在Apriori演算法原理總結中,我們對Apriori演算法的原理做了總結。作為一個挖掘頻繁項集的演算法,Apriori演算法需要多次掃描資料,I/O是很大的瓶頸。為了解決這個問題,FP Tree演算法(也稱FP Growth演算法)採用了一些技巧,無論多少資料,只需要掃描兩次資料集,因此提高了演算法執行的效率。下面我們就對FP Tree演算法做一個總結。
1. FP Tree資料結構
為了減少I/O次數,FP Tree演算法引入了一些資料結構來臨時儲存資料。這個資料結構包括三部分,如下圖所示:
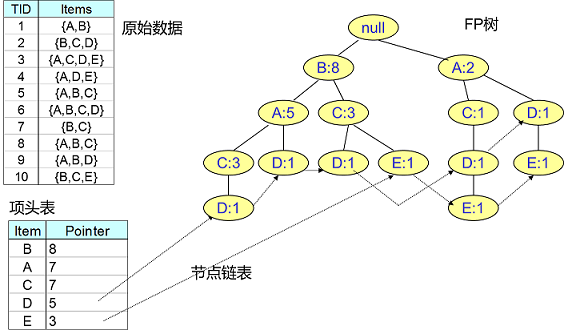
第一部分是一個項頭表。裡面記錄了所有的1項頻繁集出現的次數,按照次數降序排列。比如上圖中B在所有10組資料中出現了8次,因此排在第一位,這部分好理解。第二部分是FP Tree,它將我們的原始資料集對映到了記憶體中的一顆FP樹,這個FP樹比較難理解,它是怎麼建立的呢?這個我們後面再講。第三部分是節點連結串列。所有項頭表裡的1項頻繁集都是一個節點連結串列的頭,它依次指向FP樹中該1項頻繁集出現的位置。這樣做主要是方便項頭表和FP Tree之間的聯絡查詢和更新,也好理解。
下面我們講項頭表和FP樹的建立過程。
2. 項頭表的建立
FP樹的建立需要首先依賴項頭表的建立。首先我們看看怎麼建立項頭表。
我們第一次掃描資料,得到所有頻繁一項集的的計數。然後刪除支援度低於閾值的項,將1項頻繁集放入項頭表,並按照支援度降序排列。接著第二次也是最後一次掃描資料,將讀到的原始資料剔除非頻繁1項集,並按照支援度降序排列。
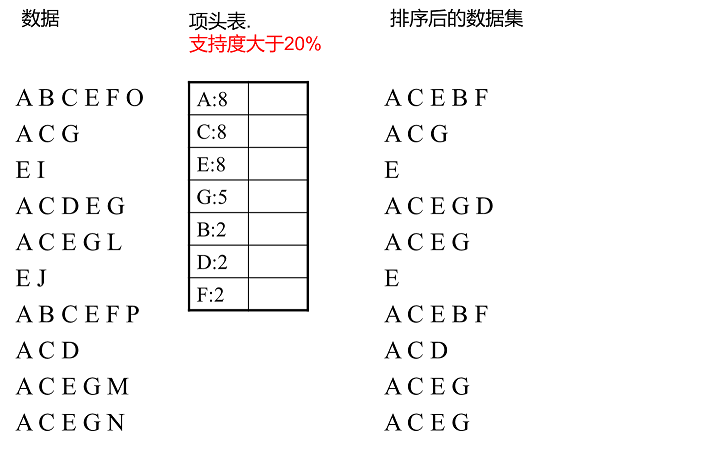
上面這段話很抽象,我們用下面這個例子來具體講解。我們有10條資料,首先第一次掃描資料並對1項集計數,我們發現O,I,L,J,P,M, N都只出現一次,支援度低於20%的閾值,因此他們不會出現在下面的項頭表中。剩下的A,C,E,G,B,D,F按照支援度的大小降序排列,組成了我們的項頭表。
