一、運算子
1.算數運算子
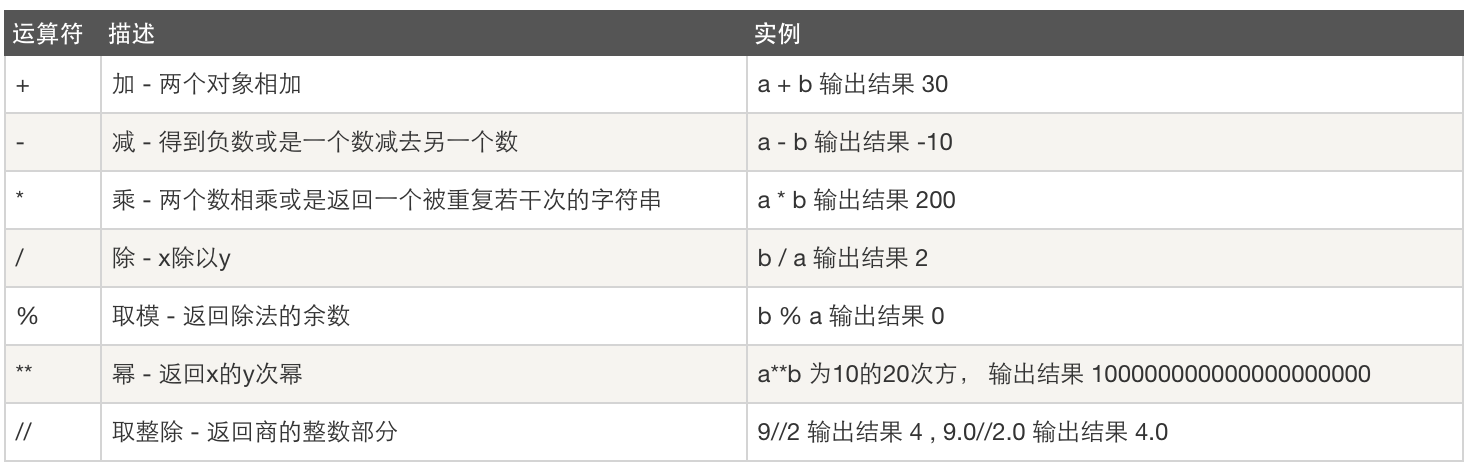
2.比較運算子

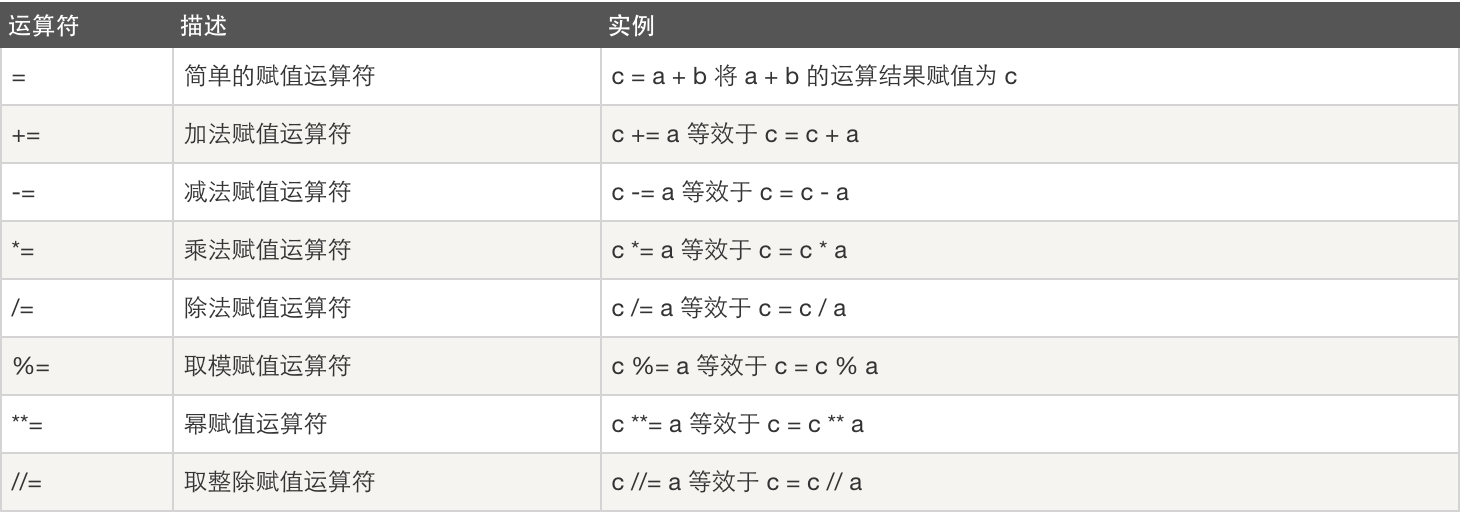
3.複製運算子
4.邏輯運算子

5.成員運算子

二、基本資料型別
1.數字
整數(int)
在32位機器上,整數的位數為32位,取值範圍為-2**31~2**31-1,即-2147483648~2147483647
在64位系統上,整數的位數為64位,取值範圍為-2**63~2**63-1,即-9223372036854775808~9223372036854775807
浮點數(fload)
浮點數也就是小數,之所以稱為浮點數,是因為按照科學記數法表示時,一個浮點數的小數點位置是可變的,比如,1.23x109和12.3x108是完全相等的。
浮點數可以用數學寫法,如1.23,3.14,-9.01,等等。但是對於很大或很小的浮點數,就必須用科學計數法表示,把10用e替代,1.23x109就是1.23e9,或者12.3e8,0.000012可以寫成1.2e-5
2.布林值
真或假
1 或 0
3.字串
str="Hello world ! "
- 移除空白
str.strip(self, chars=None)
""" 移除兩段空白 """
- 分割
str.split(self, sep=None, maxsplit=None)
""" 分割, maxsplit最多分割幾次 """
- 長度 ##len(str)
- 索引 ##str[0] 獲取字串第一個元素
- 切片
[:] 提取從開頭(預設位置0)到結尾(預設位置-1)的整個字串
str[::5]
[start:end:step][:end] 從開頭提取到end - 1
[start:end] 從start 提取到end - 1
[start:end:step] 從start 提取到end - 1,每step 個字元提取一個
左側第一個字元的位置/偏移量為0,右側最後一個字元的位置/偏移量為-1 - 大小寫轉換
str.swapcase(self) """ 大寫變小寫,小寫變大寫 """
str.upper(self)
str.lower(self)
- 替換
str.replace(self, old, new, count=None)
- 統計
str.count('le') ##統計le在str出現的次數 -
格式輸出
str.center(50,"-")
##輸出 '--------------------- Hello world ! ----------------------'


class str(basestring): """ str(object='') -> string Return a nice string representation of the object. If the argument is a string, the return value is the same object. """ def capitalize(self): """ 首字母變大寫 """ """ S.capitalize() -> string Return a copy of the string S with only its first character capitalized. """ return "" def center(self, width, fillchar=None): """ 內容居中,width:總長度;fillchar:空白處填充內容,預設無 """ """ S.center(width[, fillchar]) -> string Return S centered in a string of length width. Padding is done using the specified fill character (default is a space) """ return "" def count(self, sub, start=None, end=None): """ 子序列個數 """ """ S.count(sub[, start[, end]]) -> int Return the number of non-overlapping occurrences of substring sub in string S[start:end]. Optional arguments start and end are interpreted as in slice notation. """ return 0 def decode(self, encoding=None, errors=None): """ 解碼 """ """ S.decode([encoding[,errors]]) -> object Decodes S using the codec registered for encoding. encoding defaults to the default encoding. errors may be given to set a different error handling scheme. Default is 'strict' meaning that encoding errors raise a UnicodeDecodeError. Other possible values are 'ignore' and 'replace' as well as any other name registered with codecs.register_error that is able to handle UnicodeDecodeErrors. """ return object() def encode(self, encoding=None, errors=None): """ 編碼,針對unicode """ """ S.encode([encoding[,errors]]) -> object Encodes S using the codec registered for encoding. encoding defaults to the default encoding. errors may be given to set a different error handling scheme. Default is 'strict' meaning that encoding errors raise a UnicodeEncodeError. Other possible values are 'ignore', 'replace' and 'xmlcharrefreplace' as well as any other name registered with codecs.register_error that is able to handle UnicodeEncodeErrors. """ return object() def endswith(self, suffix, start=None, end=None): """ 是否以 xxx 結束 """ """ S.endswith(suffix[, start[, end]]) -> bool Return True if S ends with the specified suffix, False otherwise. With optional start, test S beginning at that position. With optional end, stop comparing S at that position. suffix can also be a tuple of strings to try. """ return False def expandtabs(self, tabsize=None): """ 將tab轉換成空格,預設一個tab轉換成8個空格 """ """ S.expandtabs([tabsize]) -> string Return a copy of S where all tab characters are expanded using spaces. If tabsize is not given, a tab size of 8 characters is assumed. """ return "" def find(self, sub, start=None, end=None): """ 尋找子序列位置,如果沒找到,返回 -1 """ """ S.find(sub [,start [,end]]) -> int Return the lowest index in S where substring sub is found, such that sub is contained within S[start:end]. Optional arguments start and end are interpreted as in slice notation. Return -1 on failure. """ return 0 def format(*args, **kwargs): # known special case of str.format """ 字串格式化,動態引數,將函數語言程式設計時細說 """ """ S.format(*args, **kwargs) -> string Return a formatted version of S, using substitutions from