依據Spark 1.4版
在哪裡會用到它
ExternalSorter是Spark的sort形式的shuffle實現的關鍵。SortShuffleWriter使用它,把RDD分割槽中的資料寫入檔案。
override def write(records: Iterator[Product2[K, V]]): Unit = { if (dep.mapSideCombine) {//根據是否需要mqp-side combine建立不同的sorter require(dep.aggregator.isDefined, "Map-side combine without Aggregator specified!") sorter = new ExternalSorter[K, V, C](dep.aggregator, Some(dep.partitioner), dep.keyOrdering, dep.serializer) sorter.insertAll(records) } else { sorter = new ExternalSorter[K, V, V](None, Some(dep.partitioner), None, dep.serializer) //如果不需要map-side combine 就不再需要Aggregator和Ordering sorter.insertAll(records) } val outputFile = shuffleBlockResolver.getDataFile(dep.shuffleId, mapId)//寫資料檔案 val blockId = ShuffleBlockId(dep.shuffleId, mapId, IndexShuffleBlockResolver.NOOP_REDUCE_ID) val partitionLengths = sorter.writePartitionedFile(blockId, context, outputFile) shuffleBlockResolver.writeIndexFile(dep.shuffleId, mapId, partitionLengths)//寫索引檔案 mapStatus = MapStatus(blockManager.shuffleServerId, partitionLengths) }
ExternalSorter的註釋
這個類的註釋提供了關於它的設計的很多資訊,先翻譯一下。
這個類用於對一些(K, V)型別的key-value對進行排序,如果需要就進行merge,生的結果是一些(K, C)型別的key-combiner對。combiner就是對同樣key的value進行合併的結果。它首先使用一個Partitioner來把key分到不同的partition,然後,如果有必要的話,就把每個partition內部的key按照一個特定的Comparator來進行排序。它可以輸出只一個分割槽了的檔案,其中不同的partition位於這個檔案的不同區域(在位元組層面上每個分割槽是連續的),這樣就適用於shuffle時對資料的抓取。
如果combining沒有啟用,C和V的型別必須相同 -- 在最後我們會對物件進行強制型別轉換。
注意:僅管ExternalSorte是一個比較通用的sorter,但是它的一些配置是和它在基於sort的shuffle的用處緊密相連的(比如,它的block壓縮是通過'spark.shuffle.compress'控制的)。 如果在非shuffle情況下使用ExternalSorter時我們想要另外的配置,可能就需要重新審視一下它的實現。
建構函式引數:
1. aggregator, 型別為Option[Aggregator], 提供combine函式,用於merge
2. partitioner, 型別為Optinon[Partitioner], 如果提供了partitioner,就先按partitionID排序,然後再按key排序
3. ordering, 型別為Option[Ordering], 用來對每個partition內部的key進行排序;必須是一個 4. total ordering(即,所有key必須可以互相比較大小,與partitial ordering不同)
4. serializer, 型別為Option[Serializer], 用於spill資料到磁碟。
注意,如果提供了Ordering, 那麼我們就總會使用它進行排序(是指對partition內部的key排序),因此,只有在真正需要輸出的資料按照key排列時才提供ordering。例如,在一個沒有map-side combine的map任務中,你應該會需要傳遞None作為ordering,這樣會避免額外的排序。另一方面,如果你的確需要combining, 提供一個Ordering會更好。
使用者應該這麼和這個型別進行互動:
- 初始化一個ExternalSorter
- 呼叫insertAll, 提供要排序的資料
- 請求一個iterator()來遍歷排序/聚合後的資料。或者,呼叫writePartitionedFiles來建立一個包含了排序/聚合後資料的檔案,這個檔案可以用於Spark的sort shuffle。
這個類在內部是這麼工作的:
- 我們重複地將資料填滿記憶體中的buffer,如果我們想要combine,就使用PartitionedAppendOnlyMap作為buffer, 如果不想要combine,就使用PartitionedSerializedPairBuffer或者PartitionedPariBuffer。在這裡buffer內部,我們使用partition Id對元素排序,如果需要,就也按key排序(對同樣partition Id的元素)。為了避免重複呼叫partitioner,我們會把record和partition ID儲存在一起。
- 當buffer達到了容量上限以後,我們把它spill到檔案。這個檔案首先按partition ID排序,然後如果需要進行聚合,就用key或者key的hashcode作為第二順序。對於每個檔案,我們會追蹤在記憶體時,每個partition裡包括多少個物件,所以我們在寫檔案 時候就不必要為每個元素記錄partition ID了。
- 當使用者請求獲取迭代器或者檔案時,spill出來的檔案就會和記憶體中的資料一起被merge,並且使用上邊定義的排列順序(除非排序和聚合都沒有開啟)。如果我們需要按照key聚合,我們要不使用Ordering引數進行全排序,要不就讀取有相同hash code的key,並且對它們進行比較來確定相等性,以進行merge。
- 使用者最後應該使用stop()來刪除中間檔案。
作為一種特殊情況,如果Ordering和Aggregator都沒有提供,並且partition的數目少於spark.shuffle.sort.bypassMergeThreshold, 我們會繞過merge-sort,每次spill時會為每個partition單獨寫一個檔案,就像HashShuffleWriter一樣。我們然後把這些檔案連線起來產生一個單獨的排序後的檔案,這時就沒有必要為每個元素進行兩次序列化和兩次反序列化(在merge中就需要這麼做)。這會加快groupBy, sort等沒有部分聚合的操作的map端的效率。
它的功能
根據註釋所述,這個類的功能包括:
1. 把kv對按partitioner分到不同的分割槽
2. 如果需要,就對相同key對應的value進行聚合
3. 把輸出的kv對寫到一個檔案,在檔案內部,kv對按照partition ID排序,如果需要的話,就對每個partition內部的kv排序。
前兩個功能,是hash-based shuffle也會做的,而第3個功能,是sort-based shuffle特有的。
為了實現這些功能,它要解決以下的問題:
- 考慮到記憶體的限制,需要進行外部排序,需要spill到磁碟檔案, 需要對這些檔案進行merge。那麼如何追蹤記憶體中資料結構的大小,spill到磁碟後的檔案應該如何組織其結構?如果進行merge?
