1)H5頁面的一秒法則;
2)啟動時間和頁面幀率提升20%;
3)Android記憶體佔用降低50%。
優化過程中遇到的困難,思考後找尋的方案,實施後提取的經驗將會在下面這篇文章中詳細地介紹給大家。
“1S法則”是面向Web側,H5鏈路上載入效能和體驗方向上的一個指標,具體指:
- “強網”(4G/WIFI)下,1秒完全完成頁面載入,包括首屏資源,可看亦可用;
- 3G下1秒完成首包的返回
- 2G下1秒完成建連。
在行動網路環境下,http請求和資源載入與有線網路或者PC時代相比有著本質區別,尤其是在2G/3G網路下,往往一個資源請求建連的時間都會是整個Request-Response流程裡面的大頭,一些小資源上拖累效應尤其明顯。例如一個1k的圖片,即使在10k/s 的極慢網速下,理論上0.1秒可下載完畢,但由於建立連線的巨大消耗,這樣一個請求會要耗上好幾秒。
僅僅“建連”這一個點,就能說明移動時代的Web側效能優化和PC時代目標和方式都相去甚遠,要求我們必須從更底層,更細緻的去抓,才能取得看起來相對有效的結果。
15年初的效能情況
| 平均LoadTime-WIFI | 平均LoadTime – 4G | 平均LoadTime – 2G |
| 3.35s | 3.84s | 14.34s |
可以看到優化前,平均時間很難接近1秒。為了實現優化目標,在技術和實施抓手層面,由底層往上,做了四方面事情:
- 網路節點:HttpDNS優化
- 建連複用:SSL化,SPDY建連高複用
- 容器層面:離線化和預載入方案
- 前端元件:請求控制,域名收斂,圖片庫,前端效能CheckList
DNS解析想必大家都知道,在傳統PC時代DNS Lookup基本在幾十ms內。而我們通過大量的資料採集和真實網路抓包分析(存在DNS解析的請求),DNS的消耗相當可觀,2G網路大量5-10s,3G網路平均也要3-5s。
針對這種情況,手淘開發了一套HttpDNS-面向無線端的域名解析服務,與傳統走UDP協議的DNS不同,HttpDNS基於HTTP協議。基於HTTP的域名解析,減少域名解析部分的時間並解決DNS劫持的問題。
手淘HttpDNS服務在啟動的時候就會對白名單的域名進行域名解析,返回對應服務的最近IP(各運營商),埠號,協議型別,心跳等資訊。
優點
1.防止域名劫持
傳統DNS由Local DNS解析域名,不同運營商的Local DNS有不同的策略,某些Local DNS可能會劫持特定的域名。採用HttpDNS能夠繞過Local DNS,避免被劫持;另外,HttpDNS的解析結果包含HMAC校驗,也能夠防止解析結果被中間網路裝置篡改。
2.更精準的排程
對域名解析而言,尤其是CDN域名,解析得到的IP應該更靠近客戶端的地區和運營商,這樣才能有更快的網路訪問速度。然而,由於運營商策略的多樣性,其推送的Local DNS可能和客戶端不在同一個地區,這時得到的解析結果可能不是最優的。HttpDNS能夠得到客戶端的出口閘道器IP,從而能夠更準確地判斷客戶端的地區和運營商,得到更精準的解析結果。
3.更小的解析延遲和波動
在2G/3G這種行動網路下,DNS解析的延遲和波動都比較大。就單次解析請求而言,HttpDNS不會比傳統的DNS更快,但通過HttpDNS客戶端SDK的配合,總體而言,能夠顯著降低解析延遲和波動。HttpDNS客戶端SDK有幾個特性:預解析、多域名解析、TTL快取和非同步請求。
4.額外的域名相關資訊
傳統DNS的解析結果只有ip,HttpDNS的解析結果採用JSON格式,除了ip外,還支援其它域名相關的資訊,比如埠、spdy協議等。利用這些額外的資訊,APP可以啟用或停止某個功能,甚至利用HttpDNS來做灰度釋出,通過HttpDNS控制灰度的比例。
出於安全目的,淘寶實現了全站SSL化。本身和H5鏈路效能優化沒有直接的關係,但是從資料層面看,SSL化之後的資源載入耗時都會略優於普通的Http連線。
有讀者會有疑惑,SSL化之後每個域名首次請求會額外增加一個“SSL握手”的時間,DNS建連也會比http的狀態下要長,這是不可避免的,但是為什麼一次完整的RequestRespone 流程耗時會比http狀態下短呢?
