famliy") # 建立節點大兒子 son1 = ET.SubElement(root, "son", attrib={'name': '兒1'}) # 建立小兒子 son2 = ET.SubElement(root, "son", attrib={"name": "兒2"}) # 在大兒子中建立一個孫子 grandson1 = ET.SubElement(son1, "age", attrib={'name': '兒11'}) grandson1.text = '孫子' et = ET.ElementTree(root) #生成文件物件 et.write("test.xml", encoding="utf-8", xml_declaration=True, short_empty_elements=False) 建立方式(三)
以原生方式儲存XML時預設無縮排,如果要設定縮排,需更改儲存方式,具體如下:
from xml.etree import ElementTree as ET from xml.dom import minidom def prettify(elem): """將節點轉換成字串,並新增縮排。 """ rough_string = ET.tostring(elem, 'utf-8') reparsed = minidom.parseString(rough_string) return reparsed.toprettyxml(indent="\t") # 建立根節點 root = ET.Element("famliy") # 建立大兒子 # son1 = ET.Element('son', {'name': '兒1'}) son1 = root.makeelement('son', {'name': '兒1'}) # 建立小兒子 # son2 = ET.Element('son', {"name": '兒2'}) son2 = root.makeelement('son', {"name": '兒2'}) # 在大兒子中建立兩個孫子 # grandson1 = ET.Element('grandson', {'name': '兒11'}) grandson1 = son1.makeelement('grandson', {'name': '兒11'}) # grandson2 = ET.Element('grandson', {'name': '兒12'}) grandson2 = son1.makeelement('grandson', {'name': '兒12'}) son1.append(grandson1) son1.append(grandson2) # 把兒子新增到根節點中 root.append(son1) root.append(son1) raw_str = prettify(root) f = open("xxxoo.xml",'w',encoding='utf-8') f.write(raw_str) f.close()
(4)名稱空間
參考:http://www.w3school.com.cn/xml/xml_namespaces.asp
from xml.etree import ElementTree as ET ET.register_namespace('com',"http://www.company.com") #some name # build a tree structure root = ET.Element("{http://www.company.com}STUFF") body = ET.SubElement(root, "{http://www.company.com}MORE_STUFF", attrib={"{http://www.company.com}hhh": "123"}) body.text = "STUFF EVERYWHERE!" # wrap it in an ElementTree instance, and save as XML tree = ET.ElementTree(root) tree.write("page.xml", xml_declaration=True, encoding='utf-8', method="xml") 名稱空間
9、requests模組
Python標準庫中提供了:urllib等模組以供Http請求,但是,它的 API 太渣了。它是為另一個時代、另一個網際網路所建立的。它需要巨量的工作,甚至包括各種方法覆蓋,來完成最簡單的任務。
傳送get請求
傳送帶header的get請求
Requests 是使用 Apache2 Licensed 許可證的 基於Python開發的HTTP 庫,其在Python內建模組的基礎上進行了高度的封裝,從而使得Pythoner進行網路請求時,變得美好了許多,使用Requests可以輕而易舉的完成瀏覽器可有的任何操作。