args and kwargs. The substitutions are identified by braces ('{' and '}'). """ pass def index(self, sub, start=None, end=None): """ 子序列位置,如果沒找到,報錯 """ S.index(sub [,start [,end]]) -> int Like S.find() but raise ValueError when the substring is not found. """ return 0 def isalnum(self): """ 是否是字母和數字 """ """ S.isalnum() -> bool Return True if all characters in S are alphanumeric and there is at least one character in S, False otherwise. """ return False def isalpha(self): """ 是否是字母 """ """ S.isalpha() -> bool Return True if all characters in S are alphabetic and there is at least one character in S, False otherwise. """ return False def isdigit(self): """ 是否是數字 """ """ S.isdigit() -> bool Return True if all characters in S are digits and there is at least one character in S, False otherwise. """ return False def islower(self): """ 是否小寫 """ """ S.islower() -> bool Return True if all cased characters in S are lowercase and there is at least one cased character in S, False otherwise. """ return False def isspace(self): """ S.isspace() -> bool Return True if all characters in S are whitespace and there is at least one character in S, False otherwise. """ return False def istitle(self): """ S.istitle() -> bool Return True if S is a titlecased string and there is at least one character in S, i.e. uppercase characters may only follow uncased characters and lowercase characters only cased ones. Return False otherwise. """ return False def isupper(self): """ S.isupper() -> bool Return True if all cased characters in S are uppercase and there is at least one cased character in S, False otherwise. """ return False def join(self, iterable): """ 連線 """ """ S.join(iterable) -> string Return a string which is the concatenation of the strings in the iterable. The separator between elements is S. """ return "" def ljust(self, width, fillchar=None): """ 內容左對齊,右側填充 """ """ S.ljust(width[, fillchar]) -> string Return S left-justified in a string of length width. Padding is done using the specified fill character (default is a space). """ return "" def lower(self): """ 變小寫 """ """ S.lower() -> string Return a copy of the string S converted to lowercase. """ return "" def lstrip(self, chars=None): """ 移除左側空白 """ """ S.lstrip([chars]) -> string or unicode Return a copy of the string S with leading whitespace removed. If chars is given and not None, remove characters in chars instead. If chars is unicode, S will be converted to unicode before stripping """ return "" def partition(self, sep): """ 分割,前,中,後三部分 """ """ S.partition(sep) -> (head, sep, tail) Search for the separator sep in S, and return the part before it, the separator itself, and the part after it. If the separator is not found, return S and two empty strings. """ pass def replace(self, old, new, count=None): """ 替換 """ """ S.replace(old, new[, count]) -> string Return a copy of string S with all occurrences of substring old replaced by new. If the optional argument count is given, only the first count occurrences are replaced. """ return "" def rfind(self, sub, start=None, end=None): """ S.rfind(sub [,start [,end]]) -> int Return the highest index in S where substring sub is found, such that sub is contained within S[start:end]. Optional arguments start and end are interpreted as in slice notation. Return -1 on failure. """ return 0 def rindex(self, sub, start=None, end=None): """ S.rindex(sub [,start [,end]]) -> int Like S.rfind() but raise ValueError when the substring is not found. """ return 0 def rjust(self, width, fillchar=None): """ S.rjust(width[, fillchar]) -> string Return S right-justified in a string of length width. Padding is done using the specified fill character (default is a space) """ return "" def rpartition(self, sep): """ S.rpartition(sep) -> (head, sep, tail) Search for the separator sep in S, starting at the end of S, and return the part before it, the separator itself, and the part after it. If the separator is not found, return two empty strings and S. """ pass def rsplit(self, sep=None, maxsplit=None): """ S.rsplit([sep [,maxsplit]]) -> list of strings Return a list of the words in the string S, using sep as the delimiter string, starting at the