合理的解釋是:SSL化之後,SPDY可以預設開啟,SPDY協議下的傳輸效率和建連複用效益將最大化。SPDY協議下,資源併發請求數將不再受瀏覽器webview的併發請求數量限制,併發100+都是可能的。
同時,在保證了域名收斂之後,同樣域名下的資源請求將可以完全複用第一次的DNS建連和SSL握手,所以,僅在第一次消耗的時間完全可以被SPDY後續帶來的資源傳輸效率,併發能力,以及連線複用度帶來的收益補回來。甚至理論上,越複雜的頁面,資源越多的情況,SSL化+SPDY之後在效能上帶來的收益越大。
收益最明顯,實現中遇到困難最多的就是離線化或者說資源預載入的方案。預載入方案是為了在使用者訪問H5之前,將頁面靜態資源(HTML/JS/CSS/IMG…)打包預載入到客戶端;使用者訪問H5時,將網路IO攔截並替換為本地檔案IO;從而實現H5載入效能的大幅度提升。 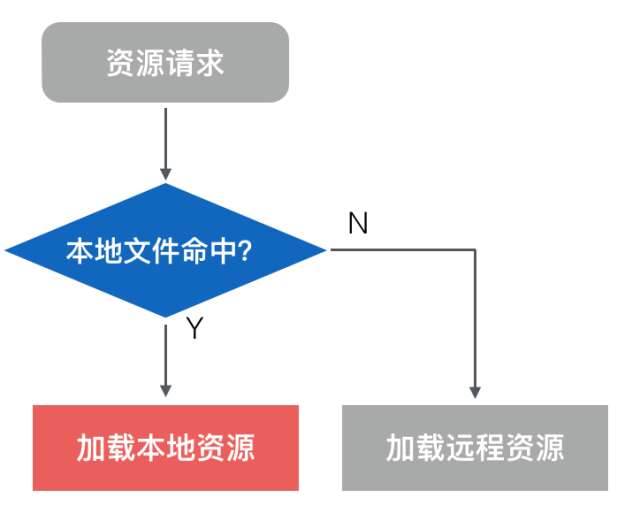
手淘實現要比上面的通用示意圖複雜:因為Android和iOS安裝包已經很大,所以預載入Zip包(以下簡稱“包”)都是從伺服器端下載到客戶端;本地需要記錄整體包狀態,並在合適的時機與伺服器通訊並交換狀態資訊。在包釋出更新的過程中要注意,本地版本和服務端最新包之間的差量同步,必要的網路判斷,WiFi下才下載等。
面對億級UV,並且在伺服器資源很有限的情況下搞定這個流程,需要藉助CDN來扛住壓力,實際上CDN扛住了約98%的流量。需要注意的是預載入實際上也是一種快取,更新比H5稍慢一些,主要受幾個因素影響:推送到達率(使用者是否線上,使用者所在網路質量),總控,服務端策略等,所以需要通過推拉結合的觸發策略並優化下載包的體積(增量包)來提升到達率。
除了優化到達率,手淘還做了url解CDN Combo後再對映的優化工作,若 URL 是 Combo URL,那麼會對 URL 解 Combo,解析出其中包含的資源。然後嘗試從本地讀取包含的資源,如果所有資源都在本地存在,那麼將本地檔案內容拼裝為一份完整檔案並返回;否則 URL 直接走線上,不做任何操作。
提升到達率和解CDN Combo再對映,這兩個容器側對於離線化方案的優化對於本次H5鏈路上整體效能的提升有著至關重要的意義。
嚴格執行效能方面的CheckList,主要有三個點:
- 圖片資源域名全部收斂到gw.alicdn.com;
- 前端圖片庫根據強弱網和裝置解析度做適配;
- 首屏資料合併請求為一個。
在執行中,效能的檢查和校驗一定要納入到釋出階段,否則就不是一個合理的流程。效能的工具和校驗一定應該是工程化,研發流程裡面的一部分,才能夠保障效能自動化,低成本,不退化。
通過以上優化方案,H5頁面的平均Loadtime在Wifi,4G下均如期進入1秒,3G和2G也有80%多達成1s法則的目標。
很多App都會遇到以下幾個常見的效能問題:啟動速度慢;介面跳轉慢;事件響應慢;滑動和動畫卡頓。
手機淘寶也不例外。我們分為兩部分來做,第一部分是啟動階段優化,目的解決啟動任務繁多,缺乏管控的問題,減少啟動和首頁響應時間。第二部分是針對各個介面做優化,提升介面跳轉時間和滑動幀率,解決卡頓問題。雙十一效能優化目標之一就是將啟動時間和頁面幀率在原有基礎上繼續優化提升20%,接下來就從這兩部分的優化過程來做一一介紹。
手機淘寶作為阿里無線的航母,接入的業務Bundle超過100個,啟動初始化任務超過30個,這些任務缺少管控和效能監控。
那麼首要任務就是:
建立任務管理機制
所有的初始化任務可以用兩個維度來區分:
- 任務必要性:有些任務是應用啟動所必需的,比如網路、主容器;有些任務則不是必需的,僅僅實現單個業務功能,甚至是為了業務自身體驗和效能而考慮在啟動階段提前執行,其合理性值得推敲。