- 如何實現aggregation?在填充資料到記憶體裡的buffer時,需要進行aggregate, spill出來的檔案在merge時,位於不同檔案裡的相同key對應的value也需要aggregate。
- 如何確定最終檔案裡每個partition以byte為單位的大小。由於壓縮流和序列化流對檔案輸出流的包裝,以及中間的buffer的影響,這個大小隻能在關閉這些流之後才能獲得。這樣的話,最終寫成的檔案會是很多輸出流的輸出追加在一起的結果。
它的實現
它的整個實現比較繁雜,但按照通常的使用方式,大體包括寫入buffer、spill、merge三個部分。
buffer
首先,充分利用記憶體作為buffer,直接對記憶體中的物件進行操作可以提高效率,減少序列化、反序列化和IO的開銷。比如在記憶體中先對部分value進行聚合,會減少要序列化和寫磁碟的資料量;在記憶體中對kv先按照partition組合在一起,也有利於以後的merge,而且越大的buffer寫到磁碟中的檔案越大,這意味著要合併的檔案就越少。
所以,就像註釋中提到的,ExternalSorter可能會用到三種型別的buffer,以應對不同的情況,提高效率。這三種buffer是
- PartitionedAppendOnlyMap
- PartitionedSerializedPairBuffer
- PartitionedPairBuffer
下面看一下這三種資料結構的特性以及適用的情境
PartitionedAppendOnlyMap
它的繼承結構是這樣的
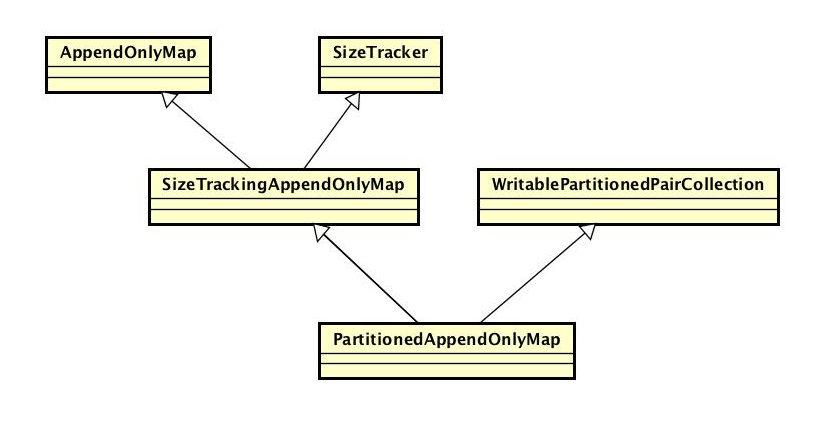
下面分別看一下它的父類
SizeTracker
這是一個trait,把它混入到集合類中用來追蹤這個集合的估計大小。之所以PartitionedAppendOnlyMap需要繼承SizeTracker,是為了確定spill的時機。
呼叫SizeEstimator的時機
它有一個afterUpdate方法,當被混入的集合的每次update操作以後,需要執行SizeTracker的afterUpdate方法,afterUpdate會判斷這是第幾次更新,需要的話就會使用SizeEstimator的estimate方法來估計下集合的大小。由於SizeEstimator的呼叫開銷比較大,註釋上說會是數毫秒,所以不能頻繁呼叫。所以SizeTracker會記錄更新的次數,發生estimate的次數是指數級增長的,基數是1.1,所以呼叫estimate時更新的次數會是1.1, 1.1 * 1.1, 1.1 * 1.1 *1.1, ....
這是指數的初始增長是很慢的, 1.1的96次方會是1w, 1.1 ^ 144次方是100w,即對於1w次update,它會執行96次estimate,對10w次update執行120次estimate, 對100w次update執行144次estimate,對1000w次update執行169次。
估計集合大小的方法
1. 每到需要estimate的更新後,就呼叫SizeEstimator估計一下當前集合的大小。用集合的大小和更新次陣列裝成一個Sample物件(一個只有這兩個field的case class),把這個Sample放個一個存放Sample history和佇列。然後取這個佇列裡最後兩個Sample,算出來這兩個Sample之間每次update這個集合size增長了多少,記為bytesPerUpdate。方法是這兩個Sample裡大小的差值除以它們update次數的差值。
(latest.size - previous.size).toDouble / (latest.numUpdates - previous.numUpdates)
2. SizeTracker的estimateSize被呼叫時,以bytePerUpdate作為最近平均每次更新時的bytePerUpdate,用當前的update次數減去最後一個Sample的update次數,然後乘以bytePerUpdate,結果加上最後一個Sample記錄的大小。
val extrapolatedDelta = bytesPerUpdate * (numUpdates - samples.last.numUpdates)
(samples.last.size + extrapolatedDelta).toLong
estimateSize方法之所以這麼設計,是為了儘量減少對SizeEstimator的呼叫。因為集合會在每次update之後呼叫estimateSize來決定是否需要spill。
感覺SizeTracker有兩個地方不太好
- 對update的定義有些寬泛。以SizeTrackingAppendOnlyMap為例, 它會在update和changeValue兩個方法中都呼叫afterUpdate。其中changeValue在使用中既被當作insert插入新的kv對,也會用於對已有的kv對進行update。對有些update方式來說,明確區分insert和對已有值的更新會使得估計更準確,比如word count中的reduceByKey,它執行對已有值的更新時,不會改變集合的大小,而只有新加入的kv會。
- 呼叫SizeEstimator時的update次數簡單地以指數增長,這種策略過於寬泛。對於一批update,保證它引發的對SizeEstimate的estimate的呼叫耗費的時間在一定可接受的值即可。SizeTrackingAppendOnly在shuffle中被使用,做為buffer,它的元素不會太多,所以update的次數有限,使得estimate的呼叫不會間隔太多update。但是如果update的次數太多,後期的estimate次數會特別少,比如在100w和1000w更新次數之間,平均每37.5w次才會呼叫一次estimate。呼叫SizeEstimator的時機應考慮到當前集合的大小、集合元素大複雜程度,在這種大小的集合上呼叫一次SizeEstimator的開銷,當前與上一次呼叫隔了多少次update等因素。或許應該提供介面或配置項,讓使用者有機會提供關於集合內資料的較準確的資訊。或者在SizeTracker的estimateSize呼叫後,讓使用者可以根據情況強制SizeTracker給出一個更準確的值,比如如果得到的size顯示需要進行spill了。
希望Spark能在以後以它進行改進。如果對集合的大小估計不準,就不能充分記憶體,這對於shuffle的效率影響非常大。
AppendOnlyMap
當需要對Value進行聚合時,會使用AppendOnlyMap作為buffer。它是一個只支援追加的map,可以修改某個key對應的value, 但是不能刪除已經存在的key。使用它是因為在shuffle的map端,刪除key不是必須的。那麼append only能帶來什麼好處呢?
