文字主題模型之潛在語義索引(LSI)
在文字挖掘中,主題模型是比較特殊的一塊,它的思想不同於我們常用的機器學習演算法,因此這裡我們需要專門來總結文字主題模型的演算法。本文關注於潛在語義索引演算法(LSI)的原理。
1. 文字主題模型的問題特點
在資料分析中,我們經常會進行非監督學習的聚類演算法,它可以對我們的特徵資料進行非監督的聚類。而主題模型也是非監督的演算法,目的是得到文字按照主題的概率分佈。從這個方面來說,主題模型和普通的聚類演算法非常的類似。但是兩者其實還是有區別的。
聚類演算法關注於從樣本特徵的相似度方面將資料聚類。比如通過資料樣本之間的歐式距離,曼哈頓距離的大小聚類等。而主題模型,顧名思義,就是對文字中隱含主題的一種建模方法。比如從“人民的名義”和“達康書記”這兩個詞我們很容易發現對應的文字有很大的主題相關度,但是如果通過詞特徵來聚類的話則很難找出,因為聚類方法不能考慮到到隱含的主題這一塊。
那麼如何找到隱含的主題呢?這個一個大問題。常用的方法一般都是基於統計學的生成方法。即假設以一定的概率選擇了一個主題,然後以一定的概率選擇當前主題的詞。最後這些片語成了我們當前的文字。所有詞的統計概率分佈可以從語料庫獲得,具體如何以“一定的概率選擇”,這就是各種具體的主題模型演算法的任務了。
當然還有一些不是基於統計的方法,比如我們下面講到的LSI。
2. 潛在語義索引(LSI)概述
潛在語義索引(Latent Semantic Indexing,以下簡稱LSI),有的文章也叫Latent Semantic Analysis(LSA)。其實是一個東西,後面我們統稱LSI,它是一種簡單實用的主題模型。LSI是基於奇異值分解(SVD)的方法來得到文字的主題的。而SVD及其應用我們在前面的文章也多次講到,比如:奇異值分解(SVD)原理與在降維中的應用和矩陣分解在協同過濾推薦演算法中的應用。如果大家對SVD還不熟悉,建議複習奇異值分解(SVD)原理與在降維中的應用後再讀下面的內容。
這裡我們簡要回顧下SVD:對於一個m×nm×n的矩陣AA,可以分解為下面三個矩陣:
有時為了降低矩陣的維度到k,SVD的分解可以近似的寫為:
如果把上式用到我們的主題模型,則SVD可以這樣解釋:我們輸入的有m個文字,每個文字有n個詞。而AijAij則對應第i個文字的第j個詞的特徵值,這裡最常用的是基於預處理後的標準化TF-IDF值。k是我們假設的主題數,一般要比文字數少。SVD分解後,UilUil對應第i個文字和第l個主題的相關度。VjmVjm對應第j個詞和第m個詞義的相關度。ΣlmΣlm對應第l個主題和第m個詞義的相關度。
也可以反過來解釋:我們輸入的有m個詞,對應n個文字。而AijAij則對應第i個詞檔的第j個文字的特徵值,這裡最常用的是基於預處理後的標準化TF-IDF值。k是我們假設的主題數,一般要比文字數少。SVD分解後,UilUil對應第i個詞和第l個詞義的相關度。VjmVjm對應第j個文字和第m個主題的相關度。ΣlmΣlm對應第l個詞義和第m個主題的相關度。
這樣我們通過一次SVD,就可以得到文件和主題的相關度,詞和詞義的相關度以及詞義和主題的相關度。
3. LSI簡單例項
這裡舉一個簡單的LSI例項,假設我們有下面這個有10個詞三個文字的詞頻TF對應矩陣如下:
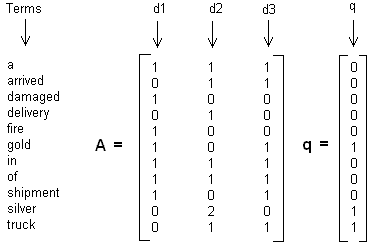
這裡我們沒有使用預處理,也沒有使用TF-IDF,在實際應用中最好使用預處理後的TF-IDF值矩陣作為輸入。
我們假定對應的主題數為2,則通過SVD降維後得到的三矩陣為:

從矩陣UkUk我們可以看到詞和詞義之間的相關性。而從VkVk可以看到3個文字和兩個主題的相關性。大家可以看到裡面有負數,所以這樣得到的相關度比較難解釋。
