在前四篇裡面我們講到了SVM的線性分類和非線性分類,以及在分類時用到的演算法。這些都關注與SVM的分類問題。實際上SVM也可以用於迴歸模型,本篇就對如何將SVM用於迴歸模型做一個總結。重點關注SVM分類和SVM迴歸的相同點與不同點。
1. SVM迴歸模型的損失函式度量
回顧下我們前面SVM分類模型中,我們的目標函式是讓$\frac{1}{2}||w||_2^2$最小,同時讓各個訓練集中的點儘量遠離自己類別一邊的的支援向量,即$y_i(w \bullet \phi(x_i )+ b) \geq 1$。如果是加入一個鬆弛變數$\xi_i \geq 0$,則目標函式是$\frac{1}{2}||w||_2^2 +C\sum\limits_{i=1}^{m}\xi_i$,對應的約束條件變成:$y_i(w \bullet \phi(x_i ) + b ) \geq 1 - \xi_i $
但是我們現在是迴歸模型,優化目標函式可以繼續和SVM分類模型保持一致為$\frac{1}{2}||w||_2^2$,但是約束條件呢?不可能是讓各個訓練集中的點儘量遠離自己類別一邊的的支援向量,因為我們是迴歸模型,沒有類別。對於迴歸模型,我們的目標是讓訓練集中的每個點$(x_i,y_i)$,儘量擬合到一個線性模型$y_i ~= w \bullet \phi(x_i ) +b $。對於一般的迴歸模型,我們是用均方差作為損失函式,但是SVM不是這樣定義損失函式的。
SVM需要我們定義一個常量$\epsilon > 0 $,對於某一個點$(x_i,y_i)$,如果$|y_i - w \bullet \phi(x_i ) -b| \leq \epsilon$,則完全沒有損失,如果$|y_i - w \bullet \phi(x_i ) -b| > \epsilon$,則對應的損失為$|y_i - w \bullet \phi(x_i ) -b| - \epsilon$,這個均方差損失函式不同,如果是均方差,那麼只要$y_i - w \bullet \phi(x_i ) -b \neq 0$,那麼就會有損失。
如下圖所示,在藍色條帶裡面的點都是沒有損失的,但是外面的點的是有損失的,損失大小為紅色線的長度。
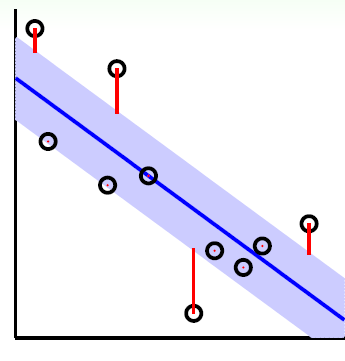
總結下,我們的SVM迴歸模型的損失函式度量為:
$$ err(x_i,y_i) =
\begin{cases}
0 & {|y_i - w \bullet \phi(x_i ) -b| \leq \epsilon}\\
|y_i - w \bullet \phi(x_i ) -b| - \epsilon & {|y_i - w \bullet \phi(x_i ) -b| > \epsilon}
\end{cases}$$
2. SVM迴歸模型的目標函式的原始形式
上一節我們已經得到了我們的損失函式的度量,現在可以可以定義我們的目標函式如下:$$min\;\; \frac{1}{2}||w||_2^2 \;\; s.t \;\; |y_i - w \bullet \phi(x_i ) -b| \leq \epsilon (i =1,2,...m)$$
和SVM分類模型相似,迴歸模型也可以對每個樣本$(x_i,y_i)$加入鬆弛變數$\xi_i \geq 0$, 但是由於我們這裡用的是絕對值,實際上是兩個不等式,也就是說兩邊都需要鬆弛變數,我們定義為$\xi_i^{\lor}, \xi_i^{\land}$, 則我們SVM迴歸模型的損失函式度量在加入鬆弛變數之後變為:$$min\;\; \frac{1}{2}||w||_2^2 + C\sum\limits_{i=1}^{m}(\xi_i^{\lor}+ \xi_i^{\land}) $$ $$s.t. \;\;\; -\epsilon - \xi_i^{\lor} \leq y_i - w \bullet \phi(x_i ) -b \leq \epsilon + \xi_i^{\land}$$ $$\xi_i^{\lor} \geq 0, \;\; \xi_i^{\land} \geq 0 \;(i = 1,2,..., m)$$
依然和SVM分類模型相似,我們可以用拉格朗日函式將目標優化函式變成無約束的形式,也就是拉格朗日函式的原始形式如下:
$$L(w,b,\alpha^{\lor}, \alpha^{\land}, \xi_i^{\lor}, \xi_i^{\land}, \mu^{\lor}, \mu^{\land}) = \frac{1}{2}||w||_2^2 + C\sum\limits_{i=1}^{m}(\xi_i^{\lor}+ \xi_i^{\land}) + \sum\limits_{i=1}^{m}\alpha^{\lor}(-\epsilon - \xi_i^{\lor} -y_i + w \bullet \phi(x_i) + b) + \sum\limits_{i=1}^{m}\alpha^{\land}(y_i - w \bullet \phi(x_i ) - b -\epsilon - \xi_i^{\land}) - \sum\limits_{i=1}^{m}\mu^{\lor}\xi_i^{\lor} - \sum\limits_{i=1}^{m}\mu^{\land}\xi_i^{\land}$$