end of the string and working to the front. If maxsplit is given, at most maxsplit splits are done. If sep is not specified or is None, any whitespace string is a separator. """ return [] def rstrip(self, chars=None): """ S.rstrip([chars]) -> string or unicode Return a copy of the string S with trailing whitespace removed. If chars is given and not None, remove characters in chars instead. If chars is unicode, S will be converted to unicode before stripping """ return "" def split(self, sep=None, maxsplit=None): """ 分割, maxsplit最多分割幾次 """ """ S.split([sep [,maxsplit]]) -> list of strings Return a list of the words in the string S, using sep as the delimiter string. If maxsplit is given, at most maxsplit splits are done. If sep is not specified or is None, any whitespace string is a separator and empty strings are removed from the result. """ return [] def splitlines(self, keepends=False): """ 根據換行分割 """ """ S.splitlines(keepends=False) -> list of strings Return a list of the lines in S, breaking at line boundaries. Line breaks are not included in the resulting list unless keepends is given and true. """ return [] def startswith(self, prefix, start=None, end=None): """ 是否起始 """ """ S.startswith(prefix[, start[, end]]) -> bool Return True if S starts with the specified prefix, False otherwise. With optional start, test S beginning at that position. With optional end, stop comparing S at that position. prefix can also be a tuple of strings to try. """ return False def strip(self, chars=None): """ 移除兩段空白 """ """ S.strip([chars]) -> string or unicode Return a copy of the string S with leading and trailing whitespace removed. If chars is given and not None, remove characters in chars instead. If chars is unicode, S will be converted to unicode before stripping """ return "" def swapcase(self): """ 大寫變小寫,小寫變大寫 """ """ S.swapcase() -> string Return a copy of the string S with uppercase characters converted to lowercase and vice versa. """ return "" def title(self): """ S.title() -> string Return a titlecased version of S, i.e. words start with uppercase characters, all remaining cased characters have lowercase. """ return "" def translate(self, table, deletechars=None): """ 轉換,需要先做一個對應表,最後一個表示刪除字符集合 intab = "aeiou" outtab = "12345" trantab = maketrans(intab, outtab) str = "this is string example....wow!!!" print str.translate(trantab, 'xm') """ """ S.translate(table [,deletechars]) -> string Return a copy of the string S, where all characters occurring in the optional argument deletechars are removed, and the remaining characters have been mapped through the given translation table, which must be a string of length 256 or None. If the table argument is None, no translation is applied and the operation simply removes the characters in deletechars. """ return "" def upper(self): """ S.upper() -> string Return a copy of the string S converted to uppercase. """ return "" def zfill(self, width): """方法返回指定長度的字串,原字串右對齊,前面填充0。""" """ S.zfill(width) -> string Pad a numeric string S with zeros on the left, to fill a field of the specified width. The string S is never truncated. """ return "" def _formatter_field_name_split(self, *args, **kwargs): # real signature unknown pass def _formatter_parser(self, *args, **kwargs): # real signature unknown pass def __add__(self, y): """ x.__add__(y) <==> x+y """ pass def __contains__(self, y): """ x.__contains__(y) <==> y in x """ pass def __eq__(self, y): """ x.__eq__(y) <==> x==y """ pass def __format__(self, format_spec): """ S.__format__(format_spec) -> string Return a formatted version of S as described by format_spec. """ return "" def __getattribute__(self, name): """ x.__getattribute__('name') <==> x.name """ pass def __getitem__(self, y): """ x.__getitem__(y) <==> x[y] """ pass def __getnewargs__(self, *args, **kwargs): # real signature unknown pass def __getslice__(self, i, j): """ x.__getslice__(i, j) <==> x[i:j] Use of negative indices is not supported. """ pass def __ge__(self, y): """ x.__ge__(y) <==> x>=y """ pass def __gt__(self, y): """ x.__gt__(y) <==> x>y """ pass def __hash__(self): """ x.__hash__() <==> hash(x) """ pass def __init__(self, string=''): # known special case of str.