- 任務獨立性:將應用的架構簡單分成基礎庫、中介軟體、業務三層,這三層中業務層最為龐大,其初始化任務也最多。對於中介軟體來說,其初始化可能依賴於另外一箇中介軟體。但對於一個獨立的業務模組來說,其初始化任務應該也具有獨立性,不存在跟其他業務模組依賴關係。
啟動階段任務管理機制包含了如下幾方面的內容
- 任務可並行
既然很多初始化任務是獨立的,那麼並行執行可以提高啟動效率。
- 任務可序列
雖然我們期望所有初始化任務都相互獨立,但是在實際中不可避免會存在相互依賴的初始化任務。為了支援這種情況,我們設計任務的非同步序列機制,這裡主要借鑑了前端的Promise思想實現。
- 任務可插拔
面對這麼多不同優先順序的初始化任務,任何一個出現異常都會導致應用不能啟動,給穩定性帶來嚴重挑戰。因此我們設計了可插拔機制,當某一項初始化任務出現問題時能夠跳過該任務,從而不影響整個應用的啟動使用。這裡我們根據初始化任務的必要性做了區分,只有非必要的初始化任務才會應用可插拔的特性,這也是為了防止出現不執行一個必要的初始化任務導致應用啟動使用出現問題。
- 任務可配置
在ios上通過plist指定每一項啟動任務, 其中欄位optional表示該項是否是必需的,當之前執行出現crash或者異常時,若值為YES則可以不執行該項。
有了任務管理機制,並引入懶載入的理念,可以持續地合理有效管控啟動階段的各項初始化任務,是大型app必不可少的環節。
檢測超時方法,優化主執行緒
效能優化前,初始化程式碼都在主執行緒中執行,為了啟動效能已將部分初始化任務放入後臺執行緒或者非同步執行。但是隨著手淘業務發展和人員變更,還是出現了在主執行緒中執行很重的初始化任務。為此,在ios實現了一套應用執行時方法耗時檢測機制,能夠對應用中所有類的方法呼叫做耗時統計。方便的找到超時的方法呼叫之後,就可以有針對性的做出修改,或刪除或非同步化。這種方法呼叫耗時檢測機制同樣適用於APP執行過程中,從而找到導致應用卡頓的根本原因,最後做出對應修改。
多執行緒治理
分析各個模組的執行緒數量,檢查執行緒池的合理性。通過去掉不必要的執行緒和執行緒池,再控制執行緒池的併發數和優先順序。進一步通過框架層的執行緒池來接管業務方的執行緒使用,以減少執行緒太多的問題。
減少IO讀寫
從自身業務出發,去除若干初始化階段不必要的檔案操作,以及將若干非實時性要求的檔案操作延後處理。Android上對於頻繁讀寫資料庫和SharedPreference以及檔案的模組,通過增加快取和降低取樣率等手段減少對IO的讀寫。對於SharedPreference進行了專門的優化,減少單個檔案的大小,將毫無聯絡的儲存鍵值分開到不同檔案中,並且防止將大資料塊儲存到SharedPreference中,這樣既不利於效能也不利於記憶體,因為SharedPreference會有額外的一份快取長期存在。
降級部分功能
例如搖一搖功能,測試發現應用場景不頻密,但業務使用了高頻率的遊戲模式,會耗電及佔用主執行緒時間。對該功能做了降級處理,降低檢測頻率。同理,對於其他非必須使用但又佔據較多資源的模組也都做了適當的降級處理。
熱啟動時間的縮短
在安卓手機上我們把啟動分為兩類進行檢測和優化:冷啟動和熱啟動。冷啟動是程式程式不存在的情況下啟動,熱啟動是指使用者將程式切換到後臺或者不斷按Back鍵退出程式,實際程式還存在的情況下點選圖示執行。
之前安卓手淘在按Back鍵退出時整個首頁Activity銷燬了,熱啟動會經過一個比較長的過程。優化後首頁在退出的時候並不銷燬Activity,但是會釋放圖片等主要資源,在下次熱啟動時就能更快的進入。另外,將手淘歡迎頁的介面從其它bundle轉移到首頁的模組,在進入歡迎頁時就開始初始化首頁資源,做到更快展示。
在經過一系列的優化後,啟動方面已經有了明顯的改善,在進入首頁的時候不會卡頓,GC次數也減少了一半以上。
