Lucene原始碼解析--Field類
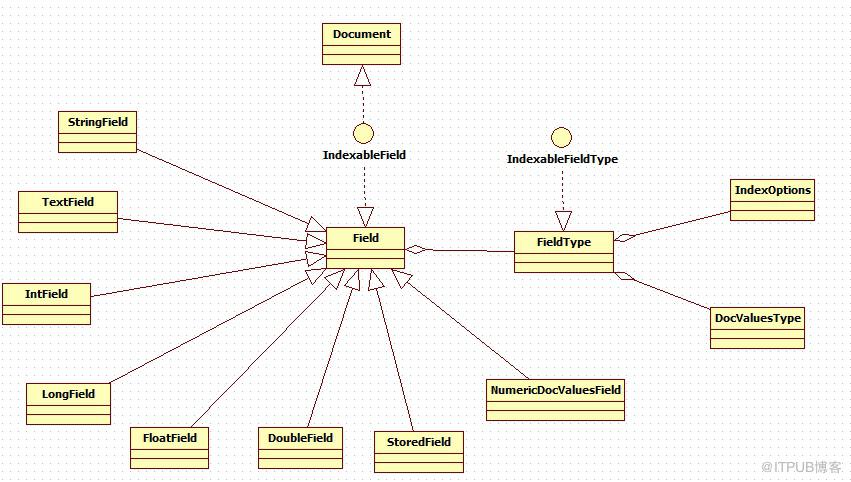
Field類:文件中的一個域,在事實上控制著被索引的域值。其組成部分包括type(域的型別),name(域的名稱),fieldsData(域的值),boost(加強因子).
Normal
0
7.8 磅
0
2
false
false
false
EN-US
ZH-CN
X-NONE
一:域的型別FieldType:描述Field的相關屬性。
1.private boolean indexed; 對field是否進行索引操作.
2.private boolean tokenized;是否使用分析器將域值分解成獨立的語彙單元流。該屬性僅當indexed()為ture時有效.
3.private boolean stored;是否儲存field的值。如果true,原始的字串值全部被儲存在索引中,並可以由IndexReader類恢復。該選項對於需要展示搜尋結果的一些域很有用(如URL,標題等)。如果為false,則索引中不儲存field的值,通常用來索引大的文字域值。如Web頁面的正文。
4.private boolean storeTermVectors;當lucene建立起倒排索引後,預設情況下它會儲存所有必要的資訊實施Vector Space Model。該Model需要計算文件中出現的term數,以及他們出現的位置。該屬性僅當indexed為true時生效。他會為field建立一個小型的倒排索引。
5.private boolean storeTermVectorOffsets;表示是否儲存field的token character的偏移量到 term vectors向量中。
6.private boolean storeTermVectorPositions;表示是否儲存field中token的位置到term vectors 向量中。
7.private boolean storeTermVectorPayloads;是否儲存field中token的比重到term vectors中。
8.private boolean omitNorms;是否要忽略field的加權基準值,如果為true可以節省記憶體消耗,但在打分質量方面會有更高的消耗,另外你也不能使用index-time 進行加權操作。
9.private IndexOptions indexOptions;描述什麼可以被記錄到倒排索引當中。
DOCS_ONLY:僅documents被索引,term的頻率和位置都將被忽略。針對field的短語或有關位置的查詢都將丟擲異常。
DOCS_AND_FREQS:documents和term的頻率被索引,term的位置被忽略。這樣可以正常打分,但針對field的短語或有關位置的查詢都將丟擲異常。
DOCS_AND_FREQS_AND_POSITIONS:這是一個全文檢索的預設設定,打分和位置檢索都支援。
DOCS_AND_FREQS_AND_POSITIONS_AND_OFFSETS:索引字元相對位置的偏移量。
10.private DocValuesType docValueType;DocValues 的型別,如果非空,field的值將被索引成docValues.
NUMERIC:數字型別
BINARY:二進位制型別
SORTED:只儲存不同的二進位制值 byte[]
SORTED_SET.
11.private boolean frozen; 阻止field屬性未來可能的變更,該屬性通常在FieldType 屬性已經被設定後呼叫。是為了防止無意識的變更。
二:Field類的建構函式
1.rotected Field(String name, FieldType type)建立一個無初始值的field.
2. public Field(String name, Reader reader, FieldType type)
使用Reader而不是String物件來表示域值。在這種情況下,域值是不能被儲存的,並且該域會一直用於分析和索引。請參照TextField
3.public Field(String name, TokenStream tokenStream, FieldType type)使用TokenStream而不是String物件來表示域值。在這種情況下,域值是不能被儲存的,並且該域會一直用於分析和索引。請參照TextField
4. public Field(String name, byte[] value, FieldType type)用二進位制來表示域值,不能被索引。
三:Field子類介紹(部分)
1.StringField:整個string作為一個單獨的分詞token.
2.TextField:A field that is indexed and tokenized, without term
vectors. For example this would be used on a 'body' field, that contains the bulk of a document's text.
3.IntField:索引int值得域,用來進行範圍過濾和排序(使用NumericRangeQuery,NumericRangeFilter,SortField.Type#INT)
4.StoredField:域值儲存到索引,以便查詢的時候進行展示。
5.NumericDocValuesField:每個文件儲存一個long值,用於排序或值檢索。
1.private boolean indexed; 對field是否進行索引操作.
2.private boolean tokenized;是否使用分析器將域值分解成獨立的語彙單元流。該屬性僅當indexed()為ture時有效.