接著我們第二次掃描資料,對於每條資料剔除非頻繁1項集,並按照支援度降序排列。比如資料項ABCEFO,裡面O是非頻繁1項集,因此被剔除,只剩下了ABCEF。按照支援度的順序排序,它變成了ACEBF。其他的資料項以此類推。為什麼要將原始資料集裡的頻繁1項資料項進行排序呢?這是為了我們後面的FP樹的建立時,可以儘可能的共用祖先節點。
通過兩次掃描,項頭表已經建立,排序後的資料集也已經得到了,下面我們再看看怎麼建立FP樹。
3. FP Tree的建立
有了項頭表和排序後的資料集,我們就可以開始FP樹的建立了。開始時FP樹沒有資料,建立FP樹時我們一條條的讀入排序後的資料集,插入FP樹,插入時按照排序後的順序,插入FP樹中,排序靠前的節點是祖先節點,而靠後的是子孫節點。如果有共用的祖先,則對應的公用祖先節點計數加1。插入後,如果有新節點出現,則項頭表對應的節點會通過節點連結串列連結上新節點。直到所有的資料都插入到FP樹後,FP樹的建立完成。
似乎也很抽象,我們還是用第二節的例子來描述。
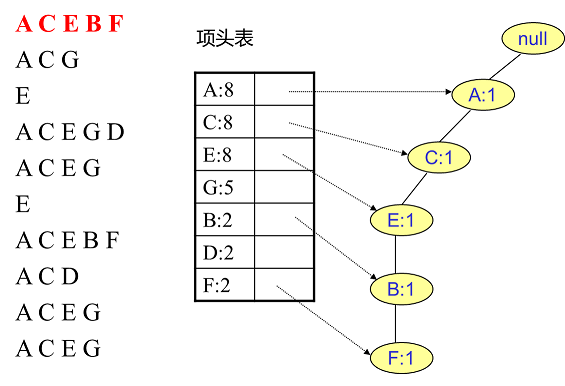
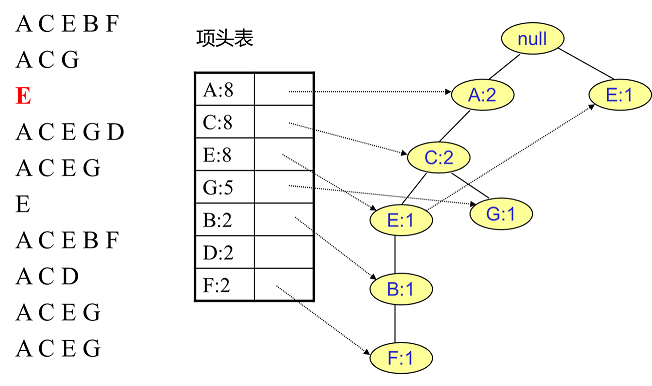
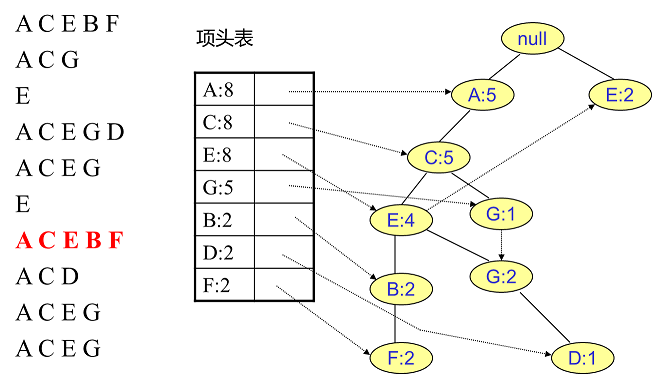
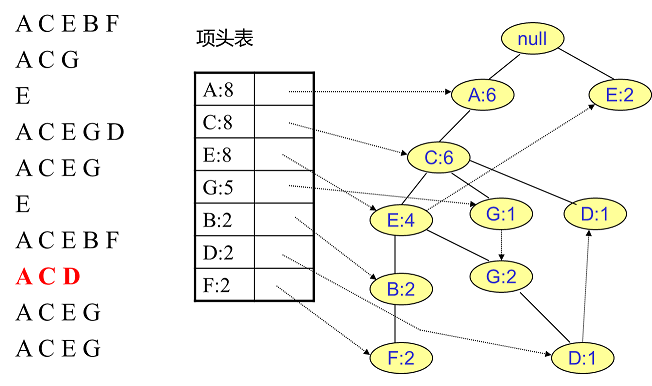
首先,我們插入第一條資料ACEBF,如下圖所示。此時FP樹沒有節點,因此ACEBF是一個獨立的路徑,所有節點計數為1, 項頭表通過節點連結串列連結上對應的新增節點。
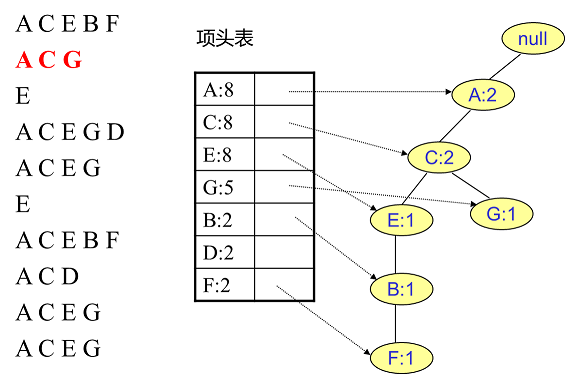
接著我們插入資料ACG,如下圖所示。由於ACG和現有的FP樹可以有共有的祖先節點序列AC,因此只需要增加一個新節點G,將新節點G的計數記為1。同時A和C的計數加1成為2。當然,對應的G節點的節點連結串列要更新