__init__ """ str(object='') -> string Return a nice string representation of the object. If the argument is a string, the return value is the same object. # (copied from class doc) """ pass def __len__(self): """ x.__len__() <==> len(x) """ pass def __le__(self, y): """ x.__le__(y) <==> x<=y """ pass def __lt__(self, y): """ x.__lt__(y) <==> x<y """ pass def __mod__(self, y): """ x.__mod__(y) <==> x%y """ pass def __mul__(self, n): """ x.__mul__(n) <==> x*n """ pass @staticmethod # known case of __new__ def __new__(S, *more): """ T.__new__(S, ...) -> a new object with type S, a subtype of T """ pass def __ne__(self, y): """ x.__ne__(y) <==> x!=y """ pass def __repr__(self): """ x.__repr__() <==> repr(x) """ pass def __rmod__(self, y): """ x.__rmod__(y) <==> y%x """ pass def __rmul__(self, n): """ x.__rmul__(n) <==> n*x """ pass def __sizeof__(self): """ S.__sizeof__() -> size of S in memory, in bytes """ pass def __str__(self): """ x.__str__() <==> str(x) """ pass str
4. 列表
列表建立
name_list = ['alex', 'seven', 'eric'] 或 name_list = list(['alex', 'seven', 'eric'])
基本操作:
names = ['Alex',"Tenglan",'Eric'] >>> names[0] 'Alex' >>> names[2] 'Eric' >>> names[-1] 'Eric' >>> names[-2] #還可以倒著取 'Tenglan'
>>> names ['Alex', 'Tenglan', 'Eric', 'Rain', 'Tom', 'Amy'] >>> names.append("我是新來的") >>> names ['Alex', 'Tenglan', 'Eric', 'Rain', 'Tom', 'Amy', '我是新來的']
>>> names ['Alex', 'Tenglan', 'Eric', 'Rain', 'Tom', 'Amy', '我是新來的'] >>> names.insert(2,"強行從Eric前面插入") >>> names ['Alex', 'Tenglan', '強行從Eric前面插入', 'Eric', 'Rain', 'Tom', 'Amy', '我是新來的'] >>> names.insert(5,"從eric後面插入試試新姿勢") >>> names ['Alex', 'Tenglan', '強行從Eric前面插入', 'Eric', 'Rain', '從eric後面插入試試新姿勢', 'Tom', 'Amy', '我是新來的']
>>> names ['Alex', 'Tenglan', '強行從Eric前面插入', 'Eric', 'Rain', '從eric後面插入試試新姿勢', 'Tom', 'Amy', '我是新來的'] >>> names[2] = "該換人了" >>> names ['Alex', 'Tenglan', '該換人了', 'Eric', 'Rain', '從eric後面插入試試新姿勢', 'Tom', 'Amy', '我是新來的']
>>> del names[2] >>> names ['Alex', 'Tenglan', 'Eric', 'Rain', '從eric後面插入試試新姿勢', 'Tom', 'Amy', '我是新來的'] >>> del names[4] >>> names ['Alex', 'Tenglan', 'Eric', 'Rain', 'Tom', 'Amy', '我是新來的'] >>> >>> names.remove("Eric") #刪除指定元素 >>> names ['Alex', 'Tenglan', 'Rain', 'Tom', 'Amy', '我是新來的'] >>> names.pop() #刪除列表最後一個值 '我是新來的' >>> names ['Alex', 'Tenglan', 'Rain', 'Tom', 'Amy']
>>> names ['Alex', 'Tenglan', 'Rain', 'Tom', 'Amy'] >>> b = [1,2,3] >>> names.extend(b) >>> names ['Alex', 'Tenglan', 'Rain', 'Tom', 'Amy', 1, 2, 3]
>>> names = ["Alex","Tenglan","Eric","Rain","Tom","Amy"] >>> names[1:4] #取下標1至下標4之間的數字,包括1,不包括4 ['Tenglan', 'Eric', 'Rain'] >>> names[1:-1] #取下標1至-1的值,不包括-1 ['Tenglan', 'Eric', 'Rain', 'Tom'] >>> names[0:3] ['Alex', 'Tenglan', 'Eric'] >>> names[:3] #如果是從頭開始取,0可以忽略,跟上句效果一樣 ['Alex', 'Tenglan', 'Eric'] >>> names[3:] #如果想取最後一個,必須不能寫-1,只能這麼寫 ['Rain', 'Tom', 'Amy'] >>> names[3:-1] #這樣-1就不會被包含了 ['Rain', 'Tom'] >>> names[0::2] #後面的2是代表,每隔一個元素,就取一個 ['Alex', 'Eric', 'Tom'] >>> names[::2] #和上句效果一樣 ['Alex', 'Eric', 'Tom']
class list(object): """ list() -> new empty list list(iterable) -> new list initialized from iterable's items """ def append(self, p_object): # real signature unknown; restored from __doc__ """ L.append(object) -- append object to end """ pass def count(self, value): # real signature unknown; restored from __doc__ """ L.count(value) -> integer -- return number of occurrences of value """ return 0 def extend(self, iterable): # real signature unknown; restored from __doc__ """ L.extend(iterable) -- extend list by appending elements from the iterable """ pass def index(self, value, start=None, stop=None): # real signature unknown; restored from __doc__ """ L.index(value, [start, [stop]]) -> integer -- return first index of value. Raises ValueError if the value is not present. """ return 0 def insert(self, index, p_object): # real signature unknown; restored from __doc__ """ L.insert(index, object) -- insert object before index """ pass def pop(self, index=None): # real signature unknown; restored from __doc__ """ L.pop([index]) -> item -- remove and return item at index (default last). Raises IndexError if list is empty or index is out of range. """ pass def remove(self, value): # real signature unknown; restored from __doc__ """ L.remove(value) -- remove first occurrence of value. Raises ValueError if the value is not present. """ pass def reverse(self): # real signature unknown; restored from __doc__ """ L.reverse() -- reverse *IN PLACE* """ pass def sort(self, cmp=None, key=None, reverse=False): # real signature unknown; restored from __doc__ """ L.sort(cmp=None, key=None, reverse=False) -- stable sort *IN PLACE*; cmp(x, y) -> -1, 0, 1 """ pass def __add__(self, y): # real signature unknown; restored from __doc__ """ x.