1. 省記憶體
AppendOnlyMap也是一個hash map, 但它不是像java.util.collection的HashMap一樣在Hash衝突時採用連結法,而是採用二次探測法。這樣,它就不需要採用entry這種對kv對的包裝,而是把kv對寫同一個object陣列裡,減少了entry的物件頭帶來的記憶體開銷。但是二次探測法有個缺點,就是刪除元素時比較複雜,不能只是簡單地把陣列中相應位置的kv都置成null,這樣查詢元素時就沒辦法了,通常會把被刪除的元素標記為已被刪除,這就又需要額外的記憶體。而當這個hash map只支援insert和update時,情況就簡單了,不僅可以減少連結法時構造連結串列需要的記憶體,而且不需要另外的記憶體做刪除標記。在相同的load factor時,會比HashMap更省記憶體。
// Holds keys and values in the same array for memory locality; specifically, the order of // elements is key0, value0, key1, value1, key2, value2, etc. private var data = new Array[AnyRef](2 * capacity)
2. 省記憶體,可以用陣列排序演算法,排序效率高
由於所有元素都在一個陣列裡,所以在對這個map裡的kv對進行排序時,可以直接用陣列排序的演算法在陣列內做,節省了記憶體,效率也比較高。ExternalSorter的destructiveSortedIterator就是這麼做的。它把所有的kv對移動陣列的前端,然後進行排序
new Sorter(new KVArraySortDataFormat[K, AnyRef]).sort(data, 0, newIndex, keyComparator)
3. 支援函式式地update操作,適合進行aggregate。
AppendOnlyMap一個changeValue方法,它的簽名是這樣的
def changeValue(key: K, updateFunc: (Boolean, V) => V): V = { ... }
在啟用aggregate時,會把aggregate的邏輯和kv裡的value組裝成updateFunc, 來對每個key呼叫changeValue。要明白這個邏輯首先得看下Aggregator這個類的定義
case class Aggregator[K, V, C] ( createCombiner: V => C, mergeValue: (C, V) => C, mergeCombiners: (C, C) => C) { ... }
shuffle中的aggregate操作實際是把一個KV對的集合,變成一個KC對的map, C是指combiner,是V聚合成的結果。Aggregator的三個型別引數K, V, C即代表Key的型別, Value的型別和Combiner的型別。
- createCombiner描述了對於原KV對裡由一個Value生成Combiner,以作為聚合的起始點。
- mergeValue描述瞭如何把一個新的Value(型別為V)合併到之前聚合的結果(型別為C)裡
- mergeCombiner描述瞭如何把兩個分別聚合好了的Combiner再聚合
這三個函式就描述了aggregate所遇到的各種情況。
先看下reduceByKey
def reduceByKey(partitioner: Partitioner, func: (V, V) => V): RDD[(K, V)] = self.withScope { combineByKey[V]((v: V) => v, func, func, partitioner) }
它接收的函式引數的型別為 (V, V) => V, 也就是說Value和Combiner的型別是一樣的,所以它會生成一個Aggregator[K, V, V],它的三個構造器引數分別為
(v: V) => v, func, func。 這符合reduceByKey的意義。
與此不同的是aggregateByKey,由於它指定了一個初始值zeroValue,所以初始的Combiner應該是把這個初始值和Value聚合的結果。為此,它是這麼做的
def aggregateByKey[U: ClassTag](zeroValue: U, partitioner: Partitioner)(seqOp: (U, V) => U, combOp: (U, U) => U): RDD[(K, U)] = self.withScope { // Serialize the zero value to a byte array so that we can get a new clone of it on each key val zeroBuffer = SparkEnv.get.serializer.newInstance().serialize(zeroValue) val zeroArray = new Array[Byte](zeroBuffer.limit) zeroBuffer.get(zeroArray) lazy val cachedSerializer = SparkEnv.get.serializer.newInstance() val createZero = () => cachedSerializer.deserialize[U](ByteBuffer.wrap(zeroArray)) // We will clean the combiner closure later in `combineByKey` val cleanedSeqOp = self.context.clean(seqOp) combineByKey[U]((v: V) => cleanedSeqOp(createZero(), v), cleanedSeqOp, combOp, partitioner) }
首先,createCombiner每次呼叫時,需要一個屬於自己的zeroValue的拷貝,否則變成共享的就麻煩了,比如當zeroValue是一個集合時。所以aggregateByKey的createCombiner方法每次執行會反序列化一個zeroValue,然後呼叫mergeValue函式(也就是seqOp函式)建立初始的Combiner。
與此類似的是groupByKey,它的createCombiner函式是構造一個只有Value一個元素的集合,mergeValue函式即是把Value新增到這個集合,而mergeCombiner函式是對集合進行合併。
可見Aggregator的確能描述各種不同的聚合策略。那麼Aggregator的這三個函式是如何被用於AppendOnlyMap的呢?