4. LSI用於文字相似度計算
在上面我們通過LSI得到的文字主題矩陣可以用於文字相似度計算。而計算方法一般是通過餘弦相似度。比如對於上面的三文件兩主題的例子。我們可以計算第一個文字和第二個文字的餘弦相似度如下 :
5. LSI主題模型總結
LSI是最早出現的主題模型了,它的演算法原理很簡單,一次奇異值分解就可以得到主題模型,同時解決詞義的問題,非常漂亮。但是LSI有很多不足,導致它在當前實際的主題模型中已基本不再使用。
主要的問題有:
1) SVD計算非常的耗時,尤其是我們的文字處理,詞和文字數都是非常大的,對於這樣的高維度矩陣做奇異值分解是非常難的。
2) 主題值的選取對結果的影響非常大,很難選擇合適的k值。
3) LSI得到的不是一個概率模型,缺乏統計基礎,結果難以直觀的解釋。
對於問題1),主題模型非負矩陣分解(NMF)可以解決矩陣分解的速度問題。對於問題2),這是老大難了,大部分主題模型的主題的個數選取一般都是憑經驗的,較新的層次狄利克雷過程(HDP)可以自動選擇主題個數。對於問題3),牛人們整出了pLSI(也叫pLSA)和隱含狄利克雷分佈(LDA)這類基於概率分佈的主題模型來替代基於矩陣分解的主題模型。
回到LSI本身,對於一些規模較小的問題,如果想快速粗粒度的找出一些主題分佈的關係,則LSI是比較好的一個選擇,其他時候,如果你需要使用主題模型,推薦使用LDA和HDP。
本文轉自劉建平Pinard部落格園部落格,原文連結:http://www.cnblogs.com/pinard/p/6805861.html,如需轉載請自行聯絡原作者
相關文章
- 潛在語義分析
- 文字主題模型之LDA(一) LDA基礎模型LDA
- 文字主題模型之非負矩陣分解(NMF)模型矩陣
- 教你在Python中實現潛在語義分析Python
- 文字主題模型之LDA(二) LDA求解之Gibbs取樣演算法模型LDA演算法
- 文字主題抽取:用gensim訓練LDA模型LDA模型
- 文字主題模型之LDA(三) LDA求解之變分推斷EM演算法模型LDA演算法
- 隱語義模型模型
- 基於tfidf 以及 lsi 的文字相似度分析
- Hexo 主題開發之自定義模板Hexo
- 在vue中,使用echarts的自定義主題VueEcharts
- LDA主題模型LDA模型
- pLSA主題模型模型
- 【機器學習】--隱語義模型機器學習模型
- 語義模型在智慧工業運營中的作用模型
- mysql刪除主鍵索引,刪除索引語法MySql索引
- 主題模型TopicModel:Unigram、LSA、PLSA主題模型詳解模型
- 主題模型值LDA模型LDA
- HTAP系統的問題與主義之爭
- 主題模型-LDA淺析模型LDA
- 通俗理解LDA主題模型LDA模型
- 第6章 基於潛在語義分析演算法分析維基百科演算法
- OLAP多維語義模型(一)模型
- AI大模型的潛在風險,如何做好管控?AI大模型
- 【轉】概念主題模型簡記模型
- Gensim做中文主題模型(LDA)模型LDA
- 索引模型索引模型
- 雲端計算潛在的五個問題
- 自定義部落格園主題
- ModernUI教程:建立自定義主題UI
- PowerDesiner 15 在物理模型中建立表和索引模型索引
- win10如何自定義主題_win10怎麼設定自定義主題Win10
- 「深度」A/B測試中的因果推斷——潛在結果模型模型
- TDSQL | 深度解讀HTAP系統的問題與主義之爭SQL
- 語言模型文字處理基石:Tokenizer簡明概述模型
- 黃碩:百度飛槳文心大模型在語音文字稽核中的應用大模型
- WordPress主題製作進階#10自定義主頁
- (一)文字分類經典模型之CNN篇文字分類模型CNN