一般情況下,編譯器會在任何可能的時候都滿足這些資料元素的對齊要求。在使用英特爾®C++和Fortran編譯器的情況下,可以使用-align(C/C++,Fortran語言)編譯器開關來強制或禁止自然對齊規則。對於通常含有不同型別的資料元素的結構,編譯器試圖通過在元素之間插入未使用的儲存來保持的資料元素實現正確對齊。這種技術被稱為“填充”。此外,編譯器還會以它的最嚴格的對準成員為基準來對齊整個結構。編譯器也可能會增加結構的空間大小,必要的時候,編譯器會通過在結構端部新增填充的方式來使其實現成倍的對齊。這就是所謂的“尾填充”。如此一來,填充就醫浪費儲存空間的代價提升了效能。如果是英特爾®至強融核™協處理器,提供給應用程式可用儲存的數量本身是有限的,這會帶來一個嚴重的問題。
最佳設計方案:最大限度地減少記憶體浪費
開發者可以通過給結構元素排序來最小化這種記憶體浪費,這樣最大/最寬的元素會排在前面,接著是第二寬的,依次排開。下面的這個例子能為你闡明用結構的空間大小給資料元素排序影響:
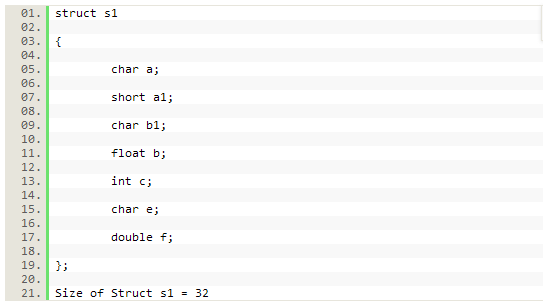
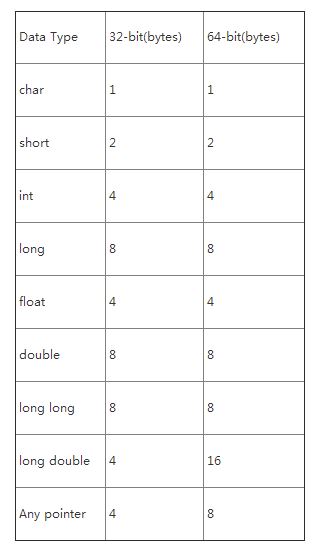
結構s1有11個填充位元組,如下表所示:

看看下面的結構s2:
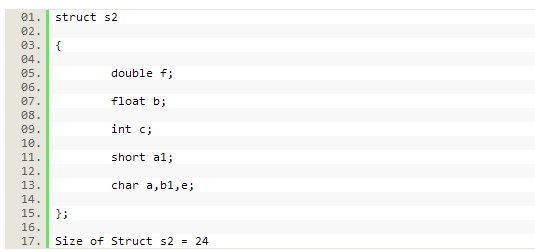
這個結構只包含了3個尾填充的位元組,如下圖所示:

這樣就節省了記憶體。因此,僅僅在結構定義中重排資料元素就有可能避免記憶體浪費。
最佳設計方案:一次只接觸幾個元素
這種給元素排序的一種例外是,如果你的結構比你的快取記憶體線(在因特爾至強融核協處理器上是64個位元組)更大的話,一些迴圈或核心就只能接觸到結構的一部分。在這種情況下,保持結構的各部分能在記憶體中一起被接觸到可能是有益的,這可能會改善快取記憶體區域性性。
最佳設計方案:分解更大的結構
如果你的結構比快取記憶體線更大,並且一些迴圈和核心只能接觸到結構的一部分的話,你可以考慮下通過把大結構分解為多個以單獨的排列儲存的更小的結構。這就潛在地提升了可接觸資料的密度,incident提升了快取記憶體的區域性性。
最佳設計方案:強制對齊特定的元素
你也可以使用_decipsec(align)屬性來指導編譯器比用其他方式更嚴格地對齊資料,這個擴充套件屬性的語法如下:
C/C++:
_decipsec(align(n))<資料型別宣告>
Fortran:
cDEC$ATRIBUTES ALIGN:n::<資料型別宣告>
這裡的n是要求的佇列,是2的乘冪,在英特爾C++編譯器裡最大為4096,在英特爾Fortran編譯器裡最大是16384.你可以使用這個屬性為單個變數,靜態結構或自動儲存持續期間內請求對齊。然而,這就表示,儘管你提高結構的一致性,但這個屬性並不能調整結構內元素的對齊。通過把_declpsec(align)放在關鍵字struct前面,你就為僅僅這種型別的物件請求適當的對齊。讓我用下面這個例子來說明我的觀點:
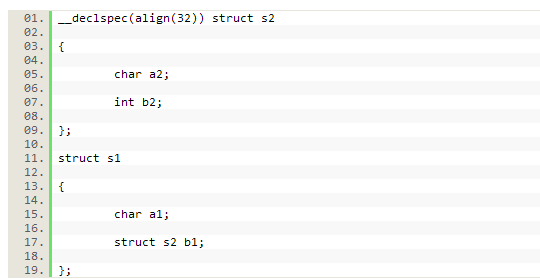
在上述示例中,對字元a2和整數b2的對齊仍然各自保持為1個位元組和4個位元組,這是預設的。然而,結構s2的每個例項都被對齊到32個位元組的邊界,正如_declspsec宣告裡描述的那樣。因此,結構s1內部的結構s2目前的每個例項都將對齊到32個位元組的邊界。
最佳設計方案:動態分配記憶體對齊
我們還可以通過動態分配結構s2的排列來進一步擴充套件這個例子:

最佳設計方案:使用align(n)和結構來強制小資料元素的快取記憶體區域性性
你也可以使用這個資料對齊支援來為快取記憶體線使用最優化提供優勢。通過把平常經常在一起使用的小物件聚集到一個結構裡,並強制這個結構從快取記憶體線的起始端分配記憶體,你就能有效地保證每一個物件在需要的時候都能及時地被裝載進快取記憶體裡,這樣會有很明顯的效能提升。例如,考慮i和j這兩個被頻繁呼叫的變數,他們可能會被分配到不同的告訴快取線上。你可以像下面這麼來宣告它們:
相關閱讀
評論(1)