首先,只有在需要對Value進行聚合時,才會使用AppendOnlyMap作為buffer。而此時,在ExternalSorter的insertAll函式中,是這麼使用它的
if (shouldCombine) { // Combine values in-memory first using our AppendOnlyMap val mergeValue = aggregator.get.mergeValue val createCombiner = aggregator.get.createCombiner var kv: Product2[K, V] = null val update = (hadValue: Boolean, oldValue: C) => { if (hadValue) mergeValue(oldValue, kv._2) else createCombiner(kv._2) } while (records.hasNext) { // Runtime.getRuntime.maxMemory() addElementsRead() kv = records.next() map.changeValue((getPartition(kv._1), kv._1), update) maybeSpillCollection(usingMap = true) } }
注意它是如何用createCombiner和mergeValue兩個函式組裝成AppendOnlyMap的changeValue函式所需要的update函式。這種直觀地對函式地組合的確是函數語言程式設計的一種優勢。
SizeTrackingAppendOnlyMap
它繼承自AppendOnlyMap和SizeTracker,覆蓋了AppendOnlyMap的三個方法
- update和changeValue。 在呼叫AppendOnlyMap的相應方法後,呼叫SizeTracker的afterUpdate方法
- growTable。在呼叫AppendOnlyMap的growTable方法後,呼叫SizeTracker的resetSamples方法。
實際上SizeTrackingAppendOnlyMap對於SizeTracker的使用有些簡單粗暴。比如在growTable之後,AppendOnlyMap的data陣列會增長,所以之前的bytesPerUpdate就不準確了,但這時候直接呼叫resetSamples會清空之前的取樣,重置update次數。而AppendOnlyMap的data陣列額外佔據的空間可以根據它的capacity的變化算出來,這使得之前的bytesPerUpdate的值可以繼續使用。對於一個很多的集合呼叫resetSamples,會使得對它的取樣更密集,並不是一個特別好的做法。
WritablePartitionedPairCollection
這個trait的大部分方法都是未實現的,它描述了一個分割槽的kv集合應具有的性質。這個集合的特點在於,它的destructiveSortedWritablePartitionedIterator應該返回一個WritablePartitionedIterator物件。WritablePartitionedIterator可以使用BlockObjectWriter來寫入它的元素。
private[spark] trait WritablePartitionedIterator { def writeNext(writer: BlockObjectWriter): Unit def hasNext(): Boolean def nextPartition(): Int }
此外它的伴生物件會提供兩種Comparator
- PartitionComparator 按照partition ID排序
- PartitionKeyComparator 它先按partition ID排序,再按key排序。按key排序時使用的Comparator是作為引數提供的。
此外, WriteablePartitionedIterator的伴生物件有一個fromIterator方法,它接受一個Iterator[((Int, _), _)]型別的迭代器,返回一個特殊的WritablePartitionedIterator物件,此物件的特點在於它的writeNext方法只寫入Key和Value,並不寫入Partition ID。ExternalSorter的三種buffer都是使用這個fromIterator方法,從自身的iterator生成WritablePartitionIterator。所以,它們三個的iterator方法返回的迭代器的KV對中,K的型別就是(Int, Key的型別)。
PartitionedAppendOnlyMap
它繼承自WritablePartitionedPairCollection和SizeTrackingAppendOnlyMap, ExternalSorter在需要進行aggregate元素的情況下,用它做為buffer。
需要注意一下它的型別引數
private[spark] class PartitionedAppendOnlyMap[K, V] extends SizeTrackingAppendOnlyMap[(Int, K), V] with WritablePartitionedPairCollection[K, V]
它本身是一個KV集合,Key的型別是K, Value的型別是V。但是它繼承了SizeTrackingAppendOnlyMap[(Int, K), V],這意味著SizeTrackingAppendOnlyMap繼承的AppendOnlyMap的型別是AppendOnlyMap[(Int, K), V]。也就是說PartitionedAppendOnlyMap繼承的AppendOnlyMap的Key的型別為(Int, K), Value的型別為V。
這個Int就是Partition ID。所以PartitionedAppendOnlyMap定義了一個partitioneDestructiveSortedIterator方法,返回一個Iterator[(Int, K), V]。
def partitionedDestructiveSortedIterator(keyComparator: Option[Comparator[K]]) : Iterator[((Int, K), V)] = { val comparator = keyComparator.map(partitionKeyComparator).getOrElse(partitionComparator) destructiveSortedIterator(comparator) }
這個迭代器的排序方式由keyComparator決定,如果keyComparator是None,就用WritablePartitionedPairCollection的partitionComparator只按partition排序, 如果是Some,就按照WritablePartitionedPairCollection的partitionKeyComparator排序,也就是先按partition ID排序,再使用keyComparator按key排序。
PartitionedPairBuffer和PartitionedSerializedPairBuffer
下面看一下另兩種buffer: PartitionedPairBuffer和PartitionedSerializedPairBuffer。它們都不支援aggregation,但是ExternalSorter是如何在二者間選擇的呢?
private val useSerializedPairBuffer = !ordering.isDefined && conf.getBoolean("spark.shuffle.sort.serializeMapOutputs", true) && ser.supportsRelocationOfSerializedObjects
如果useSerializedPairBuffer為true,就會使用PartitionedSerailizedPairBuffer。而它為true必須有三個條件同時滿足:
- 沒有提供Ordering。即不需要對partition內部的kv再排序。
- spark.shuffle.sort.searlizedMapOutputs為true。它預設即為true