各介面優化我們也是圍繞著提高幀率和加快展現而展開的,手淘的幾個主鏈路介面,都是相對比較複雜的,既使用多圖,也使用了動態模板的技術。功能越複雜,也越容易產生效能問題,所以常遇到佈局複雜、過渡繪製多、Activity主要函式耗時、內容展示慢、介面重新佈局(Layout)、GC次數多等問題。
優化GPU的過渡繪製
通過開發者選項的GPU過渡繪製選項檢查介面的過渡繪製情況。該優化並不複雜,通過去掉層疊佈局中多餘的背景設定、圖片控制元件有前景內容的時候不顯示背景、介面背景定義到Activity的主題中、減少Drawable的複雜Shape使用等手段就可以基本消除過渡繪製,減少對GPU和CPU的浪費。
優化層級和佈局
層級越多,測量和佈局的時間就會相應增加,建立硬體列表的時間也會相應增加。有時我們會巢狀很多佈局來實現原本只要簡單佈局就可以實現的功能,有時還會新增一些測試階段才會使用的佈局。通過刪除無用的層級,使用Merge標籤或者ViewStub標籤來優化整個佈局效能。比如一些顯示錯誤介面、載入提示框介面等,不是必須顯示的這些佈局可以使用ViewStub標籤來提升效能。
另外要靈活使用佈局,並不是層級越多就會效能越差,有時候1層的RelativeLayout會比3層巢狀的LinearLayout實現的效能更糟糕。
除了靈活使用佈局,另外我們還通過提前inflate以及線上程中做一些必要的inflate等來提前初始化佈局,減少實際顯示時候的耗時。對於一些複雜的佈局,我們還會自己做複用池,減少inflate帶來的效能損耗,特別是在列表中。
加快介面顯示
- 可以通過TraceView工具找出主執行緒的耗時操作和其他耗時的執行緒並作優化。另外減少主執行緒的GC停頓,因為即使並行GC,也會對heap加鎖,如果主執行緒請求分配記憶體的話,也會被掛起,所以儘量避免在主執行緒分配較多物件和較大的物件,特別是在onDraw等函式中,以減少被掛起的時間。另外可以通過去掉ListView ,ScrollView等控制元件的EdgeEffect效果,來減少記憶體分配和加快控制元件的建立時間。
- 利用本地快取,主要介面快取上次的資料,並且配合增量的更新和刪除,可以做到資料和服務端同步,這樣可以直接展示本地資料,不用等到網路返回資料。
- 減少不必要的資料協議欄位,減少名字長度等,並作壓縮。還可以通過分頁載入資料來加快傳輸解析時間。因為JSON越大,傳輸和解析時間也會越久,引發的記憶體物件分配也會越多。
- 注意執行緒的優先順序,對於佔用CPU較多時間的函式,也要判斷執行緒的優先順序。
優化動畫細節
通過TraceView工具發現,一些Banner輪播廣告和文字動畫在移出可視區域後,仍然存在定時重新整理,不僅耗電也影響幀率。優化措施是在移出可視區域後停止動畫輪播。
阻斷多餘requestLayout
在ListView滑動,廣告動畫變化等過程中,圖片和文字有變化,經常會發現整個介面被重新佈局,影響了效能。尤其佈局複雜時,測量過程很費時導致明顯示卡頓。對於大小基本固定的控制元件和佈局例如TextView,ImageView來說,這是多餘的損耗。我們可以用自定義控制元件來阻斷,重寫方法requestLayout、onSizeChanged,如果大小沒有變化就阻斷這次請求。對於ViewPager等廣告條,可以設定快取子view的數量為廣告的數量。
優化中介軟體
中介軟體的程式碼被上層業務方呼叫的比較頻繁,容易有較多的高頻率函式,也容易產生細節上的問題。除了頻繁分配物件外,例如類初始化效能,同步鎖的額外開銷,介面的呼叫時間,列舉的使用等等都是不能忽視的問題。
減少GC次數
安卓上的GC會引起效能卡頓,必須重點優化。除了第三章會詳細介紹對於圖片記憶體引起GC的優化,我們還做了如下工作:
- 減少物件分配,找出不必要的物件分配,如可以使用非包裝型別的時候,使用了包裝型別;字串的+號和擴容;Handler.post(Runnable r)等頻繁使用。
