【編者按】作為國內搜尋巨頭,百度收錄全世界超過一萬億的網頁,每天響應中國網民大約幾十億次的請求。那麼,在面對如此龐大的資料處理時,百度是如何構建並優化分散式計算平臺,又如何完成一次次系統構架的演進呢?在“OneAPM 技術公開課”中,百度的基礎架構部高階技術經理朱冠胤根據自己的實踐經歷,對以上問題進行了詳細闡述。
以下為演講整理:
大家好! 我來自百度開放雲大資料團隊,2008年1月加入百度,一直在從事大資料分析和挖掘相關工作。目前我們將服務百度內部核心業務多年的Hadoop服務BMR(BaiduMapReduce)、大規模機器學習服務BML(Baidu MachineLearning)等正式對外開放。接下來我就跟大家分享一下BMR和BML為代表的百度大資料分析和挖掘平臺演進歷程以及在該領域的最新思考。
其實,如果涉及到“大資料”,不得不提百度最大的業務——搜尋。百度搜尋已經收錄全世界超過一萬億的網頁,每天響應中國網民大約幾十億次的請求。除此之外,百度還有另外20多個使用者過億的產品線,而且各個產品底層的大規模資料處理,都需要使用我們團隊維護的大資料處理平臺。

關於MapReduce
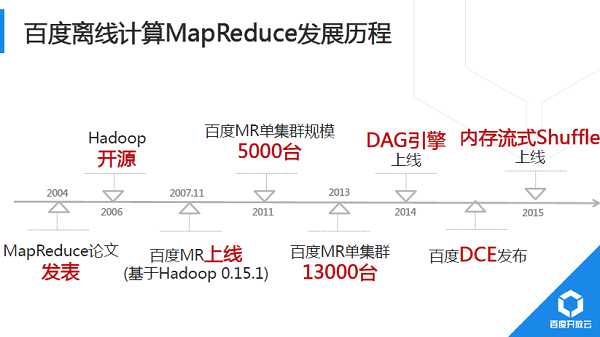
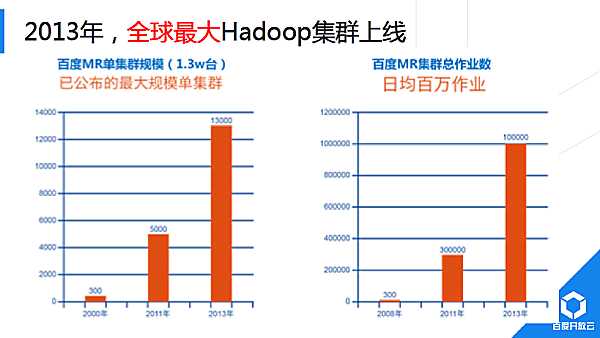
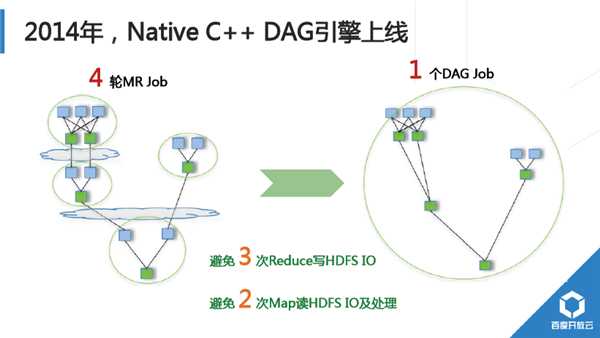
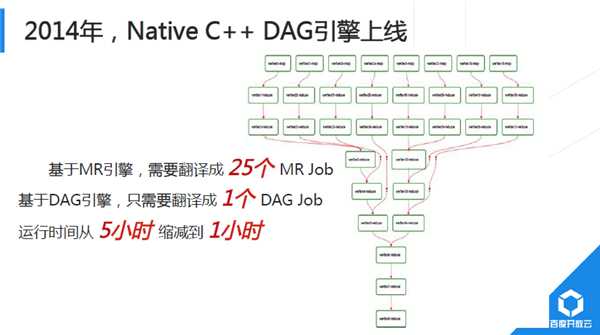
2014年,我們對Shuffle進行重大重構,初期實習生同學完成的Demo以BaiduSort名義參與了2014年Sort BenchMark大資料排序國際大賽,並獲得冠軍(2015年百度沒再參加,國內其他公司以同樣技術通過更大規模叢集重新整理記錄)。2015年,新Shuffle技術完成全面上線。Hadoop預設Shuffle實現為基於磁碟Pull模式,計算過程顯式分成Map、Shuffle、Reduce過程;Baidu研發的新Shuffle採用記憶體流式Push模式,Map端完成部分記錄處理後直接從記憶體中將計算結果推送給下游。
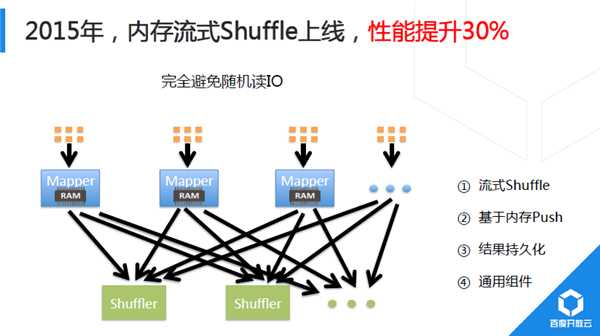
目前,該Shuffle元件為通用元件,正逐步推廣到其他分散式計算平臺中。
百度分散式計算平臺:系統架構演進
前面重點介紹了百度開放雲BMR服務中涉及到的規模、效能方面優化思路和效果,接下來跟大家一起分享一下,我們遇到的整體架構方面挑戰以及優化思路。
2012年系統架構中,最主要的兩個離線計算平臺,左邊是以MapReduce模型為主的批量計算平臺BMR,右邊是MPI /BSP模型為主的大規模機器學習平臺BML。從最下面可以看到,MapReduce和MPI模型底層硬體就有較大差異。Hadoop分散式檔案系統多副本以及強大的故障處理機制,使得Raid卡完全沒有必要,採用多塊超大容量SATA硬碟非常適合。
而MPI差別較大,MPI是一個訊息傳輸框架,它在設計之初就沒有考慮太多異常處理,因此它對底層系統可靠性要求非常高。百度採用了非常高配置的伺服器,例如帶Raid卡的sas硬碟,超大記憶體、萬兆互聯等。