- serializer支援relocate序列化以後的物件。即在序列化輸出流寫了兩個物件以後,把這兩個物件對應的位元組塊交換位置,序列化輸出流仍然能讀出這兩個物件。一般而言,如果序列化流是無狀態的,並且在序列化流的開始和結束時不記特殊的後設資料,就會支援這個性質。這個性質JavaSerializer是不支援的,而KryoSerializer有條件支援
private[spark] override lazy val supportsRelocationOfSerializedObjects: Boolean = { newInstance().asInstanceOf[KryoSerializerInstance].getAutoReset() }
PartitionedPairBuffer
private[spark] class PartitionedPairBuffer[K, V](initialCapacity: Int = 64) extends WritablePartitionedPairCollection[K, V] with SizeTracker
它繼承自WritablePartitionedPairCollection以及SizeTracker。底層儲存用一個object陣列。它所儲存的pair,即KV對,Key的型別為(Int, K),即Partition ID和key。
同一個kv對的key和value被放在這個陣列相鄰的位置,和AppendOnlyMap相同。
PartitionedSerializedPairBuffer
它也是儲存了partitionId, key, value這三種資料。
這個buffer的特點是用位元組陣列來儲存資料,而不像其它兩種用object陣列。這就要求它儲存的資料是序列化以後的。它把key和value依次序列化以後依次寫入同一個位元組陣列(實際上是寫入一個ChainedBuffer,ChainedBuffer再寫入到它裡邊的位元組陣列),這就要求有另外的後設資料來區分key和value的邊界。所以PartitionedSerializedBuffer會另外使用一個meta buffer儲存後設資料,這個meta buffer是一個IntBuffer,即一個integer buffer。
這樣它儲存的資料就在兩個buffer裡:kvBuffer, 儲存的是序列化後的key和value; metaBuffer儲存的是關於kvBuffer的後設資料。
其中metaBuffer裡的每個元素是關於一個kv對的後設資料,有4個int,依次是
- keyStart,這是一個long, 用兩個int儲存。指這個kv對在kvBuffer中的起始位置。
- keyValLen, 用一個int儲存。即key和value序列化後,總的長度。
- partitionId, 用一個int儲存。儲存partitionId在metaBuffer裡,使得在kv排序時,直接對metaBuffer按partitionId排序就行了,而kvBuffer不需要變化。
這個buffer只支援按照partition id排序,因此要選它做buffer, ExternalSorter的Ordering引數必須是None。
這個陣列的排序時直接移動底層的位元組,所以要求Serializer必須supportRelcationSerializedObjects。
使用這種buffer的好處是
1. 省記憶體,這由兩原因引起。首先,最主要的因素,它把物件序列化以後儲存,通常會佔用更少的記憶體。其次,它儲存所使用的byte buffer是ChainedBuffer這個類。ChainedBuffer的底層儲存用的是ArrayBuffer[Array[Byte]],這使得它比直接用ArrayBuffer[Byte]更省記憶體,但是ChainedBuffer的實現其表現的像一個位元組陣列。ChainedBuffer中的ArrayBuffer裡的位元組陣列是等長的,稱為一個chunk, ExternalSorter使用spark.shuffle.sort.kvChunkSize來做為chunk的大小,預設為4M。這使得它在ArrayBuffer中儲存的引用佔的大小與整個集合的大小相比,不會太大,也算是比起AppendOnlyMap和PartitionedPairBuffer用object陣列做儲存的一點優勢。
2. 就像PartitionedSerializedPairBuffer所說的。對這個集合排序意味著只需要交換metaBuffer裡的元素,而kvBuffer不需要修改。而metaBuffer排序時是按照partitionId排序,partitionId就儲存在metaBuffer使用的int buffer裡,這意味著獲取partitionId不需要通過引用(而AppendOnlyMap和PartitionedPairBuffer就需要獲得對(partitionId, key)組成的tuple的引用,然後再訪問partitionId),這就最小化了訪問快取時的未命中。所以,對這個buffer內元素的排序的效率會較高。
3. 它的記憶體佔用可以更準確地估計。
實現PartitionedSerailizedPairBuffer還是挺複雜的。PartitionedSerializedPairBuffer雖然繼承了SizeTracker,但是卻沒有使用SizeTracker的estimateSize方法,相反,由於它是使用的基本型別的陣列,因此可以直接計算出自己較準確的大小,所以它覆蓋了SizeTracker的estimateSize方法。
override def estimateSize: Long = metaBuffer.capacity * 4L + kvBuffer.capacity
這明顯比其它兩種buffer對記憶體佔用的估計準確得多。
spill
ExternalSorter繼承了Spillable[WriteablePartitionedPairCollection[K, C]],實現了其spill方法,用來對buffer進行spill。
Spill的時機
為了合理地地在同一個executor的task執行緒間分配用於shuffle的記憶體,shuffle時記憶體buffer的大小向ShuffleMemoryManager申請,以避免過度佔用記憶體,但這個MemoryManager並不實際地控制虛擬機器的記憶體,只是起到限制作用。當buffer擴張需要的記憶體過多,ShuffleMemoryManager分配不了這麼多記憶體時,buffer就會被spill。
Spill的策略
Spill的的策略必須考慮到以後對spill出來檔案的merge。ExternalSorter會寫出唯一一個檔案,因此merge是一定會的。但
是如果需要進行aggregate,那麼spill出來的檔案一定需要按照partition以及key排序,才能用merge sort來對combiner做聚合。但是這樣做的開銷是很大的,首先需要對集合先進行排序,才能寫入檔案(這也是為啥WritablePartitionedPairCollection會定義partitionedDestructiveSortedIterator這個方法),其次在merge檔案時需要先反序列化,然後再把merge完成後的combiner序列化寫入檔案;然後,merge sort本身也會耗費時間。因此,ExternalSorter在某些情況下會按照類似於hash shuffle的方法為每個partition寫一個檔案,每次spill,就把buffer裡的資料按照partition追加到對應的檔案。在需要輸出一整個檔案時,把這些檔案直接連線在一起,這樣就避免了一次反序列化和一次序列化。而之所以能直接把每個partition的檔案相連,而不影響讀取,是因為shuffle的reader一方請求獲得的就是每個partition對應的那部分位元組串,所以reader和writer都是在同樣的位置開啟的輸入流和輸出流,因此外層的壓縮流和序列化流也不會因此而混亂。
但是這樣不好的地方在於如果reducer很多,那麼中間檔案就會非常多,可能會遇到hash shuffle類似的問題(俺並不清楚具體會對效能有多大影響)。所以,有時merge sort的方式還是必須的。這時候,buffer每次spill都寫出一個包括各個partition資料的檔案。然後在merge時,對這些檔案進行merge,採用merge sort的方式。那麼,這兩種spill的方式如何選擇呢?