__add__(y) <==> x+y """ pass def __contains__(self, y): # real signature unknown; restored from __doc__ """ x.__contains__(y) <==> y in x """ pass def __delitem__(self, y): # real signature unknown; restored from __doc__ """ x.__delitem__(y) <==> del x[y] """ pass def __delslice__(self, i, j): # real signature unknown; restored from __doc__ """ x.__delslice__(i, j) <==> del x[i:j] Use of negative indices is not supported. """ pass def __eq__(self, y): # real signature unknown; restored from __doc__ """ x.__eq__(y) <==> x==y """ pass def __getattribute__(self, name): # real signature unknown; restored from __doc__ """ x.__getattribute__('name') <==> x.name """ pass def __getitem__(self, y): # real signature unknown; restored from __doc__ """ x.__getitem__(y) <==> x[y] """ pass def __getslice__(self, i, j): # real signature unknown; restored from __doc__ """ x.__getslice__(i, j) <==> x[i:j] Use of negative indices is not supported. """ pass def __ge__(self, y): # real signature unknown; restored from __doc__ """ x.__ge__(y) <==> x>=y """ pass def __gt__(self, y): # real signature unknown; restored from __doc__ """ x.__gt__(y) <==> x>y """ pass def __iadd__(self, y): # real signature unknown; restored from __doc__ """ x.__iadd__(y) <==> x+=y """ pass def __imul__(self, y): # real signature unknown; restored from __doc__ """ x.__imul__(y) <==> x*=y """ pass def __init__(self, seq=()): # known special case of list.__init__ """ list() -> new empty list list(iterable) -> new list initialized from iterable's items # (copied from class doc) """ pass def __iter__(self): # real signature unknown; restored from __doc__ """ x.__iter__() <==> iter(x) """ pass def __len__(self): # real signature unknown; restored from __doc__ """ x.__len__() <==> len(x) """ pass def __le__(self, y): # real signature unknown; restored from __doc__ """ x.__le__(y) <==> x<=y """ pass def __lt__(self, y): # real signature unknown; restored from __doc__ """ x.__lt__(y) <==> x<y """ pass def __mul__(self, n): # real signature unknown; restored from __doc__ """ x.__mul__(n) <==> x*n """ pass @staticmethod # known case of __new__ def __new__(S, *more): # real signature unknown; restored from __doc__ """ T.__new__(S, ...) -> a new object with type S, a subtype of T """ pass def __ne__(self, y): # real signature unknown; restored from __doc__ """ x.__ne__(y) <==> x!=y """ pass def __repr__(self): # real signature unknown; restored from __doc__ """ x.__repr__() <==> repr(x) """ pass def __reversed__(self): # real signature unknown; restored from __doc__ """ L.__reversed__() -- return a reverse iterator over the list """ pass def __rmul__(self, n): # real signature unknown; restored from __doc__ """ x.__rmul__(n) <==> n*x """ pass def __setitem__(self, i, y): # real signature unknown; restored from __doc__ """ x.__setitem__(i, y) <==> x[i]=y """ pass def __setslice__(self, i, j, y): # real signature unknown; restored from __doc__ """ x.__setslice__(i, j, y) <==> x[i:j]=y Use of negative indices is not supported. """ pass def __sizeof__(self): # real signature unknown; restored from __doc__ """ L.__sizeof__() -- size of L in memory, in bytes """ pass __hash__ = None list
5.元組
元組其實跟列表差不多,也是存一組數,只不是它一旦建立,便不能再修改,所以又叫只讀列表
建立元組
ages = (11, 22, 33, 44, 55)
或
ages = tuple((11, 22, 33, 44, 55))
- 索引
- 切片
-
元組類