3.private boolean stored;是否儲存field的值。如果true,原始的字串值全部被儲存在索引中,並可以由IndexReader類恢復。該選項對於需要展示搜尋結果的一些域很有用(如URL,標題等)。如果為false,則索引中不儲存field的值,通常用來索引大的文字域值。如Web頁面的正文。
4.private boolean storeTermVectors;當lucene建立起倒排索引後,預設情況下它會儲存所有必要的資訊實施Vector Space Model。該Model需要計算文件中出現的term數,以及他們出現的位置。該屬性僅當indexed為true時生效。他會為field建立一個小型的倒排索引。
5.private boolean storeTermVectorOffsets;表示是否儲存field的token character的偏移量到 term vectors向量中。
6.private boolean storeTermVectorPositions;表示是否儲存field中token的位置到term vectors 向量中。
7.private boolean storeTermVectorPayloads;是否儲存field中token的比重到term vectors中。
8.private boolean omitNorms;是否要忽略field的加權基準值,如果為true可以節省記憶體消耗,但在打分質量方面會有更高的消耗,另外你也不能使用index-time 進行加權操作。
9.private IndexOptions indexOptions;描述什麼可以被記錄到倒排索引當中。
DOCS_ONLY:僅documents被索引,term的頻率和位置都將被忽略。針對field的短語或有關位置的查詢都將丟擲異常。
DOCS_AND_FREQS:documents和term的頻率被索引,term的位置被忽略。這樣可以正常打分,但針對field的短語或有關位置的查詢都將丟擲異常。
DOCS_AND_FREQS_AND_POSITIONS:這是一個全文檢索的預設設定,打分和位置檢索都支援。
DOCS_AND_FREQS_AND_POSITIONS_AND_OFFSETS:索引字元相對位置的偏移量。
10.private DocValuesType docValueType;DocValues 的型別,如果非空,field的值將被索引成docValues.
NUMERIC:數字型別
BINARY:二進位制型別
SORTED:只儲存不同的二進位制值 byte[]
SORTED_SET.
11.private boolean frozen; 阻止field屬性未來可能的變更,該屬性通常在FieldType 屬性已經被設定後呼叫。是為了防止無意識的變更。
二:Field類的建構函式
1.rotected Field(String name, FieldType type)建立一個無初始值的field.
2. public Field(String name, Reader reader, FieldType type)
使用Reader而不是String物件來表示域值。在這種情況下,域值是不能被儲存的,並且該域會一直用於分析和索引。請參照TextField
3.public Field(String name, TokenStream tokenStream, FieldType type)使用TokenStream而不是String物件來表示域值。在這種情況下,域值是不能被儲存的,並且該域會一直用於分析和索引。請參照TextField
4. public Field(String name, byte[] value, FieldType type)用二進位制來表示域值,不能被索引。
三:Field子類介紹(部分)
1.StringField:整個string作為一個單獨的分詞token.
2.TextField:A field that is indexed and tokenized, without term
vectors. For example this would be used on a 'body' field, that contains the bulk of a document's text.
3.IntField:索引int值得域,用來進行範圍過濾和排序(使用NumericRangeQuery,NumericRangeFilter,SortField.Type#INT)
4.StoredField:域值儲存到索引,以便查詢的時候進行展示。
5.NumericDocValuesField:每個文件儲存一個long值,用於排序或值檢索。
 field.jpg
field.jpg相關文章
- Lucene原始碼解析--Lucene中的CloseableThreadLocal類原始碼thread
- Lucene原始碼解析--Lock檔案原始碼
- Lucene原始碼解析--搜尋過程<二>原始碼
- Lucene原始碼解析--刪除文件檔案(.del)原始碼
- Lucene原始碼解析--Compound File 組合檔案原始碼
- Lucene原始碼解析--IndexWriterConfig配置引數說明原始碼Index
- 求助~怎麼指定lucene查詢的field?
- Java集合類:AbstractCollection原始碼解析Java原始碼
- 利用Lucene搜尋Java原始碼Java原始碼
- Python 列舉類原始碼解析Python原始碼
- dubbo原始碼解析之ExtensionLoader類(二)原始碼
- JDK1.8原始碼解析(常見類)JDK原始碼
- CAS原子類:AtomicLongArray原始碼解析原始碼
- 容器類原始碼解析系列(三)—— HashMap 原始碼分析(最新版)原始碼HashMap
- muduo原始碼解析11-logger類原始碼
- 深入Java原始碼解析容器類List、Set、MapJava原始碼
- 容器類原始碼解析系列(一) ArrayList 原始碼分析——基於最新Android9.0原始碼原始碼Android
- 看Lucene原始碼必須知道的基本概念原始碼
- 【原始碼解析】- ArrayList原始碼解析,絕對詳細原始碼
- 容器類原始碼解析系列(四)---SparseArray分析(最新版)原始碼
- Mybatis原始碼解析3——核心類SqlSessionFactory,看完我悟了MyBatis原始碼SQLSession
- Java集合類,從原始碼解析底層實現原理Java原始碼
- Netty原始碼解析 -- 記憶體對齊類SizeClassesNetty原始碼記憶體
- Spark原始碼-SparkContext原始碼解析Spark原始碼Context
- CountDownLatch原始碼解析CountDownLatch原始碼
- LeakCanary原始碼解析原始碼
- vuex原始碼解析Vue原始碼
- ArrayBlockQueue原始碼解析BloC原始碼
- AsyncTask原始碼解析原始碼
- CopyOnWriteArrayList原始碼解析原始碼
- Express原始碼解析Express原始碼
- Observer原始碼解析Server原始碼
- SparseArray 原始碼解析原始碼
- RecyclerView原始碼解析View原始碼
- Promise 原始碼解析Promise原始碼
- Koa原始碼解析原始碼
- RateLimiter原始碼解析MIT原始碼
- redux原始碼解析Redux原始碼