使用requests模組獲取http請求,需要安裝requests模組,pip3 install requests
# 1、無引數例項 import requests ret = requests.get('https://github.com/timeline.json') print(ret.url) print(ret.text) # 2、有引數例項 import requests payload = {'key1': 'value1', 'key2': 'value2'} ret = requests.get("http://httpbin.org/get", params=payload) print(ret.url) print(ret.text) GET請求
# 1、基本POST例項 import requests payload = {'key1': 'value1', 'key2': 'value2'} ret = requests.post("http://httpbin.org/post", data=payload) print(ret.text) # 2、傳送請求頭和資料例項 import requests import json url = 'https://api.github.com/some/endpoint' payload = {'some': 'data'} headers = {'content-type': 'application/json'} ret = requests.post(url, data=json.dumps(payload), headers=headers) print(ret.text) print(ret.cookies) POST請求
requests.get(url, params=None, **kwargs) requests.post(url, data=None, json=None, **kwargs) requests.put(url, data=None, **kwargs) requests.head(url, **kwargs) requests.delete(url, **kwargs) requests.patch(url, data=None, **kwargs) requests.options(url, **kwargs) # 以上方法均是在此方法的基礎上構建 requests.request(method, url, **kwargs) 其他請求
Http請求和XML例項
例項1:
import urllib import requests from xml.etree import ElementTree as ET # 使用內建模組urllib傳送HTTP請求,或者XML格式內容 """ f = urllib.request.urlopen('http://www.webxml.com.cn//webservices/qqOnlineWebService.asmx/qqCheckOnline?qqCode=424662508') result = f.read().decode('utf-8') """ # 使用第三方模組requests傳送HTTP請求,或者XML格式內容 r = requests.get('http://www.webxml.com.cn//webservices/qqOnlineWebService.asmx/qqCheckOnline?qqCode=424662508') result = r.text # 解析XML格式內容 node = ET.XML(result) # 獲取內容 if node.text == "Y": print("線上") else: print("離線")
例項2:
import urllib import requests from xml.etree import ElementTree as ET # 使用內建模組urllib傳送HTTP請求,或者XML格式內容 """ f = urllib.request.urlopen('http://www.webxml.com.cn/WebServices/TrainTimeWebService.asmx/getDetailInfoByTrainCode?TrainCode=G666&UserID=') result = f.read().decode('utf-8') """ # 使用第三方模組requests傳送HTTP請求,或者XML格式內容 r = requests.get('http://www.webxml.com.cn/WebServices/TrainTimeWebService.asmx/getDetailInfoByTrainCode?TrainCode=G666&UserID=') result = r.text # 解析XML格式內容 root = ET.XML(result) for node in root.iter('TrainDetailInfo'): print(node.find('TrainStation').text,node.find('StartTime').text,node.tag,node.attrib)