lass tuple(object): """ tuple() -> empty tuple tuple(iterable) -> tuple initialized from iterable's items If the argument is a tuple, the return value is the same object. """ def count(self, value): # real signature unknown; restored from __doc__ """ T.count(value) -> integer -- return number of occurrences of value """ return 0 def index(self, value, start=None, stop=None): # real signature unknown; restored from __doc__ """ T.index(value, [start, [stop]]) -> integer -- return first index of value. Raises ValueError if the value is not present. """ return 0 def __add__(self, y): # real signature unknown; restored from __doc__ """ x.__add__(y) <==> x+y """ pass def __contains__(self, y): # real signature unknown; restored from __doc__ """ x.__contains__(y) <==> y in x """ pass def __eq__(self, y): # real signature unknown; restored from __doc__ """ x.__eq__(y) <==> x==y """ pass def __getattribute__(self, name): # real signature unknown; restored from __doc__ """ x.__getattribute__('name') <==> x.name """ pass def __getitem__(self, y): # real signature unknown; restored from __doc__ """ x.__getitem__(y) <==> x[y] """ pass def __getnewargs__(self, *args, **kwargs): # real signature unknown pass def __getslice__(self, i, j): # real signature unknown; restored from __doc__ """ x.__getslice__(i, j) <==> x[i:j] Use of negative indices is not supported. """ pass def __ge__(self, y): # real signature unknown; restored from __doc__ """ x.__ge__(y) <==> x>=y """ pass def __gt__(self, y): # real signature unknown; restored from __doc__ """ x.__gt__(y) <==> x>y """ pass def __hash__(self): # real signature unknown; restored from __doc__ """ x.__hash__() <==> hash(x) """ pass def __init__(self, seq=()): # known special case of tuple.__init__ """ tuple() -> empty tuple tuple(iterable) -> tuple initialized from iterable's items If the argument is a tuple, the return value is the same object. # (copied from class doc) """ pass def __iter__(self): # real signature unknown; restored from __doc__ """ x.__iter__() <==> iter(x) """ pass def __len__(self): # real signature unknown; restored from __doc__ """ x.__len__() <==> len(x) """ pass def __le__(self, y): # real signature unknown; restored from __doc__ """ x.__le__(y) <==> x<=y """ pass def __lt__(self, y): # real signature unknown; restored from __doc__ """ x.__lt__(y) <==> x<y """ pass def __mul__(self, n): # real signature unknown; restored from __doc__ """ x.__mul__(n) <==> x*n """ pass @staticmethod # known case of __new__ def __new__(S, *more): # real signature unknown; restored from __doc__ """ T.__new__(S, ...) -> a new object with type S, a subtype of T """ pass def __ne__(self, y): # real signature unknown; restored from __doc__ """ x.__ne__(y) <==> x!=y """ pass def __repr__(self): # real signature unknown; restored from __doc__ """ x.__repr__() <==> repr(x) """ pass def __rmul__(self, n): # real signature unknown; restored from __doc__ """ x.__rmul__(n) <==> n*x """ pass def __sizeof__(self): # real signature unknown; restored from __doc__ """ T.__sizeof__() -- size of T in memory, in bytes """ pass tuple
6.字典(無序)
字典是一種Key-value資料型別,無序但key必須是唯一值
建立字典
person = {"name": "mr.wu", 'age': 18}
或
person = dict({"name": "mr.wu", 'age': 18})
常用操作:
>>> info["stu1104"] = "蒼井空" >>> info {'stu1102': 'LongZe Luola', 'stu1104': '蒼井空', 'stu1103': 'XiaoZe Maliya', 'stu1101': 'TengLan Wu'}
>>> info['stu1101'] = "武藤蘭" >>> info {'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya', 'stu1101': '武藤蘭'}
>>> info {'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya', 'stu1101': '武藤蘭'} >>> info.pop("stu1101") #標準刪除姿勢 '武藤蘭' >>> info {'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya'} >>> del info['stu1103'] #換個姿勢刪除 >>> info {'stu1102': 'LongZe Luola'} >>> >>> >>> >>> info = {'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya'} >>> info {'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya'} #隨機刪除 >>> info.popitem() ('stu1102', 'LongZe Luola') >>> info {'stu1103': 'XiaoZe Maliya'}
>>> info = {'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya'}
>>>
>>> "stu1102" in info #標準用法
True
>>> info.get("stu1102") #獲取
'LongZe Luola'
>>> info["stu1102"] #同上,但是看下面
'LongZe Luola'
>>> info["stu1105"] #如果一個key不存在,就報錯,get不會,不存在只返回None
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'stu1105'
av_catalog = { "歐美":{ "www.youporn.com": ["很多免費的,世界最大的","質量一般"], "www.pornhub.com": ["很多免費的,也很大","質量比yourporn高點"], "letmedothistoyou.com": ["多是自拍,高質量圖片很多","資源不多,更新慢"], "x-art.com":["質量很高,真的很高","全部收費,屌比請繞過"] }, "日韓":{ "tokyo-hot":["質量怎樣不清楚,個人已經不喜歡日韓範了","聽說是收費的"] }, "大陸":{ "1024":["全部免費,真好,好人一生平安","伺服器在國外,慢"] } } av_catalog["大陸"]["1024"][1] += ",可以用爬蟲爬下來" print(av_catalog["大陸"]["1024"]) #ouput ['全部免費,真好,好人一生平安', '伺服器在國外,慢,可以用爬蟲爬下來']