其中 $\mu^{\lor} \geq 0, \mu^{\land} \geq 0, \alpha_i^{\lor} \geq 0, \alpha_i^{\land} \geq 0$,均為拉格朗日系數。
3. SVM迴歸模型的目標函式的對偶形式
上一節我們講到了SVM迴歸模型的目標函式的原始形式,我們的目標是$$\underbrace{min}_{w,b,\xi_i^{\lor}, \xi_i^{\land}}\; \;\;\;\;\;\;\;\;\underbrace{max}_{\mu^{\lor} \geq 0, \mu^{\land} \geq 0, \alpha_i^{\lor} \geq 0, \alpha_i^{\land} \geq 0}\;L(w,b,\alpha^{\lor}, \alpha^{\land}, \xi_i^{\lor}, \xi_i^{\land}, \mu^{\lor}, \mu^{\land}) $$
和SVM分類模型一樣,這個優化目標也滿足KKT條件,也就是說,我們可以通過拉格朗日對偶將我們的優化問題轉化為等價的對偶問題來求解如下:$$\underbrace{max}_{\mu^{\lor} \geq 0, \mu^{\land} \geq 0, \alpha_i^{\lor} \geq 0, \alpha_i^{\land} \geq 0}\; \;\;\;\;\;\;\;\;\underbrace{min}_{w,b,\xi_i^{\lor}, \xi_i^{\land}}\;L(w,b,\alpha^{\lor}, \alpha^{\land}, \xi_i^{\lor}, \xi_i^{\land}, \mu^{\lor}, \mu^{\land}) $$
我們可以先求優化函式對於$w,b,\xi_i^{\lor}, \xi_i^{\land}$的極小值, 接著再求拉格朗日乘子$\alpha^{\lor}, \alpha^{\land}, \mu^{\lor}, \mu^{\land}$的極大值。
首先我們來求優化函式對於$w,b,\xi_i^{\lor}, \xi_i^{\land}$的極小值,這個可以通過求偏導數求得:$$\frac{\partial L}{\partial w} = 0 \;\Rightarrow w = \sum\limits_{i=1}^{m}(\alpha_i^{\land} - \alpha_i^{\lor})\phi(x_i) $$ $$\frac{\partial L}{\partial b} = 0 \;\Rightarrow \sum\limits_{i=1}^{m}(\alpha_i^{\land} - \alpha_i^{\lor}) = 0$$ $$\frac{\partial L}{\partial \xi_i^{\lor}} = 0 \;\Rightarrow C-\alpha^{\lor}-\mu^{\lor} = 0$$$$\frac{\partial L}{\partial \xi_i^{\land}} = 0 \;\Rightarrow C-\alpha^{\land}-\mu^{\land} = 0$$
好了,我們可以把上面4個式子帶入$L(w,b,\alpha^{\lor}, \alpha^{\land}, \xi_i^{\lor}, \xi_i^{\land}, \mu^{\lor}, \mu^{\land}) $去消去$w,b,\xi_i^{\lor}, \xi_i^{\land}$了。
看似很複雜,其實消除過程和系列第一篇第二篇文章類似,由於式子實在是冗長,這裡我就不寫出推導過程了,最終得到的對偶形式為:$$ \underbrace{ max }_{\alpha^{\lor}, \alpha^{\land}}\; -\sum\limits_{i=1}^{m}(\epsilon-y_i)\alpha_i^{\land}+ (\epsilon+y_i)\alpha_i^{\lor}) - \frac{1}{2}\sum\limits_{i=1,j=1}^{m}(\alpha_i^{\land} - \alpha_i^{\lor})(\alpha_j^{\land} - \alpha_j^{\lor})K_{ij} $$ $$ s.t. \; \sum\limits_{i=1}^{m}(\alpha_i^{\land} - \alpha_i^{\lor}) = 0 $$ $$ 0 < \alpha_i^{\lor} < C \; (i =1,2,...m)$$ $$ 0 < \alpha_i^{\land} < C \; (i =1,2,...m)$$