- 物件的複用,對於頻繁分配的物件需要使用複用池。
- 儘早釋放無用物件的引用,特別是大物件和集合物件,通過置為NULL,及時回收。
- 防止洩露,除了最基本的檔案、流、資料庫、網路訪問等都要記得關閉以及unRegister自己註冊的一些事件外,還要儘量少的使用靜態變數和單例。
- 控制finalize方法的使用,在高頻率函式中使用重寫了finalize的類,會加重GC負擔,使得效能上有幾倍的差別。
- 合理選擇容器,在效能上優先考慮陣列,即使我們現在習慣了使用容器,也要注意頻繁使用容器在效能上的隱患點:首先是擴容開銷, HashMap擴容時重新Hash的開銷較大。其次是記憶體開銷,HashMap需要額外的Map.Entry物件分配 ,需要額外記憶體,也容易產生更多的記憶體碎片。SparseArray和ArrayList等在記憶體方面更有優勢。再次是遍歷,對於實現了RandomAccess介面的容器如ArryList的遍歷,不應該使用foreach迴圈。
- 用工具監控和精雕細琢:在頁面滑動過程中,通過Memory Monitor檢視記憶體波動和GC情況,還可通過AlloCation Tracker工具觀察記憶體的分配,發現很多小物件的分配問題。
- 利用Trace For OpenGL工具找出介面上導致硬體加速耗時的點,例如一些圓角圖片的處理等。
通過多種工具和手段配合,手淘各個介面效能上有了較大的提高,平均幀率提高了20%,那麼記憶體節省50%又是如何實現的哩,請看下文。
Android上應用出現卡頓的核心原因之一是主執行緒完成繪製的週期過長引起丟幀。而影響主執行緒完成繪製時間的主要有兩方面,一方面是主執行緒處於執行狀態時需要做的任務太多但CPU資源有限,另外一方面是GC時Suspend時直接掛起了所有執行緒包括主執行緒。GC對總體效能的影響在4.x的系統上尤為突出,一部分是單次GC pause總時長,一部分是使用者操作過程中GC發生的次數。而決定這兩部分的因素就是Dalvik記憶體分配。那麼在手淘這樣的大型應用中到底是誰佔用了記憶體大頭呢?
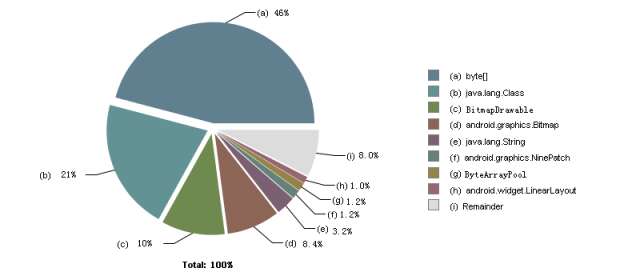
基於雙11前的手淘Android版本,我們在魅藍note1(4.4 OS)上滑動完首頁後,dump出其Dalvik Heap,整體記憶體佔用的分佈情況如下圖。可以看出,byte陣列(a)佔用空間最大,絕大多數是用來存放Bitmap的畫素資料(Pixel Data)。另外(c)與(d)一起佔用了18.4%, byte陣列加上Bitmap、BitmapDrawable總共佔用了64.4%,成為記憶體佔用的主體。
這也從側面說明了手淘是以圖片為瀏覽主體內容的大型應用。而往往圖片需要較大的記憶體塊,在分配時引起GC的可能性也往往最大。那我們能不能將圖片這部分需要的記憶體移走而不在Dalvik Heap分配呢?如果能,那麼不單GC會明顯減少,同時Dalvik Heap總大小也會下降50%左右,對整體效能會有顯著的提升。
Ashmem即匿名共享記憶體,使用的核心過程是建立一個/dev/ashmem裝置檔案,控制反轉設定檔案的名字和大小,最終把裝置符交給mmap就得到了共享記憶體。在Android系統中Binder程式間通訊的實現就是依賴Ashmem完成不同程式間的記憶體共享。但此處並不利用其共享特性,而是使用它在Native Heap完成記憶體分配。
圖片空間如何才能使用Ashmem,答案在Facebook推出的Fresco中已有提及,那就是解碼時的purgeable標記,這樣在系統底層解碼點陣圖時會走Ashmem空間分配,而非Dalvik Heap空間。這樣就解決了畫素資料存放由Dalvik到Native的問題了嗎?