#values >>> info.values() dict_values(['LongZe Luola', 'XiaoZe Maliya']) #keys >>> info.keys() dict_keys(['stu1102', 'stu1103']) #setdefault >>> info.setdefault("stu1106","Alex") 'Alex' >>> info {'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya', 'stu1106': 'Alex'} >>> info.setdefault("stu1102","龍澤蘿拉") 'LongZe Luola' >>> info {'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya', 'stu1106': 'Alex'} #update >>> info {'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya', 'stu1106': 'Alex'} >>> b = {1:2,3:4, "stu1102":"龍澤蘿拉"} >>> info.update(b) >>> info {'stu1102': '龍澤蘿拉', 1: 2, 3: 4, 'stu1103': 'XiaoZe Maliya', 'stu1106': 'Alex'} #items info.items() dict_items([('stu1102', '龍澤蘿拉'), (1, 2), (3, 4), ('stu1103', 'XiaoZe Maliya'), ('stu1106', 'Alex')]) #通過一個列表生成預設dict,有個沒辦法解釋的坑,少用吧這個 >>> dict.fromkeys([1,2,3],'testd') {1: 'testd', 2: 'testd', 3: 'testd'}
#方法1 for key in info: print(key,info[key]) #方法2 for k,v in info.items(): #會先把dict轉成list,資料裡大時莫用 print(k,v)
字典類class dict(object): """ dict() -> new empty dictionary dict(mapping) -> new dictionary initialized from a mapping object's (key, value) pairs dict(iterable) -> new dictionary initialized as if via: d = {} for k, v in iterable: d[k] = v dict(**kwargs) -> new dictionary initialized with the name=value pairs in the keyword argument list. For example: dict(one=1, two=2) """ def clear(self): # real signature unknown; restored from __doc__ """ 清除內容 """ """ D.clear() -> None. Remove all items from D. """ pass def copy(self): # real signature unknown; restored from __doc__ """ 淺拷貝 """ """ D.copy() -> a shallow copy of D """ pass @staticmethod # known case def fromkeys(S, v=None): # real signature unknown; restored from __doc__ """ dict.fromkeys(S[,v]) -> New dict with keys from S and values equal to v. v defaults to None. """ pass def get(self, k, d=None): # real signature unknown; restored from __doc__ """ 根據key獲取值,d是預設值 """ """ D.get(k[,d]) -> D[k] if k in D, else d. d defaults to None. """ pass def has_key(self, k): # real signature unknown; restored from __doc__ """ 是否有key """ """ D.has_key(k) -> True if D has a key k, else False """ return False def items(self): # real signature unknown; restored from __doc__ """ 所有項的列表形式 """ """ D.items() -> list of D's (key, value) pairs, as 2-tuples """ return [] def iteritems(self): # real signature unknown; restored from __doc__ """ 項可迭代 """ """ D.iteritems() -> an iterator over the (key, value) items of D """ pass def iterkeys(self): # real signature unknown; restored from __doc__ """ key可迭代 """ """ D.iterkeys() -> an iterator over the keys of D """ pass def itervalues(self): # real signature unknown; restored from __doc__ """ value可迭代 """ """ D.itervalues() -> an iterator over the values of D """ pass def keys(self): # real signature unknown; restored from __doc__ """ 所有的key列表 """ """ D.keys() -> list of D's keys """ return [] def pop(self, k, d=None): # real signature unknown; restored from __doc__ """ 獲取並在字典中移除 """ """ D.pop(k[,d]) -> v, remove specified key and return the corresponding value. If key is not found, d is returned if given, otherwise KeyError is raised """ pass def popitem(self): # real signature unknown; restored from __doc__ """ 獲取並在字典中移除 """ """ D.popitem() -> (k, v), remove and return some (key, value) pair as a 2-tuple; but raise KeyError if D is empty. """ pass def setdefault(self, k, d=None): # real signature unknown; restored from __doc__ """ 如果key不存在,則建立,如果存在,則返回已存在的值且不修改 """ """ D.setdefault(k[,d]) -> D.get(k,d), also set D[k]=d if k not in D """ pass def update(self, E=None, **F): # known special case of dict.update """ 更新 {'name':'alex', 'age': 18000} [('name','sbsbsb'),] """ """ D.update([E, ]**F) -> None. Update D from dict/iterable E and F. If E present and has a .keys() method, does: for k in E: D[k] = E[k] If E present and lacks .keys() method, does: for (k, v) in E: D[k] = v In either case, this is followed by: for k in F: D[k] = F[k] """ pass def