產生於網際網路的大資料應用,現階段正在向其他行業領域滲透,成為行業創新和轉型的重要驅動力。根據百度多年來在大資料領域的創新與實踐,闡述了大資料驅動搜尋引擎的發展,介紹了百度大資料引擎和行業應用實踐。重點分析了大資料發展的關鍵因素,並提出了大資料和人工智慧是未來資訊科技發展的重要方向。
作者:陳尚義 百度公司
1 引言
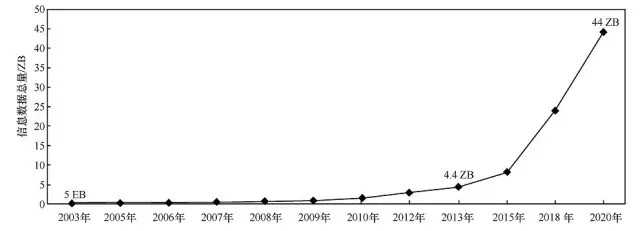
隨著移動網際網路、物聯網的快速發展,資訊採整合本不斷降低,加速物理世界向網路空間的量化。數字世界與現實世界的融合過程中產生並積累了大量的資料。根據國際資料公司(IDC)釋出的研究報告,全球所有資訊資料中90%產生於近幾年,資料總量正在以指數形式增長,從2003年的5 EB,到2013年4.4ZB,並將於2020年達到44 ZB,如圖1所示。
圖1 全球資料總量
資料爆炸將我們推向大資料時代,大資料是新一輪資訊科技革命與人類經濟社會活動的交匯融合的必然產物,資料的關聯和挖掘將創造新的價值,提升效率。資料將和自然資源、人力資源一樣成為國家最重要的戰略資源,將成為產業升級的重要推動力。
大資料因其蘊含的社會價值和商業價值,已經成為一項重要的生產要素,大資料的應用將改變傳統行業的商業模式,拉動產業升級。資料已經成為傳統行業的核心資產。產生於網際網路的大資料應用,現階段正在向製造業、金融及商業、醫療衛生、國計民生等各個領域滲透。各行業也已經意識到資料價值挖掘的重要意義,加速探索並佈局大資料應用。越來越多機構、企業都迫切希望從不同渠道獲取的多種型別、結構複雜的大資料中挖掘出有價值的趨勢洞察,快速、準確地制定決策,驅動商業和行業創新。
2 從搜尋引擎說起,大資料面面觀
2.1 搜尋引擎是個天然的大資料服務
大資料是資訊科技及其應用發展到一定階段的“自然現象”,源於資訊科技的不斷廉價化以及網際網路及其所帶來的無處不在的資訊科技延伸應用。可以說大資料應用和技術是在網際網路的快速發展中產生的,網際網路企業尤其是搜尋引擎公司是大資料實踐的先行者和領跑者。搜尋引擎連線了人和資訊、人和服務,本身就是一個完美的大資料應用例項,其目的就是為了更好地理解使用者的搜尋需求,將資訊與使用者匹配起來。
百度是當今中國人獲取資訊的最主要入口,每天響應來自138個國家和地區的數十億次搜尋請求,覆蓋95%以上的中國網民,平均每個中國網民每天使用10次百度。為了獲得更好的使用者體驗和搜尋的精準對接,百度不斷在技術上挑戰自我,在搜尋的實踐中積累了整套大資料的處理和實踐技術,佔據了世界領先的地位。同時,百度也積極在大資料的商業實踐上不斷探索,並取得了顯著的成績。
2.2 海量的資料資源是大資料實踐的基礎
百度擁有海量的資料基礎,擁有EB級別的超大資料儲存和管理規模,並達到100PB/天的資料計算能力,可達到毫秒級響應速度。百度已收錄全世界超過一萬億張網頁,相當於5 000個國家圖書館的資訊量總和。同時承擔著每天百億次的訪問請求,可離線完成1000億網頁的處理與分析,時效性網頁從更新到索引只需要幾十秒,實現大資料量級下的低延遲和秒級響應。