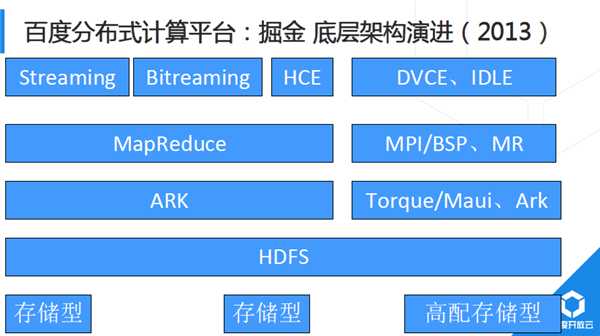
另外還有一個需求:MPI是一種事務性排程模型,比如一個業務需要200臺機器,如果平臺此時只有199臺機器空閒,實際也很難用起來(除非修改提交引數,但涉及輸入資料重新分塊處理等比較複雜)。另外MPI計算往往顯式分為計算、傳輸、計算等階段(即BSP模型),因此資源利用波動性較大,例如CPU計算階段,網路空閒;網路傳輸或全域性同步階段,CPU空閒。為解決這個問題,我們在MPI叢集中引入IDLE計算,IDLE業務資源佔用充分可控,典型的IDLE任務如MapReduce任務,而執行MR任務又會進一步加劇MR叢集和MPI叢集間網路頻寬問題。
基於以上考慮,我們正式講MPI底層硬體替換為替換成高配置儲存型伺服器,硬碟同構,檔案系統都採用HDFS,BML演算法輸入和輸出均通過HDFS,不再是本地檔案系統。
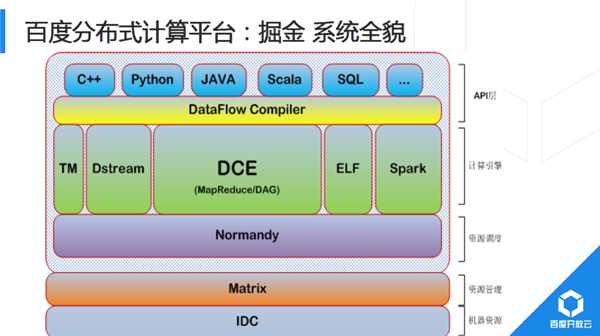
BML機器學習執行引擎層面,我們基於MPI封裝了DVCE(Distributed VectorComputingEngine)分散式向量計算引擎,遮蔽MPI過於低層的程式設計介面,通過高層抽象自動翻譯為MPI任務,這就是百度第二代專門針對“平行計算”開發的系統框架。