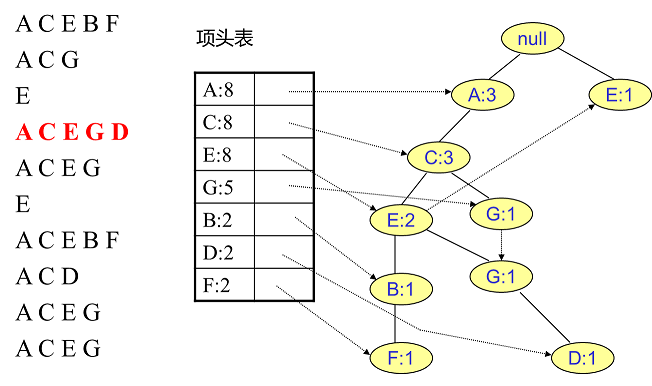
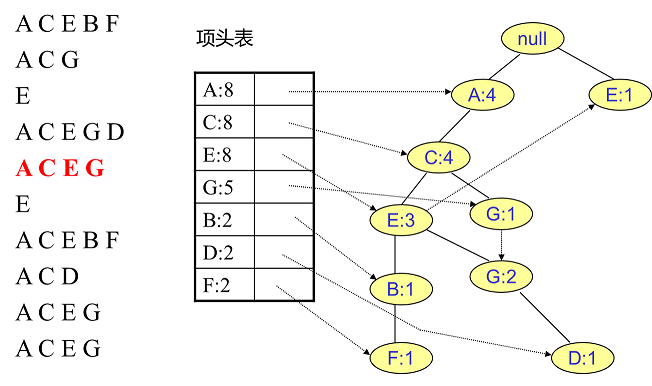
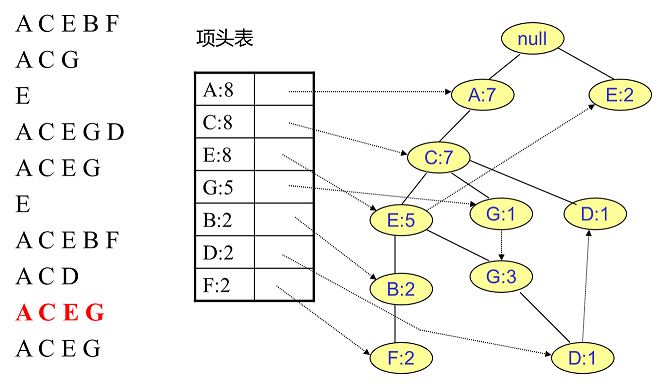
同樣的辦法可以更新後面8條資料,如下8張圖。由於原理類似,這裡就不多文字講解了,大家可以自己去嘗試插入並進行理解對比。相信如果大家自己可以獨立的插入這10條資料,那麼FP樹建立的過程就沒有什麼難度了。

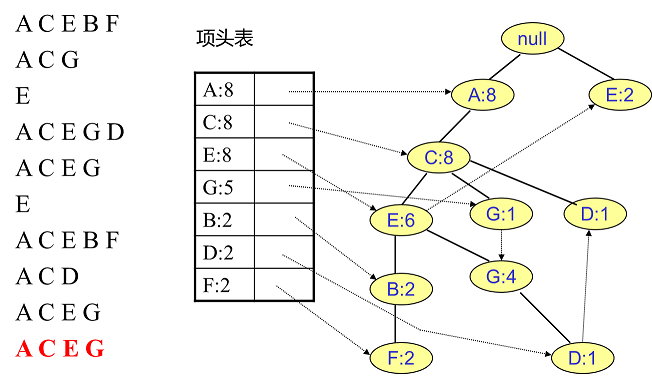
4. FP Tree的挖掘
我們辛辛苦苦,終於把FP樹建立起來了,那麼怎麼去挖掘頻繁項集呢?看著這個FP樹,似乎還是不知道怎麼下手。下面我們講如何從FP樹裡挖掘頻繁項集。得到了FP樹和項頭表以及節點連結串列,我們首先要從項頭表的底部項依次向上挖掘。對於項頭表對應於FP樹的每一項,我們要找到它的條件模式基。所謂條件模式基是以我們要挖掘的節點作為葉子節點所對應的FP子樹。得到這個FP子樹,我們將子樹中每個節點的的計數設定為葉子節點的計數,並刪除計數低於支援度的節點。從這個條件模式基,我們就可以遞迴挖掘得到頻繁項集了。
實在太抽象了,之前我看到這也是一團霧水。還是以上面的例子來講解。我們看看先從最底下的F節點開始,我們先來尋找F節點的條件模式基,由於F在FP樹中只有一個節點,因此候選就只有下圖左所示的一條路徑,對應{A:8,C:8,E:6,B:2, F:2}。我們接著將所有的祖先節點計數設定為葉子節點的計數,即FP子樹變成{A:2,C:2,E:2,B:2, F:2}。一般我們的條件模式基可以不寫葉子節點,因此最終的F的條件模式基如下圖右所示。
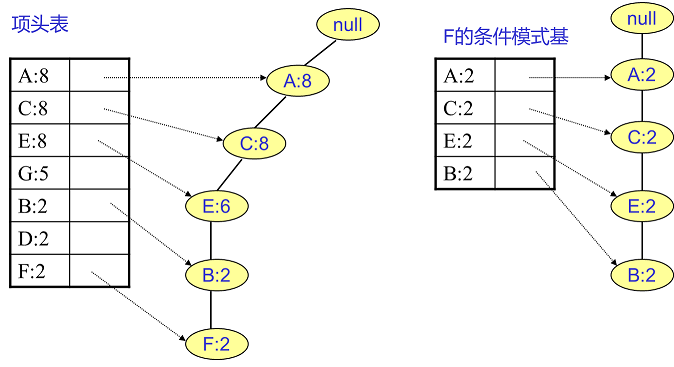