百度的資料具有實時性和全面性的特點,囊括了全網搜尋資料、全網評論資訊、百度內部資料以及第三方合作資料等跨行業、跨地域基礎資料,海量的資料基礎是百度引領大資料實踐的基礎。
2.3 高效的雲端計算基礎設施提供強大的計算能力
面臨龐大資料量帶來的計算能力和網路頻寬的新挑戰,百度自主研發超大規模分散式儲存和計算系統,目前能夠支援14款使用者過億的產品。其中分散式儲存系統可以儲存長文字、語音、視訊等異構資料,實現單叢集檔案數達100億;大規模分散式計算系統通過自研技術提升50%以上MapReduce的效能,實時流計算系統吞吐量達10GB/s;百度創新性地實現了基於大資料的智慧自動化運維框架,滿足超大規模叢集運維的需求,實時分析3萬以上監控指標;2 min內完成分析和故障定位,保證系統可用性為99.99%。百度是全球首家大規模商用ARM伺服器的公司,建立了大規模GPU並行化平臺,單GPU計算能力可比百片CPU,極大程度地降低了能耗和計算成本。
百度自主研發萬兆交換機,逐步從吉位元網路向萬兆網路大規模切換,正在研製的4萬兆交換機也已經開始小規模試點和驗證,百度的萬兆叢集是國內網際網路行業首個萬兆交換機的規模應用。
基於完全自主智慧財產權的高效能伺服器、整機櫃和網路裝置等,百度自主設計並建設了數個亞洲一流的資料中心,自主研發了整機櫃伺服器並已投入使用數十萬臺。通過基礎設施、IT裝置及軟體協同,定製低功耗伺服器等多項綠色節能技術,百度自建資料中心全年約一半時間實現完全免費冷卻(freecooling)。2013年,該資料中心最佳PUE(power usage effectiveness,電力使用效率)為1.16,成為國內最節能、最環保的資料中心。
2.4 人工智慧技術全面提升大資料處理能力
百度高度重視人工智慧技術的發展,經過多年的堅持努力,在語音識別、影像識別、自然語言理解、機器學習、智慧互動、數據挖掘、個性化推薦的研究和應用領域打下紮實的技術積累,攻克多項技術難題,人工智慧技術已經達到國際領先水平。
百度目前已擁有全球最大規模的深度神經網路,並實現全球最大規模的GPU平行計算平臺。百度的深度學習技術被應用在語音、影像、文字識別、自然語言處理和CTR預估等商業產品領域,取得顯著的成效。同時,百度也積極將人工智慧技術應用於大資料領域,通過機器學習和深度學習等技術提升資料智慧,尋求現有問題的解決方案,並實現更好的預測。
3 大資料推動搜尋引擎的演進
以百度為例,使用者在搜尋的過程中留下資訊,其中有大量的文字、圖片和影音等資料,形成了海量的資料資源,百度對這些複雜的異構資料進行處理分析,發掘價值,實現更多大資料應用。大資料技術推動著搜尋引擎不斷向前演進。
3.1 智慧互動