2014年BMR和BML底層都採用Matrix完成資源分配與隔離,其他平臺如小批量計算系統TaskManager和毫秒級計算延遲的Dstream系統,都基於業務需求特殊性,採用獨立的資源隔離和排程系統。
2015年的架構改進,主要是將所有的計算模型均遷移到Matrix+Normandy架構。Normandy相容社群Yarn排程介面,開源社群新型興計算平臺可以很輕鬆的接入到百度的計算生態裡。

系統底層是IDC硬體,接著是Matrix,再是Normandy,然後是幾個主要的引擎。之前介紹底層架構的統一,比如在硬體、排程、儲存等方面的統一。實際上各個系統對外的結果,都有自己的介面,如果要使用MR,很多人寫MR程式都是直接呼叫Hadoop原生介面,配置涉及到的多個引數。部分業務還需要流式系統完成日誌清洗,在經過MapReduce模型批量預處理,隨後通過ELF完成機器學習模型訓練,最後再通過MapReduce模型完成模型評估,可見一個業務需要跨越多個模型,需要業務線同學同時熟悉很多模型和平臺,而每一個模型又有各自特點和介面。只有足夠了解模型的細節和介面後,才能真正的利用好該模型。
百度開放雲——大資料+智慧
最後,向大家簡要介紹百度開放雲。2014年,百度正式決定將服務內部業務多年的雲端計算技術正式對外提供服務,即百度開放雲,對應官網http://cloud.baidu.com。百度開放雲大資料方面,BMR已經對外開放,而更多的大資料分析和服務都還未對外開放。BMR叢集上可以做到按需部署,使用者專享,更關鍵的是完全相容開源的Hadoop/Spark平臺,開放雲客戶基於Hadoop、Spark、Hbase等已經實現的大資料業務幾乎不用修改就可以平滑遷移到雲上。多維分析服務Palo,它完全相容MySQL網路協議,因此,客戶朋友們熟悉的Mysql Client的工具均可使用。

最後再介紹機器學習雲服務BML,BML中提供的深度學習技術,曾獲得2014年百度最高獎。BML提供端到端的解決方案,裡面提供的演算法均服務百度內部業務多年,典型如網頁搜尋、百度推廣(鳳巢、網盟CTR預估等)、百度地圖、百度翻譯等。
使用開放雲BMR和BML、Palo等,就可以立刻、直接享用與百度搜尋同等品質的大資料分析和挖掘服務!

關於朱冠胤:
•2008年碩士畢業於北郵,現任百度開放雲大資料負責人,基礎架構部高階技術經理;
•2008年1月加入百度實習,作為國內首批Hadoop研發工程師之一,參與了百度Hadoop平臺從無到單叢集全球最大整個過程;
•2009年開始作為負責人開始從無到有建設百度大規模機器學習平臺,陸續參與了鳳巢CTR預估、網盟CTR預估、大搜尋PageRank、機器翻譯等核心機器學習專案。2014年8月,與其他部門聯合研發的深度學習平臺獲百度最高獎;
•2015年8年,帶領團隊完成的智慧服務排程系統-Normandy獲得百度最高獎;
•目前主要負責百度開放雲大資料產品研發和推廣,已上線國內首個雲端全託管的Hadoop/Spark服務BMR,國內首個機器學習雲服務BML等;
•關注領域主要是大資料分析和挖掘技術,包括但不限於Hadoop/Spark、深度學習等。
來源:CSDN