通過它,我們很容易得到F的頻繁2項集為{A:2,F:2}, {C:2,F:2}, {E:2,F:2}, {B:2,F:2}。遞迴合併二項集,得到頻繁三項集為{A:2,C:2,F:2},{A:2,E:2,F:2},...還有一些頻繁三項集,就不寫了。當然一直遞迴下去,最大的頻繁項集為頻繁5項集,為{A:2,C:2,E:2,B:2,F:2}
F挖掘完了,我們開始挖掘D節點。D節點比F節點複雜一些,因為它有兩個葉子節點,因此首先得到的FP子樹如下圖左。我們接著將所有的祖先節點計數設定為葉子節點的計數,即變成{A:2, C:2,E:1 G:1,D:1, D:1}此時E節點和G節點由於在條件模式基裡面的支援度低於閾值,被我們刪除,最終在去除低支援度節點並不包括葉子節點後D的條件模式基為{A:2, C:2}。通過它,我們很容易得到D的頻繁2項集為{A:2,D:2}, {C:2,D:2}。遞迴合併二項集,得到頻繁三項集為{A:2,C:2,D:2}。D對應的最大的頻繁項集為頻繁3項集。
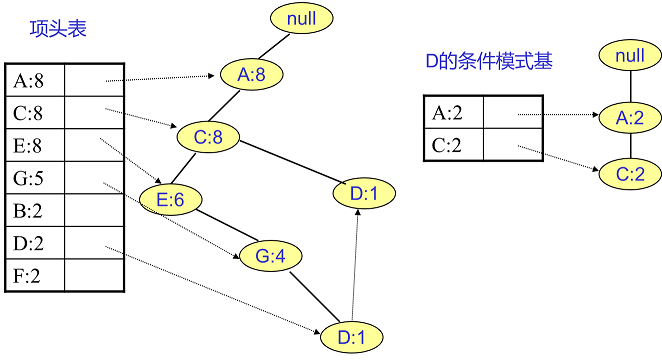
同樣的方法可以得到B的條件模式基如下圖右邊,遞迴挖掘到B的最大頻繁項集為頻繁4項集{A:2, C:2, E:2,B:2}。
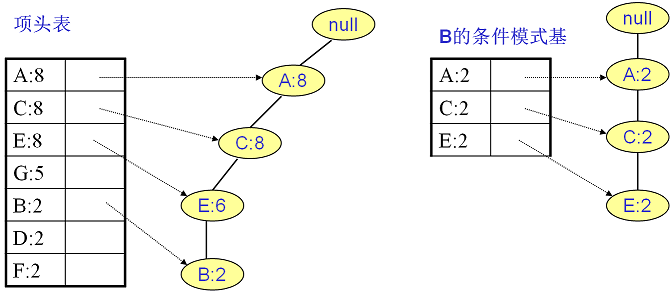
繼續挖掘G的頻繁項集,挖掘到的G的條件模式基如下圖右邊,遞迴挖掘到G的最大頻繁項集為頻繁4項集{A:5, C:5, E:4,G:4}。
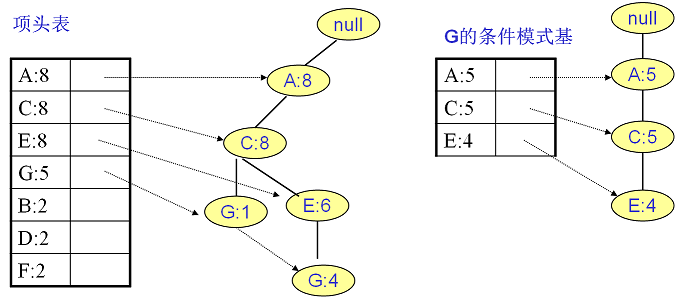
E的條件模式基如下圖右邊,遞迴挖掘到E的最大頻繁項集為頻繁3項集{A:6, C:6, E:6}。
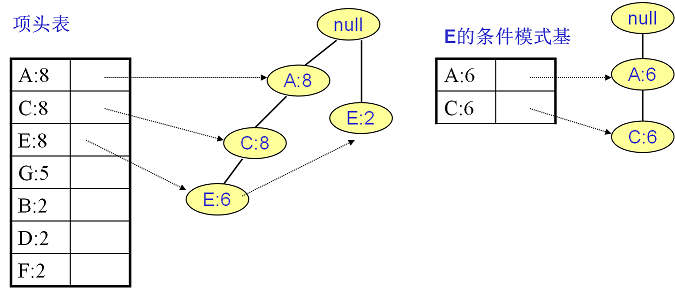
C的條件模式基如下圖右邊,遞迴挖掘到C的最大頻繁項集為頻繁2項集{A:8, C:8}。
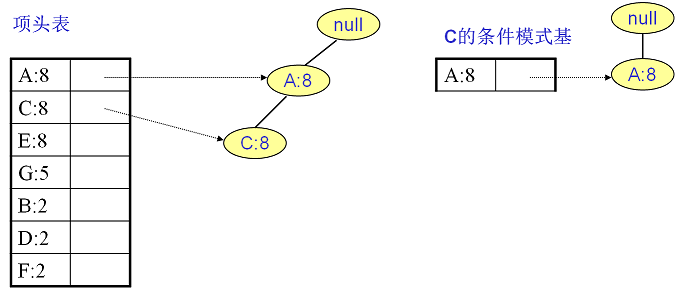