- BitmapFactory.Options options = new BitmapFactory.Options();
- /*
- * inPurgeable can help avoid big Dalvik heap allocations (from API level 11 onward)
- */
- options.inPurgeable = true;
- Bitmap bitmap = BitmapFactory.decodeByteArray(inputByteArray, 0, inputLength, options);
事實並非那麼簡單,最後實際解出來Bitmap沒有畫素資料(沒有到Ashmem分配任何空間),根本沒有去完成jpeg或者png解碼。此時的Bitmap是個空包彈!它所做的只是把輸入的解碼前資料拷貝到了native記憶體,如果把這個Bitmap交給ImageView渲染就糟了,在View.draw()時Bitmap會在主執行緒進行圖片解碼。
而且不要天真的以為Bitmap解碼一次之後再多次使用都不會引起二次解碼,在系統記憶體緊張時底層可能回收Ashmem裡這部分記憶體。回收後該Bitmap再次渲染時又將在主執行緒完成一次解碼。如果就這樣直接使用該機制,效能上無疑雪上加霜。
那麼怎樣才能避免這個隱形炸彈呢?還好SDK預留了一個C層方法AndroidBitmap_lockPixels。而lockPixels底層完成的工作大致如下圖所示。第一步是prepareBitmap完成真正的資料解碼,在工作執行緒呼叫AndroidBitmap_lockPixels避免了在主執行緒進行資料解碼;第二步是完成對分配出來的Ashmem空間的鎖定,這樣即使在系統記憶體緊張時,也不會回收Bitmap畫素資料,避免多次解碼。
貌似解決了Bitmap渲染的所有問題,但在手淘中則不然。為了相容低版本系統以及提升webp解碼效能,我們使用了自己的解碼庫libwebp.so,怎樣把它解碼出來的資料也存放到Ashmem呢?
如果自有解碼庫libwebp.so要解碼到Ashmem,通過SkBitmap、ashmem_create_region實現一套類似的機制是不太現實的。一方面Skia庫的原始碼編譯相容會存在很大問題,另一方面很多系統層面的核心介面並沒有對外。所以實現這點的關鍵還是要藉助系統已經提供的purgeable到Ashmem的機制,借雞生蛋,穩定性和成本上都能得到保證:
- 依據圖片寬高生成空JPEG。
- 走系統解碼介面完成Ashmem Bitmap生成。
- 覆寫Pixel Data地址在libwebp完成解碼。
上面談到的記憶體遷移都是針對Decoded畫素資料的,而Encoded影像資料在解碼時會在Dalvik Heap儲存一份,解碼完成後再釋放;Ashmem方式解碼時在底層又會拷貝一份到Native記憶體,這份資料直到整個Bitmap回收時才釋放。那能否直接將網路下載的Encoded資料存放到Native記憶體,省去Dalvik Heap上的開銷以及解碼時的記憶體拷貝呢?