values(self): # real signature unknown; restored from __doc__ """ 所有的值 """ """ D.values() -> list of D's values """ return [] def viewitems(self): # real signature unknown; restored from __doc__ """ 所有項,只是將內容儲存至view物件中 """ """ D.viewitems() -> a set-like object providing a view on D's items """ pass def viewkeys(self): # real signature unknown; restored from __doc__ """ D.viewkeys() -> a set-like object providing a view on D's keys """ pass def viewvalues(self): # real signature unknown; restored from __doc__ """ D.viewvalues() -> an object providing a view on D's values """ pass def __cmp__(self, y): # real signature unknown; restored from __doc__ """ x.__cmp__(y) <==> cmp(x,y) """ pass def __contains__(self, k): # real signature unknown; restored from __doc__ """ D.__contains__(k) -> True if D has a key k, else False """ return False def __delitem__(self, y): # real signature unknown; restored from __doc__ """ x.__delitem__(y) <==> del x[y] """ pass def __eq__(self, y): # real signature unknown; restored from __doc__ """ x.__eq__(y) <==> x==y """ pass def __getattribute__(self, name): # real signature unknown; restored from __doc__ """ x.__getattribute__('name') <==> x.name """ pass def __getitem__(self, y): # real signature unknown; restored from __doc__ """ x.__getitem__(y) <==> x[y] """ pass def __ge__(self, y): # real signature unknown; restored from __doc__ """ x.__ge__(y) <==> x>=y """ pass def __gt__(self, y): # real signature unknown; restored from __doc__ """ x.__gt__(y) <==> x>y """ pass def __init__(self, seq=None, **kwargs): # known special case of dict.__init__ """ dict() -> new empty dictionary dict(mapping) -> new dictionary initialized from a mapping object's (key, value) pairs dict(iterable) -> new dictionary initialized as if via: d = {} for k, v in iterable: d[k] = v dict(**kwargs) -> new dictionary initialized with the name=value pairs in the keyword argument list. For example: dict(one=1, two=2) # (copied from class doc) """ pass def __iter__(self): # real signature unknown; restored from __doc__ """ x.__iter__() <==> iter(x) """ pass def __len__(self): # real signature unknown; restored from __doc__ """ x.__len__() <==> len(x) """ pass def __le__(self, y): # real signature unknown; restored from __doc__ """ x.__le__(y) <==> x<=y """ pass def __lt__(self, y): # real signature unknown; restored from __doc__ """ x.__lt__(y) <==> x<y """ pass @staticmethod # known case of __new__ def __new__(S, *more): # real signature unknown; restored from __doc__ """ T.__new__(S, ...) -> a new object with type S, a subtype of T """ pass def __ne__(self, y): # real signature unknown; restored from __doc__ """ x.__ne__(y) <==> x!=y """ pass def __repr__(self): # real signature unknown; restored from __doc__ """ x.__repr__() <==> repr(x) """ pass def __setitem__(self, i, y): # real signature unknown; restored from __doc__ """ x.__setitem__(i, y) <==> x[i]=y """ pass def __sizeof__(self): # real signature unknown; restored from __doc__ """ D.__sizeof__() -> size of D in memory, in bytes """ pass __hash__ = None dict
7.其他
for迴圈(支援break ,continue) li = [11,22,33,44] for item in li: print item enumrate(為可迭代物件新增序號) li = [11,22,33] for k,v in enumerate(li, 1): print(k,v) range和xrange(指定範圍,生成隨機數) print range(1, 10) # 結果:[1, 2, 3, 4, 5, 6, 7, 8, 9] print range(1, 10, 2) # 結果:[1, 3, 5, 7, 9] print range(30, 0, -2) # 結果:[30, 28, 26, 24, 22, 20, 18, 16, 14, 12, 10, 8, 6, 4, 2]
三、練習題
1、元素分類
有如下值集合 [11,22,33,44,55,66,77,88,99,90...],將所有大於 66 的值儲存至字典的第一個key中,將小於 66 的值儲存至第二個key的值中。
即: {'k1': 大於66的所有值, 'k2': 小於66的所有值}
2、查詢
查詢列表中元素,移除每個元素的空格,並查詢以 a或A開頭 並且以 c 結尾的所有元素。
li = ["alec", " aric", "Alex", "Tony", "rain"]
tu = ("alec", " aric", "Alex", "Tony", "rain")
dic = {'k1': "alex", 'k2': ' aric', "k3": "Alex", "k4": "Tony"}
3、輸出商品列表,使用者輸入序號,顯示使用者選中的商品
商品 li = ["手機", "電腦", '滑鼠墊', '遊艇']
4、購物車
功能要求:
要求使用者輸入總資產,例如:2000
顯示商品列表,讓使用者根據序號選擇商品,加入購物車
購買,如果商品總額大於總資產,提示賬戶餘額不足,否則,購買成功。
附加:可充值、某商品移除購物車
goods = [
{"name": "電腦", "price": 1999},
{"name": "滑鼠", "price": 10},
{"name": "遊艇", "price": 20},
{"name": "美女", "price": 998},
]
5、使用者互動,顯示省市縣三級聯動的選擇
dic = {
"河北": {
"石家莊": ["鹿泉", "藁城", "元氏"],
"邯鄲": ["永年", "涉縣", "磁縣"],
}
"河南": {
...
}
"山西": {
...
}
}