隨著使用者需求更趨於複雜化和個性化,從最初的獲取資訊,到現階段希望能夠通過搜尋引擎直接獲取答案、連線服務,這就需要實現海量資料的挖掘和智慧處理,實現人和服務的精準匹配。另外使用者也更趨向於自然的互動方式,據統計,現階段在百度的搜尋請求中10%是以語音的形式表達的,而未來5年使用語音和影像來表達需求的比例將超過50%。基於如此真實強大的需求,為了不斷提升使用者體驗,百度在影像識別和語音識別這兩項前沿技術領域實現突破,並取得了一系列領先成果。
百度在2010年開始進行智慧語音及相關技術研發,推出了第一代基於雲端識別的網際網路應用“掌上百度”。2012年11月,百度上線了中國第一款基於DNN的漢語語音搜尋系統,成為最早採用DNN技術進行商業語音服務的公司之一。目前已經積累了數萬小時的聲學訓練語料和海量文字語料[1],線上語言模型體積超過100GB,支援小時級別的海量語言模型更新。語音識別DNN深達9層,基於聽覺感知的深度學習聲學建模技術可以實現更高的精準度和識別率。在安靜情況下,百度的普通話識別率已達到95%以上,處於國際領先水平。百度語音技術對內應用於手機百度、百度輸入法、百度地圖、百度導航等一系列產品,同時對外推出開放平臺,提供多個垂直領域的識別和解析服務,合作伙伴超過30個,覆蓋汽車、醫療、手機、電商、家電和車載等十幾個領域和方向。
在影像識別領域,百度在2012年底將深度學習技術成功應用於OCR識別和人臉識別,並推出相應的PC端和移動端搜尋產品[2]。2013年,深度學習模型被成功應用於一般圖片的識別和理解。目前百度的人臉識別準確率超過98%,處於國際領先水平,影像識別技術已經用於手機百度、百度識圖等多個應用中。從百度的經驗來看,深度學習應用於影像識別不但大大提升了準確性,而且避免了人工特徵抽取的時間消耗,從而大大提高了線上計算效率。目前利用CNN(卷積神經網路)和RNN(遞迴神經網路)技術,百度成功地實現將影像內容生成自然語言的描述性句子或段落,從而在高層語義層面建立了影像和自然語言之間的橋樑,也就是“機器讀圖”,這可以說是人工智慧領域的一次技術飛躍。
3.2 知識圖譜
當使用者使用搜尋引擎時,需要的不止是索引到相關的網頁,更希望找到答案、加深瞭解以及發現更多的內容。為了使搜尋引擎更智慧,資訊的組織方式正在由網頁之間的超鏈聯絡向海量實體之間的知識聯絡演變,知識圖譜就是基於海量的網際網路資料,實現這種演變的最為重要的技術之一。
知識圖譜包含了萬物以及它們之間的聯絡,用實體以及實體關係刻畫這個世界。如圖2所示,百度知識圖譜依託於強大的網際網路資料分析技術,對網際網路海量資料進行挖掘,並應用高效精準的演算法對資料進行分類梳理,將複雜的知識體系通過資料探勘、資訊處理、知識計量和圖形繪製顯示出來,構建巨集大的知識網路,以圖文並茂的方式展現知識的方方面面,讓人們更便捷地獲取資訊、找到所求,這恰恰與百度的使命一脈相承。
圖2 百度知識圖譜示例