其他介面請求例項,參考:http://www.cnblogs.com/wupeiqi/archive/2012/11/18/2776014.html
10、logging模組
用於便捷記錄日誌且執行緒安全的模組
import logging logging.basicConfig(filename='log.log', format='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s', datefmt='%Y-%m-%d %H:%M:%S %p', level=10) logging.debug('debug') logging.info('info') logging.warning('warning') logging.error('error') logging.critical('critical') logging.log(10,'log')
日誌等級:
CRITICAL = 50 FATAL = CRITICAL ERROR = 40 WARNING = 30 WARN = WARNING INFO = 20 DEBUG = 10 NOTSET = 0
注:只有【當前寫等級】大於【日誌等級】時,日誌檔案才被記錄。
日誌記錄格式:
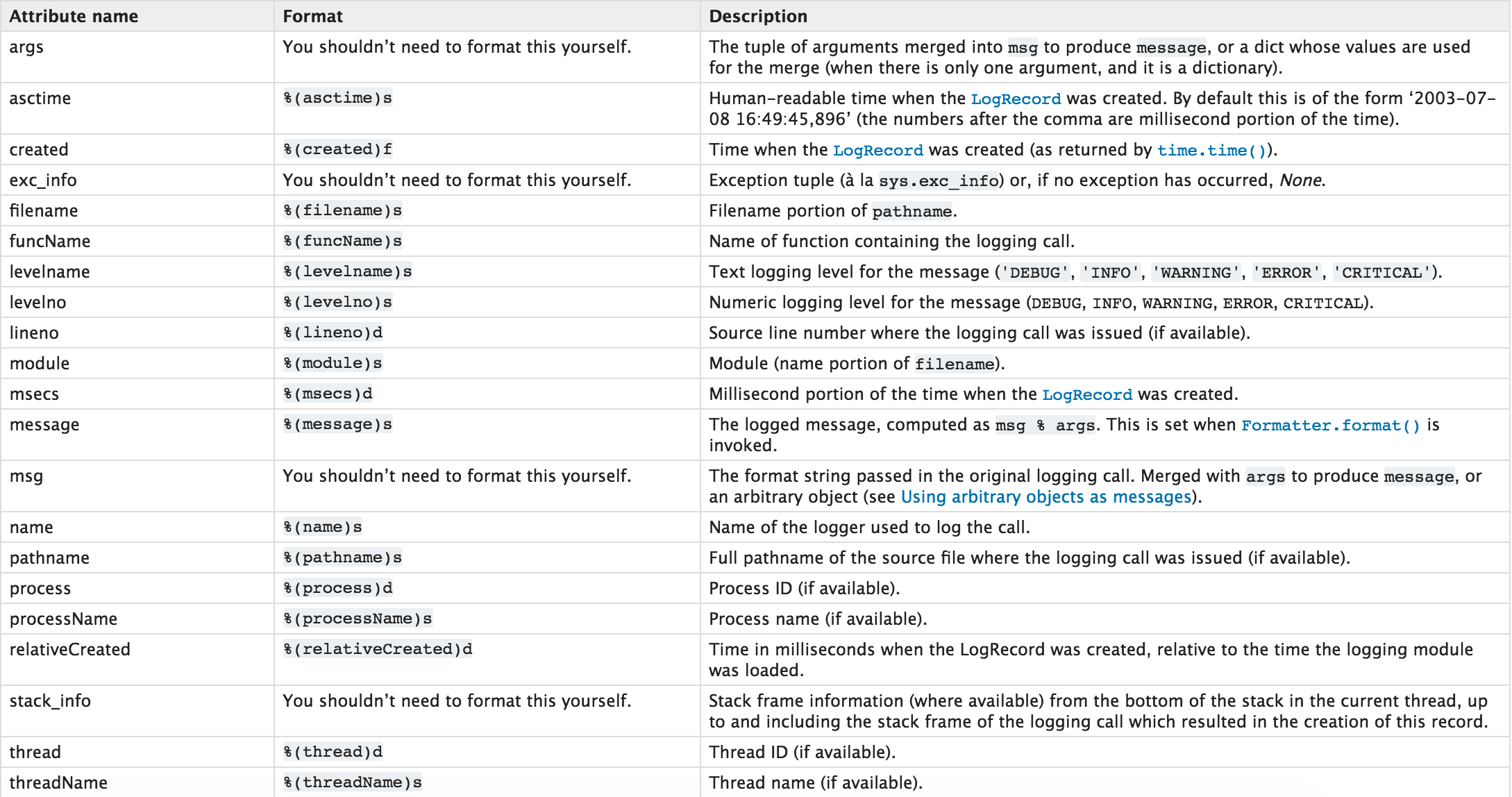
對於上述記錄日誌的功能,只能將日誌記錄在單檔案中,如果想要設定多個日誌檔案,logging.basicConfig將無法完成,需要自定義檔案和日誌操作物件。
多檔案日誌
# 定義檔案 file_2_1 = logging.FileHandler('l2_1.log', 'a') fmt = logging.Formatter() file_2_1.setFormatter(fmt) # 定義日誌 logger2 = logging.Logger('s2', level=logging.INFO) logger2.addHandler(file_2_1) 日誌(二)
如上述建立的兩個日誌物件
- 當使用【logger1】寫日誌時,會將相應的內容寫入 l1_1.log 和 l1_2.log 檔案中
- 當使用【logger2】寫日誌時,會將相應的內容寫入 l2_1.log 檔案中
11、shutil模組
高階的 檔案、資料夾、壓縮包 處理模組
(1)檔案拷貝
import shutil shutil.copyfileobj(open('old.xml','r'), open('new.xml', 'w'))
shutil.copyfile('f1.log', 'f2.log')
shutil.copymode('f1.log', 'f2.log')
shutil.copystat('f1.log', 'f2.log')
import shutil shutil.copy('f1.log', 'f2.log')
import shutil shutil.copy2('f1.log', 'f2.log')
import shutil shutil.copytree('folder1', 'folder2', symlinks=True, ,ignore=shutil.ignore_patterns('*.pyc', 'tmp*'))
(2)檔案刪除
import shutil shutil.rmtree('folder1')
import shutil shutil.move('folder1', 'folder3')
(3)檔案壓縮和解壓縮
建立壓縮包並返回檔案路徑,例如:zip、tar
- base_name: 壓縮包的檔名,也可以是壓縮包的路徑。只是檔名時,則儲存至當前目錄,否則儲存至指定路徑,
如:www =>儲存至當前路徑
如:/Users/wupeiqi/www =>儲存至/Users/wupeiqi/ - format: 壓縮包種類,“zip”, “tar”, “bztar”,“gztar”
- root_dir: 要壓縮的資料夾路徑(預設當前目錄)
- owner: 使用者,預設當前使用者
- group: 組,預設當前組
- logger: 用於記錄日誌,通常是logging.Logger物件
#將 /Users/test 下的檔案打包放置當前程式目錄 import shutil ret = shutil.make_archive("wwwwwwwwww", 'gztar', root_dir='/Users/test') #將 /Users/test 下的檔案打包放置 /Users/目錄 import shutil ret = shutil.make_archive("/Users/wwwwwwwwww", 'gztar', root_dir='/Users/test')