ExternalSorter用bypassMergeSort這個bool值來做出選擇,如果此值為true,就用第一種方式,否則用第二種方式
private val bypassMergeThreshold = conf.getInt("spark.shuffle.sort.bypassMergeThreshold", 200) private val bypassMergeSort = (numPartitions <= bypassMergeThreshold && aggregator.isEmpty && ordering.isEmpty)
override protected[this] def spill(collection: WritablePartitionedPairCollection[K, C]): Unit = { if (bypassMergeSort) { spillToPartitionFiles(collection) } else { spillToMergeableFile(collection) } }
可見只有在reducer數目不會太多,不需要aggregation 並且不需要進行排序的情況下才會用spillToPartitionFiles。
spillToPartitionFiles
private def spillToPartitionFiles(collection: WritablePartitionedPairCollection[K, C]): Unit = { spillToPartitionFiles(collection.writablePartitionedIterator()) } private def spillToPartitionFiles(iterator: WritablePartitionedIterator): Unit = { assert(bypassMergeSort) // Create our file writers if we haven't done so yet if (partitionWriters == null) { ... } // No need to sort stuff, just write each element out while (iterator.hasNext) { val partitionId = iterator.nextPartition() iterator.writeNext(partitionWriters(partitionId)) } }
所有三種buffer都實現了WritablePartitionedPairCollection介面,因此都可以從它們獲取一個WritablePartitionedIterator,這個迭代器前邊提到過,特點在於可以知道下一個元素的partitiionId, 也可以直接呼叫writeNext把下一個元素寫到BlockObjectWriter裡。而spillToPartitionFiles就是這麼使用它的,它取出迭代器中下一個元素的partitionId, 就能找到對應於這個partition的writer,然後用它來寫入下一個元素。所以,多次spill出來的結果中同樣的partition裡的kv都會被用同樣的writer寫入同一個檔案。
spillToMergeableFile
方法名裡的是File而不像spillToPartitionFiles中是Files,它只會spill到一個檔案。所以這個檔案的內容是排序後的。那麼寫入同一個檔案的問題是需要記錄每個KV屬於哪個partition,否則就需要再用partitioner算一下。由於寫入檔案時,每個partition的kv對記在一起,所以實際只需要記錄下每個partition有多少個KV對就行了。spillToMergableFiles把這個資訊記錄在elementsPerPartition這個資料結構裡
// How many elements we have in each partition val elementsPerPartition = new Array[Long](numPartitions)
另外一個問題與序列化流有關。當通過一個序列化流寫入了大量的物件,它內部的資料結構可能會很多,而且在這個內部資料結構增長時,它可能會進行的拷貝,很大的內部資料結構意味著佔用過多記憶體,對大量資料拷貝意味著時間開銷的增長。因此ExternalSorter通過serializerBatchSize這個引數來控制每次序列化流最多寫入的元素個數。在寫入serializerBatchSize這個元素後,這個序列化流會被關閉,確切地說是writer被關閉,然後重新開啟新的writer繼續往同一個檔案寫。這樣帶來的問題是,整個檔案是多個輸出流的輸出追加在一起的結果,因此需要記錄每個輸出流開始的位置,也就是寫完一個batch的物件後,檔案增長的大小。spillToMergableFiles用batchSizes這個陣列來記錄每個batch的位元組數,在此次spill結束後,這些簿記的資訊被組裝成SpilledFile,它被作為後設資料使用,記在spills這個ArrayBuffer[SpilledFiles]裡。
// List of batch sizes (bytes) in the order they are written to disk val batchSizes = new ArrayBuffer[Long]
private[this] case class SpilledFile( file: File, blockId: BlockId, serializerBatchSizes: Array[Long], elementsPerPartition: Array[Long])
由於這種複雜的寫入方式,對於寫出來的檔案,需要一個特殊的reader,即SpillReader。這個reader的特殊之處在於它可以產生一個特殊的迭代器,這個迭代器的每個元素都是某個partition中kv的迭代器。
def readNextPartition(): Iterator[Product2[K, C]] = new Iterator[Product2[K, C]] { ... }
也就是呼叫readNextPartition返回的迭代器可以迭代這個partition內的所有元素。這樣spillToMergeableFiles的主要邏輯就很清楚了,在原始碼中是這樣的
val it = collection.destructiveSortedWritablePartitionedIterator(comparator) while (it.hasNext) { val partitionId = it.nextPartition() it.writeNext(writer) elementsPerPartition(partitionId) += 1 objectsWritten += 1 if (objectsWritten == serializerBatchSize) { flush() curWriteMetrics = new ShuffleWriteMetrics() writer = blockManager.getDiskWriter( blockId, file, serInstance, fileBufferSize, curWriteMetrics) } }
首先,從buffer中構造一個WritablePartitionedIterator,排序方式使用comparator,
- 如果在ExternalSorter的建構函式中提供了Ordering,就會按Ordering排序
- 如果沒有提供Ordering,但是提供了Aggregator,就會按hashCode排序
- 如果即沒有Ordering,也沒有aggregator,就不排序。
然後把迭代器中的每個元素呼叫it.writeNext寫入writer,在此過程中根據此元素的partitionId,增長elementsPerPartition中對應的partition中的元素數,如果一個writer寫入的元素數到了serializerBatchSize,就呼叫flush,關閉writer,記錄這個batch對應的byte總量到batchSizes,然後建立新的writer。
最後,呼叫
spills.append(SpilledFile(file, blockId, batchSizes.toArray, elementsPerPartition))
來記錄此次spill出來的mergable file的後設資料。
Merge
SortShuffleWriter在呼叫sorter.insertAll(records)把資料寫入sorter之後,會呼叫
val partitionLengths = sorter.writePartitionedFile(blockId, context, outputFile)
生成最後的輸出檔案(這是一整個檔案)。ExternalSorter的writePartitionedFile會spill出來的資料進行merge。這分為三種情況
沒有發生spill
由於記憶體中buffer裡的資料已經進行了aggregate(如果需要的話),所以這種情況的處理邏輯比較簡單。
- 呼叫buffer的destructiveSortedWritablePartitionedIteartor,獲取一個按partition排序的SortedWritablePartitionIterator
- 按partitionId的順序,把同一個partition的內容用同一個writer寫到最終的輸出檔案裡,寫一個partition按一個writer。
- 記錄每個partition的位元組數,簿記到lengths裡
else if (spills.isEmpty && partitionWriters == null) { //說明只有記憶體中的資料,並沒有發生spill // Case where we only have in-memory data val collection = if (aggregator.isDefined) map else buffer val it = collection.destructiveSortedWritablePartitionedIterator(comparator)//獲取SortedWritablePartitionIterator while (it.hasNext) { val writer = blockManager.getDiskWriter(blockId, outputFile, serInstance, fileBufferSize, context.taskMetrics.shuffleWriteMetrics.get) val partitionId = it.nextPartition()//獲取此次while迴圈開始時的partition id while (it.hasNext && it.nextPartition() == partitionId) { it.writeNext(writer) //把與這個partition id相同的資料全寫入 } writer.commitAndClose()//這個writer只用於寫入這個partition的資料,因此當此partition資料寫完後,需要commitAndClose,以使得reader可讀這個檔案段。 val segment = writer.fileSegment() lengths(partitionId) = segment.length//把這個partition對應的檔案裡資料的長度新增到lengths裡 } }