為了使網際網路中海量的資料及內容為機器所理解,進而形成知識供使用者獲取並使用,百度知識圖譜以實體為基點,建立了基於語義的連結關係,從海量的資料中提取出精華資訊,完成了知識的彙集、整理、再加工,構建了與國際標準接軌的資料“智囊”,目前已建成涵蓋近20領域、幾十類別、上億實體量的龐大知識資料庫。通過強大的平臺與靈活的機制,應用到20多個產品線之中,為使用者帶來多角度、全方位的搜尋體驗提升。
3.3 深度問答
深度問答是一種基於海量網際網路資料和深度語義理解的智慧系統,基於對使用者自然語言的理解,實現對海量資料的深層分析和語義理解,並通過搜尋和語義匹配技術,提煉出答案資訊,對資訊進行聚合、提煉,給出最全面、準確的結果。其實現的難點主要在於正確理解使用者複雜和多變的需求,並掌握海量結構化的知識庫資料,這就需要強大的人工智慧技術和海量複雜的大資料處理能力。深度問答其關鍵技術包括問題分析和理解技術、實體知識體系建模技術、文字分析和關係抽取技術以及語義分析和排序技術等。
● 問題分析和理解技術:針對不同型別的問題,提取答案的技術也會不同。根據可採用的技術,問題可以大致分為實體類問題和非實體類問題兩大類。實體類問題是指答案是實體的問題,對於實體類問題,問題的答案可以是唯一實體或者實體的列表,需要通過問題分析技術分析出實體類別;對於非實體類的問題,需要通過問題分析技術,把這些型別的問題跟實體類問題區分開來,因為這些問題的答案不再是實體,答案的形態也更加複雜。
● 實體知識體系建模技術:實體類問答離不開實體知識體系的支撐,實體的類別、實體間的同位、上下位關係都十分重要。因此,一個完備的實體知識體系建設(ontology)對於問題回答十分必要。實體的同位、上下位關係可以通過整合多種來源的知識獲取,包括一些結構化的資料如百度百科,也可以從普通文字中挖掘。
● 文字分析和關係抽取技術:對文字的深層分析是深度問答用到的一項基礎技術。如圖3所示,文字的分析分為多個層次,包括分詞、實體識別、句法分析乃至語義角色標註,在這些分析的基礎上可以進行知識獲取。而通過對海量資料進行深層分析,可以有效過濾文字分析引入的噪音,使得知識更加精準。文字分析和關係抽取技術不僅可以用於從普通文字抽取知識,也可以用於語義匹配。
圖3 文字分析和知識抽取技術示例
4 百度大資料引擎及行業應用實踐
4.1 百度大資料引擎
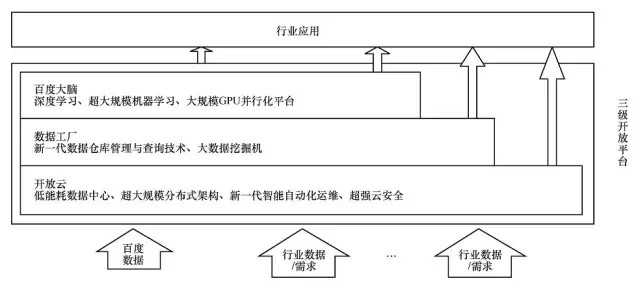
百度堅信技術改變網際網路,網際網路可以改造傳統行業。為了助力傳統行業快速進入這個大資料的時代,充分發掘和利用大資料的價值,百度對外發布大資料引擎,向外界提供大資料儲存、分析及挖掘的技術能力,這也是全球首個開放大資料引擎。
如圖4所示,百度大資料引擎主要包含三大元件:開放雲、資料工廠和百度大腦。開放雲可以將企業原本價值密度低、結構多樣的小資料匯聚成可虛擬化、可檢索的大資料,解決資料儲存和計算瓶頸;資料工廠對這些資料加工、處理、檢索,把資料關聯起來,從中挖掘出一定的價值;百度大腦是建立在百度深度學習和大規模機器學習基礎上,最終實現更具前瞻性的智慧資料分析及預測功能,以實現資料智慧,支援科學決策與創造。百度積極開放輸出百度大腦的能力,一方面助力國家在人工智慧、大資料等技術上的整體提升;另一方面也幫助行業轉型升級,提升企業的核心競爭力。