shutil 對壓縮包的處理是呼叫 ZipFile 和 TarFile 兩個模組來進行的:
import zipfile # 壓縮 z = zipfile.ZipFile('laxi.zip', 'w') z.write('a.log') z.write('data.data') z.close() # 解壓 z = zipfile.ZipFile('laxi.zip', 'r') z.extractall() z.close()
import tarfile # 壓縮 tar = tarfile.open('your.tar','w') tar.add('/Users/bbs2.log', arcname='bbs2.log') tar.add('/Users/cmdb.log', arcname='cmdb.log') tar.close() # 解壓 tar = tarfile.open('your.tar','r') tar.extractall() # 可設定解壓地址 tar.close()
12、paramiko模組
paramiko是一個用於做遠端控制的模組,使用該模組可以對遠端伺服器進行命令或檔案操作,值得一說的是,fabric和ansible內部的遠端管理就是使用的paramiko來現實。
此模組不屬於內建模組,需要單獨下載安裝,具體安裝命令如下:
pycrypto,由於 paramiko 模組內部依賴pycrypto,所以先下載安裝pycrypto
pip3 install pycrypto
pip3 install paramiko
#!/usr/bin/env python #coding:utf-8 import paramiko ssh = paramiko.SSHClient() ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy()) ssh.connect('192.168.1.108', 22, 'alex', '123') stdin, stdout, stderr = ssh.exec_command('df') print stdout.read() ssh.close(); 執行命令 - 使用者名稱+密碼
import paramiko private_key_path = '/home/auto/.ssh/id_rsa' key = paramiko.RSAKey.from_private_key_file(private_key_path) ssh = paramiko.SSHClient() ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy()) ssh.connect('主機名 ', 埠, '使用者名稱', key) stdin, stdout, stderr = ssh.exec_command('df') print stdout.read() ssh.close() 執行命令 - 金鑰
import os,sys import paramiko t = paramiko.Transport(('182.92.219.86',22)) t.connect(username='wupeiqi',password='123') sftp = paramiko.SFTPClient.from_transport(t) sftp.put('/tmp/test.py','/tmp/test.py') t.close() import os,sys import paramiko t = paramiko.Transport(('182.92.219.86',22)) t.connect(username='wupeiqi',password='123') sftp = paramiko.SFTPClient.from_transport(t) sftp.get('/tmp/test.py','/tmp/test2.py') t.close() 上傳或下載檔案 - 使用者名稱+密碼
import paramiko pravie_key_path = '/home/auto/.ssh/id_rsa' key = paramiko.RSAKey.from_private_key_file(pravie_key_path) t = paramiko.Transport(('182.92.219.86',22)) t.connect(username='wupeiqi',pkey=key) sftp = paramiko.SFTPClient.from_transport(t) sftp.put('/tmp/test3.py','/tmp/test3.py') t.close() import paramiko pravie_key_path = '/home/auto/.ssh/id_rsa' key = paramiko.RSAKey.from_private_key_file(pravie_key_path) t = paramiko.Transport(('182.92.219.86',22)) t.connect(username='wupeiqi',pkey=key) sftp = paramiko.SFTPClient.from_transport(t) sftp.get('/tmp/test3.py','/tmp/test4.py') t.close() 上傳或下載檔案 - 金鑰