至於A,由於它的條件模式基為空,因此可以不用去挖掘了。
至此我們得到了所有的頻繁項集,如果我們只是要最大的頻繁K項集,從上面的分析可以看到,最大的頻繁項集為5項集。包括{A:2, C:2, E:2,B:2,F:2}。
通過上面的流程,相信大家對FP Tree的挖掘頻繁項集的過程也很熟悉了。
5. FP Tree演算法歸納
這裡我們對FP Tree演算法流程做一個歸納。FP Tree演算法包括三步:
1)掃描資料,得到所有頻繁一項集的的計數。然後刪除支援度低於閾值的項,將1項頻繁集放入項頭表,並按照支援度降序排列。
2)掃描資料,將讀到的原始資料剔除非頻繁1項集,並按照支援度降序排列。
3)讀入排序後的資料集,插入FP樹,插入時按照排序後的順序,插入FP樹中,排序靠前的節點是祖先節點,而靠後的是子孫節點。如果有共用的祖先,則對應的公用祖先節點計數加1。插入後,如果有新節點出現,則項頭表對應的節點會通過節點連結串列連結上新節點。直到所有的資料都插入到FP樹後,FP樹的建立完成。
4)從項頭表的底部項依次向上找到項頭表項對應的條件模式基。從條件模式基遞迴挖掘得到項頭表項項的頻繁項集。
5)如果不限制頻繁項集的項數,則返回步驟4所有的頻繁項集,否則只返回滿足項數要求的頻繁項集。
6. FP tree演算法總結
FP Tree演算法改進了Apriori演算法的I/O瓶頸,巧妙的利用了樹結構,這讓我們想起了BIRCH聚類,BIRCH聚類也是巧妙的利用了樹結構來提高演算法執行速度。利用記憶體資料結構以空間換時間是常用的提高演算法執行時間瓶頸的辦法。
在實踐中,FP Tree演算法是可以用於生產環境的關聯演算法,而Apriori演算法則做為先驅,起著關聯演算法指明燈的作用。除了FP Tree,像GSP,CBA之類的演算法都是Apriori派系的。
(歡迎轉載,轉載請註明出處。歡迎溝通交流: liujianping-ok@163.com)