圖4 百度大資料引擎
這三大元件作為3級開放平臺支撐百度核心業務及其擴充業務,也將作為獨立或整體的開放平臺,給各行各業提供支援和服務,支援百度的核心商業應用及社會企業的新興商業模式。
4.2 百度行業應用大資料實踐
4.2.1 公眾生活領域——大資料預測
百度基於海量的資料處理能力,利用機器學習和深度學習等手段建立模型,可以實現公眾生活的預測業務。目前,在百度預測產品中已經推出了景點舒適度預測和城市旅遊預測、高考預測、世界盃預測等服務。
以世界盃預測為例,在2014年巴西世界盃的四分之一決賽前,百度、谷歌、微軟和高盛分別對4強結果進行了預測,結果顯示:百度、微軟結果預測完全正確,而谷歌則預測正確3支晉級球隊;在小組賽階段的預測,谷歌缺席,微軟、高盛的準確率也低於百度。總體來看,無論是小組賽還是淘汰賽,百度的世界盃結果預測中均領先於其他公司。最終,百度又成功預測了德國隊奪冠,如圖5所示。
圖5 百度世界盃預測
預測準確度來自百度對大資料的強大分析能力和超大規模機器學習模型。在對體育資料的研究過程中,百度的科學家發現類似保羅章魚的賽事預測完全有可能借助大資料的分析能力完成。因此,百度收集了2010-2013年全世界範圍內所有國家隊及俱樂部的賽事資料,構建了賽事預測模型,並通過對多源異構資料的綜合分析,綜合考慮球隊實力、近期狀態、主場效應、博彩資料和大賽能力等5個維度的資料。最終實現了對2014年巴西世界盃的成功預測。
4.2.2 公共衛生領域——疾病預測
通過百度搜尋資料與醫療資料、醫保資料等關聯,並結合影像識別和語音識別技術、可穿戴裝置資料採集等,通過大資料分析與挖掘能力可以實現人群疾病分佈關聯分析等。通過對大量臨床電子病歷、臨床經驗和科研成果等醫學資訊資料進行學習和理解,繪製人類疾病圖譜(人群分佈),並建立疾病分析模型和治療路徑模型。這也將極大推動疾病研究、醫藥研發、藥品監管、居民醫療服務和全民健康教育等事業發展。
百度與中國疾病預防控制中心(CDC)合作開發的疾病預測產品,基於對網民每日更新的網際網路搜尋的分析、建模,實時反饋流感、手足口、性病、愛滋病等傳染病,糖尿病、高血壓、肺癌、乳腺癌等流行病的爆發資料,並預測疾病流行趨勢,是國家疾病控制機構傳統監測體系的有力補充。結合大資料輿情分析、公共衛生危機事件預警產品,有效地融合非結構化大資料,建立了基於網際網路的新興公共衛生資料資源共享機制與服務價值鏈。
4.2.3 企業IT應用——硬碟故障預測
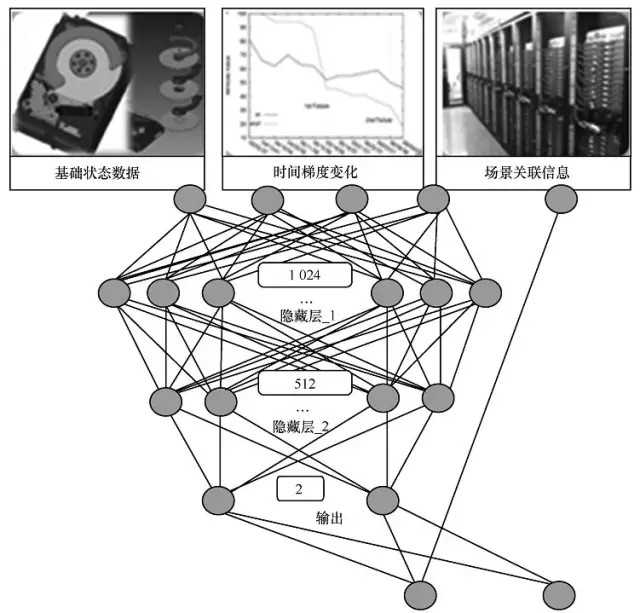