的確可以,將網路流資料直接轉移到MemoryFile可實現,但遺憾的是真機測試中發現,小米及其他國產“神機”(自改ROM),多執行緒使用MemoryFile獲取fd到BitmapFactory解碼,會出現系統當機,懷疑是在併發情況下系統程式碼級別的死鎖造成。手機淘寶放棄了這種方案,改用ByteArrayPool複用池技術來減少Dalvik Heap針對Encoded Image的記憶體分配,效果也不錯。如果應用能接受單執行緒解碼,還是MemoryFile方案更具優勢。
上文提到Bitmap畫素資料存放到Ashmem,有讀者可能擔心資料回收問題,其實還是由GC來觸發Ashmem記憶體的回收。在Dalvik層如果一個Bitmap已經不被任何地方引用,那麼在下一次GC時該Bitmap就會從Ashmem中回收,大致流程示意如下圖。
我們再次在魅藍note1中dump出首頁滑動後的記憶體,如下圖可以看出,原來byte陣列(k)大量佔用已經不存在了,Bitmap(c)與BitmapDrawable(已不在前14名當中)的佔用也急驟下降。應用的總體記憶體下降近60%。
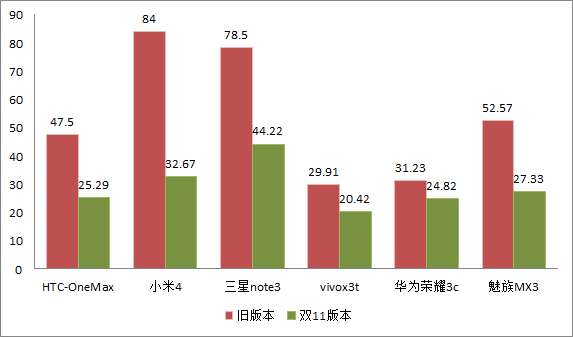
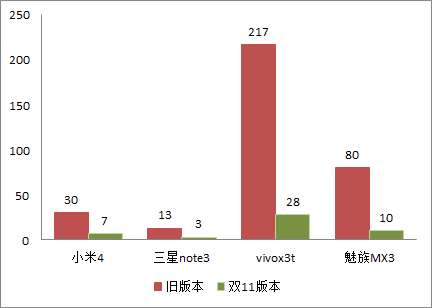
在雙11版本上,針對一些熱門機型在搜尋結果頁不斷滾動使用,進行了不同版本的記憶體佔用對比分析,如下圖。可以看出,除華為3c和vivo這類系統記憶體偏小使用上一直受到控制、記憶體較為緊張的外,大部分機型記憶體的下降幅度都達到45%以上。
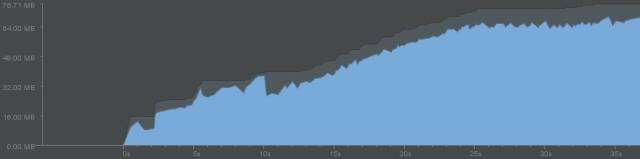
記憶體下降不是最終目的,最終要將GC對效能的影響降到最低。仍然以魅藍note1開啟首頁後滑動到底的記憶體堆積圖來做對比。可以看到舊版本記憶體佔用上升趨勢相當明顯,一路帶有各式“毛刺”直奔70MB,每形成一個毛刺就意味一次GC。而雙11版本中,記憶體只在初期有上升,而後很快下降到21MB左右,後期也顯得平滑得多,沒有那麼多的“毛刺”,就意味著GC發生的次數在明顯減少。
舊版本 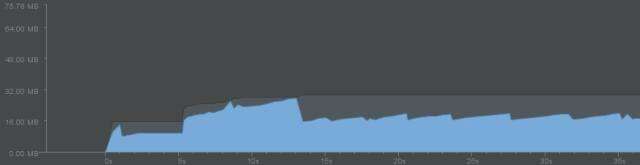
雙11版本
同時使用一些熱門機型,針對雙十一版本在首頁不斷滑動,進行前後版本的GC_FOR_ALLOC次數對比。熱門機型GC次數下降了4~8倍,效果非常明顯。
通過上文描述的各個優化方案,手機淘寶於雙十一前在大部分機型上達到了521目標-Android手機記憶體節省50%,啟動時間和頁面幀率提升20%,H5頁面實現1s法則。
從持續不斷的優化中,我們也得到了一套優化的經驗閉環,由觀察問題現象到分析原因,建立監控,定下量化目標,執行優化方案,驗證結果資料再回到觀察新問題。每一次閉環只能解決部分問題,只有不斷抓住細微的優化點“啃”下去,才能得到螺旋上升的良好結果。
當然,隨著手機機型的日益碎片化,程式功能的複雜化多樣化,效能調優是沒有止境的,在部分低端機和低記憶體手機上手淘效能問題依然不容樂觀。欲窮千里目,還需更上一層樓,接下來我們還會努力通過更多更細緻的優化方案來達到“如絲般順滑”。