發生了spill, 且使用bypassMergeSort
這也意味著Aggregator和Ordering都沒有。所以不需要聚合,也不需要對partition內部的元素排序。所以直接把每個partition內容依次寫入最終的輸出檔案就行了。
if (bypassMergeSort && partitionWriters != null) { //byPassMergeSort了,所以會用到partitionWriters。如果partitionWriters不為空,就代表著的確寫了些東西。就需要把這些檔案合併。 spillToPartitionFiles(if (aggregator.isDefined) map else buffer) partitionWriters.foreach(_.commitAndClose())//把已有的writer commitAndClose了 val out = new FileOutputStream(outputFile, true)//把所有檔案合併到使用這個檔案輸出流輸出的檔案 val writeStartTime = System.nanoTime util.Utils.tryWithSafeFinally { for (i <- 0 until numPartitions) { val in = new FileInputStream(partitionWriters(i).fileSegment().file)//對於每個writer的輸出檔案,建立一個檔案輸出流 util.Utils.tryWithSafeFinally { //把writer的輸出檔案裡的資料拷貝到最終的檔案裡 lengths(i) = org.apache.spark.util.Utils.copyStream(in, out, false, transferToEnabled) } { in.close() } } } { out.close() context.taskMetrics.shuffleWriteMetrics.foreach( _.incShuffleWriteTime(System.nanoTime - writeStartTime)) } }
發生了spill,並且沒有bypassMergeSort
這時候就需要對spill出來的mergable files以及記憶體中的資料進行merge。ExternalSorter使用partitionedIterator來完成merge,得到一個按partition組合出來的迭代器,它的每個元素都是(partitionId, 這個partition內容的迭代器)這樣的二元組。然後把這個partitionedIterator按partition依次寫到輸出檔案裡就行了。
for ((id, elements) <- this.partitionedIterator) {//merge過程在partitionedIterator方法中 if (elements.hasNext) {//對於這個partition的所有資料,用一個writer寫入 val writer = blockManager.getDiskWriter(blockId, outputFile, serInstance, fileBufferSize, context.taskMetrics.shuffleWriteMetrics.get) for (elem <- elements) { writer.write(elem._1, elem._2) } writer.commitAndClose()//寫完了 val segment = writer.fileSegment() lengths(id) = segment.length//簿記 } }
實際的merge過程發生在this.partitionedIterator這一步,partitionedIterator是ExternalSorter的一個方法
def partitionedIterator: Iterator[(Int, Iterator[Product2[K, C]])]
partitionedIterator的實現和writePartitionedFile一樣,需要考慮同樣的三種情況,所以只有第三種情況才會被呼叫。partitionedIterator處理的三種情況為:
沒有發生spill
由於buffer中的資料是已經aggregate以後的(如果需要的話),所以直接把buffer裡的資料按排序,同樣partition的資料就會到一起,此時簡單地按partition組合一下就行了。只是排序的時候需要考慮是否需要按Ordering來排序。
if (spills.isEmpty && partitionWriters == null) { //只有記憶體中的資料,就按是否有ordering採用不同的排序方式得到迭代器,然後按partition對迭代器中的資料進行組合。 if (!ordering.isDefined) { // The user hasn't requested sorted keys, so only sort by partition ID, not key groupByPartition(collection.partitionedDestructiveSortedIterator(None)) } else { groupByPartition(collection.partitionedDestructiveSortedIterator(Some(keyComparator))) } }
發生了spill, 並且bypassMergeSort
這種情況也很簡單,因為每個分割槽都對應不同的檔案,就直接把這些分割槽在檔案裡的內容和在記憶體中的內容組合起來就行了。
else if (bypassMergeSort) { //否則就代表spill出來檔案了,如果bypassMergeSort就代表著寫出來了一些檔案,每個partition對應一個 // Read data from each partition file and merge it together with the data in memory; // note that there's no ordering or aggregator in this case -- we just partition objects val collIter = groupByPartition(collection.partitionedDestructiveSortedIterator(None))//獲得記憶體中資料的迭代器 //取得spill出來的那些檔案裡為這個partition所寫的檔案,然後和記憶體裡的這個partition的迭代器組合在一起。 collIter.map { case (partitionId, values) => (partitionId, values ++ readPartitionFile(partitionWriters(partitionId))) } }
發生了spill,並且沒有bypassMergeSort
這是最複雜的一種情況,因為此時spill出來的每個檔案裡都有各個分割槽的內容,所以需要進行merge sort,而在merge sort的過程中,可能需要進行aggregation。
ExternalSorter專門有一個merge方法來完成這個工作,所以第三種情況會直接呼叫merge方法。
else { //此時沒有bypassMergeSort,並且spill出來一些檔案。因此需要把它們和記憶體中資料merge在一起,這是最複雜的一種情況。 merge(spills, collection.partitionedDestructiveSortedIterator(comparator)) }
這個merge方法首先為每個spill出來的檔案建立一個reader,然後按partition id的順序,依次從各個reader和記憶體中的迭代器中獲取這個partition對應的那部分迭代器。這樣對於每個partition,都獲得了一組迭代器。merge方法對每個partition對應的那些迭代器進行merge。
又根據ExternalSorter是否有Aggregator和Ordering的情況,分成三種處理邏輯
1. 需要聚合,此時會呼叫mergeWithAggregation方法來邊merge邊做aggregate
2. 不需要聚合,並且提供了Ordering。這時候直接mergeSort就行了
3. 不需要聚合,並且沒有提供Ordering,這時候就直接把每個partition對應的那組迭代器裡的元素組合在一起就行了,會直接用Iterator的flatten方法