百度全球有幾十個的資料中心或者內容分發網路(CDN)節點,擁有數十萬臺伺服器和數萬臺交換機,200多萬塊硬碟。這些硬碟的年報錯率為4%~7%,月均硬碟故障超過1萬起,佔全部硬體故障的80%以上。百度通過大資料分析與機器學習技術,對9億條例項進行採集處理,選取15萬個訓練樣本,監控240個特徵的實時變化,構建預測模型,並通過機器學習的演算法可以提前一天預測出硬碟故障並遷移資料,該系統可以節約頻寬70%、節約計算資源85%、節省伺服器執行消耗10%,每年節省1萬多塊硬碟。如圖6所示,基於大資料實現硬碟故障預測的方法也可以用於實現行業硬體系統的運維和管理中。
圖6 基於大資料的硬碟故障預測
4.2.4 企業IT應用——智慧化運維
近年來百度在伺服器規模、資料規模、單叢集規模等方面出現爆發式增長。百度伺服器的規模近5年來增長了15倍以上,達到數十萬臺。資料規模已達到EB級別。在雲端計算和大資料時代,叢集規模和資料量爆發式增長,如何管理好雲端計算平臺、如何提供高質量的服務,是雲端計算的核心問題之一。
為了應對雲端計算和大資料應用帶來的新的需求和挑戰,百度同樣利用大資料技術,把線上服務運維轉向智慧化管理模式,並走在了行業的前列。百度已經建立起了六大資料倉儲之一的運維資料倉儲,囊括了伺服器、網路、系統、程式、變更等各個方面的實時及歷史狀態資料,每天更新資料量接近100TB。
基於對運維大資料的挖掘、對歷史資料的學習和異常模式識別,實現對流量資料的預測。通過對包括訪問速度、系統容量、頻寬、成本等在內的10多個因子的實時自動分析,實現了在眾多資料中心間的流量自動排程,決策時間也由人工判斷的10幾分鐘大幅縮短到1min。這個系統的實際效果在故障中得到很好的檢驗,例如系統在沒有人工介入的情況下智慧地把流量排程到另外的資料中心,拒絕流量僅有幾千個,避免類似故障可能造成數千萬的流量損失。
4.2.5 社會治理領域——上海外灘踩踏事故大資料分析
使用者去目的地之前,一般都會提前利用百度地圖搜尋地點和規劃路線。同時,百度的搜尋詞也會有一定的提前量預測某一事件。因此,對百度資料的分析可以應用於社會治理領域,實現基於大規模人群的事件預警和分析。
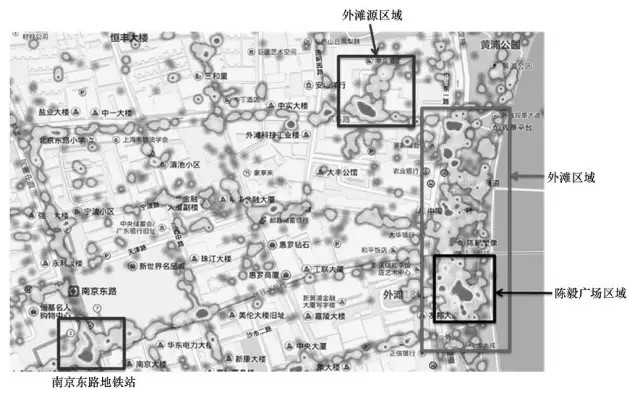
2015年初的上海外灘踩踏事件發生後,百度秉承“以資料說話”的理念,通過對百度的定位資料、搜尋資料進行挖掘,對當時的情況進行了資料化描述。圖7標明瞭南京東路地鐵站附近區域、外灘源附近區域、事發地陳毅廣場附近區域和外灘區域位置在2014年12月31日事發當時的人群熱力圖。顏色越深表示人群越密集,顏色越淺表示越稀疏。
圖7 外灘地區人群熱力圖
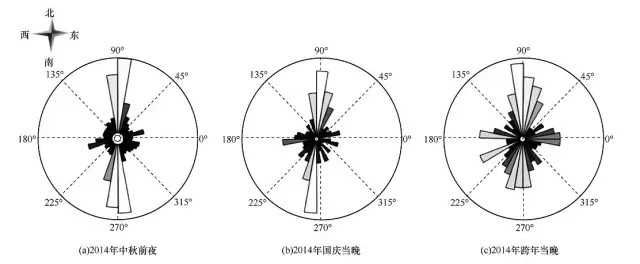
對當晚外灘區域的人流進行量化分析,得到了如圖8所示的人群流動方向分佈情況。圖8中每一扇形分割槽代表不同的人流方向,扇區半徑表示該方向人流量大小。圖8(a)和圖8(b)表示2014年中秋和國慶當晚的情況,可以看出,人流方向比較簡單和清晰,即南北向人流較多,其他方向人流較少。圖8(c)顯示了跨年當晚外灘區域的人流方向,除了南北雙向的人流,還有其他多個方向人流,人群流動方向分佈混亂。