13、time模組
時間相關的操作,時間有三種表示方式:
- 時間戳 1970年1月1日之後的秒,即:time.time(),具體示例:print(time.time()) ,結果:1501377801.9864273
- 格式化的字串 2014-11-11 11:11, 即:time.strftime('%Y-%m-%d') ,具體示例:print(time.strftime("%Y-%m-%d %X")) ,結果:2017-07-30 10:00:24
- 結構化時間 元組包含了:年、日、星期等... time.struct_time 即:time.localtime(),具體示例:print(time.localtime()),結果:time.struct_time(tm_year=2017, tm_mon=7, tm_mday=30, tm_hour=9, tm_min=25, tm_sec=4, tm_wday=6, tm_yday=211, tm_isdst=0)
##時間戳轉化為元組形式 time.gmtime():將秒轉化為UTC的元組形式 ,返回的是標準時間即0時區的當前時間 time.localtime():將秒轉為為UTC元組形式,顯示當前時間,引數值是秒,預設當前時間 ##元組轉化為時間戳形式 time.mktime() :將元組形式資料轉化為時間戳形式(秒),傳入的變數值是元組 ##元組轉化為格式化的字串時間形式 time.strftime():將元組形式的時間,轉化為格式化的字串形式 x=time.localtime() print(time.strftime('%Y-%m-%d %X',x)) ##字串時間格式轉為元組時間格式 time.strptime():將字串時間格式轉化為元組形式時間格式 x=time.strftime("%Y-%m-%d %X") print(time.strptime(x,"%Y-%m-%d %X"))
時間格式: %Y Year with century as a decimal number. %m Month as a decimal number [01,12]. %d Day of the month as a decimal number [01,31]. %H Hour (24-hour clock) as a decimal number [00,23]. %M Minute as a decimal number [00,59]. %S Second as a decimal number [00,61]. %z Time zone offset from UTC. %a Locale's abbreviated weekday name. %A Locale's full weekday name. %b Locale's abbreviated month name. %B Locale's full month name. %c Locale's appropriate date and time representation. %I Hour (12-hour clock) as a decimal number [01,12]. %p Locale's equivalent of either AM or PM. 常用獲取當前時間: time.strftime("%Y-%m-%d %X") time.localtime() time.time()
補充datetime模組:
三天後的時間:
str(datetime.now()+timedelta(3)) '2017-08-04 16:49:51.377186' 三小時前時間: str(datetime.now()+timedelta(hours=-3)) '2017-08-01 13:50:51.167165' 三分鐘後時間: str(datetime.now()+timedelta(minutes=+3)) '2017-08-01 18:30:37.745793'
四、練習題
1、通過HTTP請求和XML實現獲取電視節目
API:http://www.webxml.com.cn/webservices/ChinaTVprogramWebService.asmx
2、通過HTTP請求和JSON實現獲取天氣狀況
API:http://wthrcdn.etouch.cn/weather_mini?city=北京