對目標函式取負號,求最小值可以得到和SVM分類模型類似的求極小值的目標函式如下:$$ \underbrace{ min}_{\alpha^{\lor}, \alpha^{\land}}\; \frac{1}{2}\sum\limits_{i=1,j=1}^{m}(\alpha_i^{\land} - \alpha_i^{\lor})(\alpha_j^{\land} - \alpha_j^{\lor})K_{ij} + \sum\limits_{i=1}^{m}(\epsilon-y_i)\alpha_i^{\land}+ (\epsilon+y_i)\alpha_i^{\lor} $$ $$ s.t. \; \sum\limits_{i=1}^{m}(\alpha_i^{\land} - \alpha_i^{\lor}) = 0 $$ $$ 0 < \alpha_i^{\lor} < C \; (i =1,2,...m)$$ $$ 0 < \alpha_i^{\land} < C \; (i =1,2,...m)$$
對於這個目標函式,我們依然可以用第四篇講到的SMO演算法來求出對應的$\alpha^{\lor}, \alpha^{\land}$,進而求出我們的迴歸模型係數$w, b$。
4. SVM迴歸模型係數的稀疏性
在SVM分類模型中,我們的KKT條件的對偶互補條件為: $\alpha_{i}^{*}(y_i(w \bullet \phi(x_i) + b) - 1+\xi_i^{*}) = 0$,而在迴歸模型中,我們的對偶互補條件類似如下:$$\alpha_i^{\lor}(\epsilon + \xi_i^{\lor} + y_i - w \bullet \phi(x_i ) - b ) = 0 $$ $$\alpha_i^{\land}(\epsilon + \xi_i^{\land} - y_i + w \bullet \phi(x_i ) + b ) = 0 $$
根據鬆弛變數定義條件,如果$|y_i - w \bullet \phi(x_i ) -b| < \epsilon$,我們有$\xi_i^{\lor} = 0, \xi_i^{\land}= 0$,此時$\epsilon + \xi_i^{\lor} + y_i - w \bullet \phi(x_i ) - b \neq 0, \epsilon + \xi_i^{\land} - y_i + w \bullet \phi(x_i ) + b \neq 0$這樣要滿足對偶互補條件,只有$\alpha_i^{\lor} = 0, \alpha_i^{\land} = 0$。
我們定義樣本系數係數$$\beta_i =\alpha_i^{\land}-\alpha_i^{\lor} $$
根據上面$w$的計算式$w = \sum\limits_{i=1}^{m}(\alpha_i^{\land} - \alpha_i^{\lor})\phi(x_i) $,我們發現此時$\beta_i = 0$,也就是說$w$不受這些在誤差範圍內的點的影響。對於在邊界上或者在邊界外的點,$\alpha_i^{\lor} \neq 0, \alpha_i^{\land} \neq 0$,此時$\beta_i \neq 0$。
5. SVM 演算法小結
這個系列終於寫完了,這裡按慣例SVM 演算法做一個總結。SVM演算法是一個很優秀的演算法,在整合學習和神經網路之類的演算法沒有表現出優越效能前,SVM基本佔據了分類模型的統治地位。目前則是在大資料時代的大樣本背景下,SVM由於其在大樣本時超級大的計算量,熱度有所下降,但是仍然是一個常用的機器學習演算法。
SVM演算法的主要優點有:
1) 解決高維特徵的分類問題和迴歸問題很有效,在特徵維度大於樣本數時依然有很好的效果。
2) 僅僅使用一部分支援向量來做超平面的決策,無需依賴全部資料。
3) 有大量的核函式可以使用,從而可以很靈活的來解決各種非線性的分類迴歸問題。
4)樣本量不是海量資料的時候,分類準確率高,泛化能力強。
SVM演算法的主要缺點有:
1) 如果特徵維度遠遠大於樣本數,則SVM表現一般。
2) SVM在樣本量非常大,核函式對映維度非常高時,計算量過大,不太適合使用。
3)非線性問題的核函式的選擇沒有通用標準,難以選擇一個合適的核函式。
4)SVM對缺失資料敏感。
之後會對scikit-learn中SVM的分類演算法庫和迴歸演算法庫做一個總結,重點講述調參要點,敬請期待。
(歡迎轉載,轉載請註明出處。歡迎溝通交流: liujianping-ok@163.com)
\xi_i^{*}