圖8 人群流動方向分佈情況
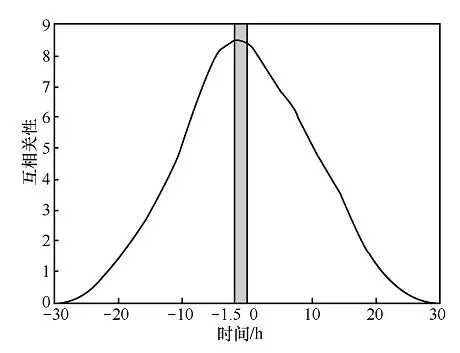
為了挖掘使用者行為的時空特性,百度對大量歷史群體聚集場合的資料進行進一步分析,包括鳥巢足球賽等。分析發現,相關地點的地圖搜尋請求峰值會早於人群密度高峰幾十分鐘出現。圖9為外灘的搜尋量和人群數量之間的互相關性相對於時延的變化曲線,其中橫軸的值為時延量,負值表示提前量。例如,橫座標-10對應的縱座標值就是提前10h的搜尋量與人群數量的相關性。從圖9中可以發現,兩個量的互相關性曲線在-1.5 h時達到了峰值,這意味著,根據地圖上相關地點搜尋的請求量,至少可能提前幾十分鐘預測出人流量峰值的到來。
圖9 搜尋量和人群數量相關性曲線
5 結束語
隨著我國各行業資訊化的快速發展,資料量激增,我國已經成為資料大國。未來如何將這些資料得以有效、科學地利用,挖掘資料價值,將我國建設為大資料技術強國,是資訊化發展的重要戰略問題。進入大資料時代,資料型別已不是單一的結構化資料,非結構化資料佔有非常大的比重,但是如果現有技術手段無法將大量的非結構化資料與結構化資料進行統一和整合,就無法發掘資料中的重要價值。而對於這些非結構化的資料進行分析和挖掘並實現其價值,人工智慧是重要的技術發展方向。大資料和計算技術的發展帶來了人工智慧的新浪潮,人工智慧的本質特徵之一是學習的能力,也就是說系統的效能會隨著經驗資料的積累而不斷提升。所以,大資料時代的到來給人工智慧的發展提供前所未有的機遇。
如圖10所示,在人工智慧領域,存在著一個正迴圈:通過人工智慧技術不斷優化產品,讓優秀產品吸引更多使用者,更多使用者產生更多資料,而更多的資料可以使人工智慧的效能得到提升,從而讓產品更優秀。
圖10 基於大資料的人工智慧正迴圈在過去的20年裡,中國企業很多時候都只能扮演技術跟隨者的角色,但是現階段我國網際網路企業在大資料處理和人工智慧等領域不斷取得突破,推動了這個正迴圈運轉加速,引領我國資訊科技的發展,並在世界範圍內樹立技術強國的形象,推動我國的大資料產業成熟和發展。
參考文獻
[1] 塗蘭敬. 百度的技術突破與應用. 中國計算機報, 2015-01-05
Tu LJ. Technology breakthrough and application of the Baidu. Chinese ComputerNewspaper, 2015-01-05
[2] 都大龍, 餘軼男, 羅恆等. 基於深度學習的影像識別進展:百度的若干實踐. 中國計算機學會通訊, 2015,11(4)
Du D L, Yu Y N, Luo H, et al. Progress of image recognition basedon deep learning:some of the Baidu practice. Communications of the CCF,2015,11(4)