private def merge(spills: Seq[SpilledFile], inMemory: Iterator[((Int, K), C)]) : Iterator[(Int, Iterator[Product2[K, C]])] = { val readers = spills.map(new SpillReader(_))//為每個spill出來的檔案生成一個reader val inMemBuffered = inMemory.buffered//記憶體中的迭代器進行buffered,以方便檢視其head的資訊 (0 until numPartitions).iterator.map { p => //對每一個partition val inMemIterator = new IteratorForPartition(p, inMemBuffered)//對記憶體中的資料獲取這個partition對應的iterator val iterators = readers.map(_.readNextPartition()) ++ Seq(inMemIterator)//把檔案資料的迭代器和記憶體資料的迭代器都放在一個seq裡 if (aggregator.isDefined) {//如果需要聚合的話 // Perform partial aggregation across partitions 對這個partition對應的那些iterator進行merge,並且聚合資料 (p, mergeWithAggregation( iterators, aggregator.get.mergeCombiners, keyComparator, ordering.isDefined)) } else if (ordering.isDefined) { // No aggregator given, but we have an ordering (e.g. used by reduce tasks in sortByKey); // sort the elements without trying to merge them (p, mergeSort(iterators, ordering.get)) } else { (p, iterators.iterator.flatten) } } }
merge方法
mergeWithAggregation
這會邊merge,邊做aggregation。根據傳進去的iterators是否是按照Ordering排序的,分為兩種:
1. 非totalOrder
這是最複雜的一種情況。非totalOrder,說明了這些迭代器中一個partition內部的元素實際是按照hash code排序的。所以即使key1==key2,但是key1和key2之間可能有key3, 它只是與key1和key2有相同的雜湊碼,但==號並不成立。它所要處理的問題和hash shuffle的ExternalAppendOnlyMap是類似的,但演算法並不相同。ExternalSorter裡的演算法複雜度更低一些,但實際執行時的情況跟互不相等的key的hash code的衝突程度有關。ExternalAppendOnlyMap是基於PriorityQueue做的,而ExternalSorter裡的演算法是使用兩個buffer完成的,後者充分利用了“==不成立的元素不可能有相同的hash code”這個條件,把相同hash code的元素都取出來,對這些元素用兩個buffer做聚合。
if (!totalOrder) { // We only have a partial ordering, e.g. comparing the keys by hash code, which means that // multiple distinct keys might be treated as equal by the ordering. To deal with this, we // need to read all keys considered equal by the ordering at once and compare them. new Iterator[Iterator[Product2[K, C]]] { val sorted = mergeSort(iterators, comparator).buffered//先按comparator進行merge sort,不aggregate // Buffers reused across elements to decrease memory allocation val keys = new ArrayBuffer[K] //存放compare為0,但又相到不==的所有key val combiners = new ArrayBuffer[C]//存放keys中對應位置的key對應的所有combiner聚合後的結果 override def hasNext: Boolean = sorted.hasNext override def next(): Iterator[Product2[K, C]] = { if (!hasNext) { throw new NoSuchElementException } keys.clear() combiners.clear() val firstPair = sorted.next()//獲取排序後iterator的第一個pair keys += firstPair._1//第一個pair的key放在keys裡 combiners += firstPair._2 //第一個pair的combiner放在combiners裡 val key = firstPair._1//第一個pair的key while (sorted.hasNext && comparator.compare(sorted.head._1, key) == 0) { //獲取sorted中跟前key compare以後為0的下一個kv。注意,compare為0不一定 ==號成立 val pair = sorted.next() var i = 0 var foundKey = false while (i < keys.size && !foundKey) { if (keys(i) == pair._1) {//用當前取出的這個kc的key與keys中key依次比較,找到一個==的,就對combiner進行aggregate,然後結果放在combiners // 裡,並且結束迴圈 combiners(i) = mergeCombiners(combiners(i), pair._2) foundKey = true } i += 1 } //如果這個kc裡的key與keys裡所有key都不==,意味著它與它當前快取的所有keycompare為0但不==,所以它是一個新的key,就放在keys裡,它的combiner放在combiners裡 if (!foundKey) { keys += pair._1 combiners += pair._2 } } // Note that we return an iterator of elements since we could've had many keys marked // equal by the partial order; we flatten this below to get a flat iterator of (K, C). keys.iterator.zip(combiners.iterator) //把keys和combiners 進行zip,得到iterator of (K, C) } }.flatMap(i => i) //flatMap之前是Iteator[compare為0的所有kc聚合而成的Iteator[K, C]], 所以直接flatMap(i => i)就成了 }
2.totalOrder
此時對這些迭代器先用comparator進行merge sort, 得到的merge後的迭代器裡所有==號成立的key就都挨在一起了。所以接下來只需要直接按==號把迭代器劃分,然後進行aggregate就行了。
else { //因為是total ordering的,意味著用Ordering排序,所以==的key是挨在一起的 // We have a total ordering, so the objects with the same key are sequential. new Iterator[Product2[K, C]] { val sorted = mergeSort(iterators, comparator).buffered override def hasNext: Boolean = sorted.hasNext override def next(): Product2[K, C] = { if (!hasNext) { throw new NoSuchElementException } val elem = sorted.next() val k = elem._1 var c = elem._2 while (sorted.hasNext && sorted.head._1 == k) { //取出所有==的kc,進行merge val pair = sorted.next() c = mergeCombiners(c, pair._2) } (k, c) } } }
總結
ExternalSorter就Spark的sort-based shuffle的核心,它整個檔案有800多行,雖然其演算法不太複雜,還是由於要處理各種情況,以及進行相關的優化,其實現還是很繁瑣的。它的複雜性主要來源於以下幾個方面:
- 需要控制記憶體消耗,所以需要spill以及merge
- 在spill和merge過程中需要考慮到Aggregator和Ordering的不同情況
- 需要為每個partition使用一個輸出流,因此有一些輸出流的切換和簿記工作。
此外,為了提高效率,它根據特殊情況使用了PartitonedSerializedPairBuffer、byPassMergeSort等優化手段。
在它的實現中,大量使用了迭代器。
1. 使用了大量迭代器的基本操作,如map、flatmap、flatten、filter、zip。
2. 為各種集合生成了特殊的迭代器。主要是WritableParitionedPariCollection中定義的三種獲取特殊迭代器的方法:partitionedDestructiveSortedIterator, destructiveSortedWritablePartitionedIterator, writablePartitionedIterator
3. 大量使用了迭代器的包裝。比如Scala的BufferedIterator, mergeSort和mergeWithAggregation中的包裝了另一個迭代器的匿名迭代器(new Iterator{...}), IteratorForPartition。
而且它所使用的三種buffer的設計,以及merge的演算法也是值得看一下的。
不過shuffle絕對是Spark程式的效能殺手。每個元素都要經過如此複雜的處理,所以shuffle的總的效能開銷還是挺大的,但這也意味著對shuffle的過程進行優化可以對效能有較大的提升。俺認為,一方面,可以優化自己的程式,包括儘量避免shuffle、減少需要shuffle中需要IO的資料量(各種使kv、kc序列化後變得更小的方法,使用map-side combiner)、選擇合適的shuffle配置引數等;另一方面,Spark框架本身的shuffle的實現也還有優化的空間,比如對記憶體佔用更準確地估計,根據被shuffle的資料的特點區分不同情況以採用更細緻的策略(比如實現shuffle專用的各種特殊集合, 考慮到shuffle特點的序列化方法等)。