在正式講環境大資料之前,我們來講一個和身邊有關的案例。大多數去過星巴克喝咖啡的人都會有這樣一個疑惑,“為什麼星巴克室內溫度比室外溫度低呢?”甚至有人開始抱怨說室內溫度太低,但是這也不會帶來什麼改變。因為在冷的環境下,顧客肯定會傾向於買熱咖啡,而且是大杯的熱咖啡。像溫度、水分、聲音這些東西跟我們平時生活息息相關,包括購買意願實際上跟我們周圍環境都是直接相關的。
環境資料的特性
前段時間參加了100offer組織的大資料技術沙龍,參講嘉賓都是來自知名網際網路科技界的技術牛人,但是給我影響最深的還是佳格大資料CTO張弓講的大資料在環境改善方面所做的一些努力,如何通過資料分析來確定一定範圍內氣候的變化,以及接下來大資料在環境技術方面還需要做那些完善。
張弓說,環境兩個字解開了說就是環我之境,周圍的環境才是我們所研究的資料核心。所謂環境大資料就是指氣象、溫度、溼度,包括道路圖、建築圖、汙染問題,也包括資源性的資料。這些資料有一個特點,具有時空場。
大家現在都講大資料,大資料就是最核心的三維,人們通過IT技術獲得更多的資料。大約15年前,我們就開始通過接觸環境資料來做天氣預報,因為這是一個處在前端、即時性要求非常高的預報,所以資料的模擬處理都是按照秒級來計算的。所以說資料量是非常大的,包括各種衛星影像所提供的點上資料、面上資料,但是主要以影像或影像流為主。在現在看來,那就是海量資料。
衛星影像到全球原油儲量
這裡再列舉一張Skybox拍攝的儲油罐的照片,從這一張照片上能獲得哪些有價值的資料呢?當然是可以從中獲悉儲油海港的大小,運輸量的大小。

這些資料都是從儲油罐的陰影來計算的,通過太陽高度角和陰影長度來計算儲油罐的油量,基本上利用這樣的方法能將全球80%以上的原油儲量計算出來,而且是完全不可阻止的。這就是黑科技的用途。

大資料就是技術型企業的根本,對資料的分析精度決定了資料的價值大小,張弓說他們以前分析資料的尺度非常粗糙。簡單的說,對時間的衡量是以年或月做單位的,這種資料分析的商業價值就會比較低,更多作為策略性使用。
環境資料:大資料時代前的海量資料
現在的原始資料是非常大的,比如一張從衛星裡傳送出來的圖片,是一種描述地面的時空資料,資料量非常大。另外一類是模型資料,對模型進行分析。因為時空是連續的,所以用於模型分析的方法相對較為複雜,例如從內蒙古刮過來的沙塵暴會到它的下風口北京,屬於連續時空性動作,很難用資料來描述。十幾年前基於數學演算法,針對時空影像資料利用MPI+Fortran來處理海量資料,還創造出HDF和NetCDF這些類似於現在Spark或Hadoop的工具。

眾所周知,資料最核心的部分就是具有極強的時空連續性,這裡就涉及到資料獲取和資料融合的問題,因為不同的資料來源,不同的資料型別、不同的資料格式,導致每一個時空上面顆粒解析度是不同的,如何把250米*250米的資料和一個30米*40米的資料進行比較,這裡就涉及到比較複雜的時空尺度融合問題。從資料結構上考慮,如果時空資料本身是連續的,可能更便於計算,它的分析工具的核心也是基於Spark為主。
資料視覺化就更復雜了,這裡面最主要的一個視覺化型別就是把資料變成圖形來展現,而且讓人們更容易的接受這些圖片。
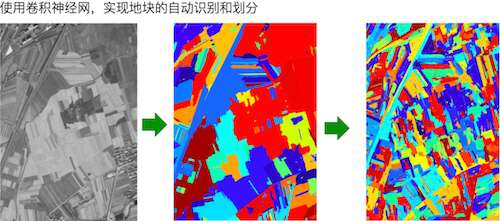
資料分析是針對影像資料化過程的核心內容,就相當於一個分析視覺化的過程,從而獲得我想要的資料,這是比較困難的。所以這裡就用到了能夠進行影像識別和模式識別的機器學習和深度學習的概念。比如說如何用不同的顏色把田地裡不同作物表示出來,哪怕是作物的方向也要識別出來的話。這裡就要分析紋理的朝向和密度。第一步先做深度學習,原始解析度是半米乘半米,深度學習要有足夠的層數,然後對影像進行處理,建立一些視窗,比如建立3乘3、5乘5、9乘9視窗,下圖是用了208個方塊做出來的深度神經網路結果,識別度超過人眼。這樣做的結果就是能夠很清晰的知道莊稼的長勢如何,如何根據這些資料來安排接下來的土地利用情況,最大化土地利用率。
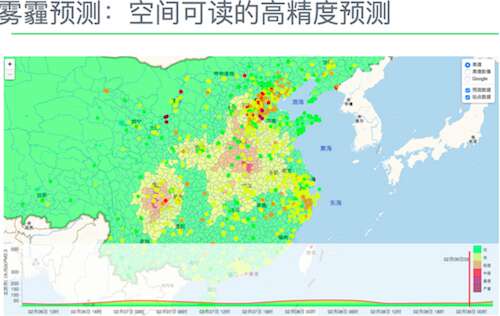
霧霾預測
這裡可以來談談之前在網上傳播很廣的霧霾預警圖——佳格“霾圖”。這是基於環境大資料,對大氣汙染進行實時監測預警的工具。“霾圖”用地圖的形式實時展現我國任一地區的大氣汙染資料,並預測未來五天的空氣質量。其實時資料目前每小時更新一次,空間精度為五公里。用大資料直面霧霾這塊“硬骨頭”,不僅需要充分準確的資料來源、優秀的資料處理,還需要合適的視覺化能力。
對於採集到的大量資料,需要進行整合處理才能用來生成霾圖。霾圖的資料演算法主要包含兩個任務:
- 資料同化和實時展示任務。獲得的衛星資料主要分兩種,一種是時間解析度高的資料,一種是空間解析度高的資料。這需要把兩種資料進行融合;同時衛星並不會直接給出PM2.5的測量資料,而是一類光學指標,其中包括大氣氣溶膠光學厚度(aerosol optical depth)。利用基於不同城市自主研發的演算法將這個變數計算出準確的PM2.5濃度值,並在“霾圖”上實時展示。
- 預測任務。目前國內空氣質量預測主要有兩種傳統方法:第一種是根據大氣物理化學(汙染物的沉降,運輸和擴散以及二次氣溶膠反應)的經典演算法跟汙染物排放清單的集合對未來大氣情況進行推測;第二種是基於數理統計模型方法。比如拿到過去十年的資料,通過對時間序列的季節性,趨勢性進行分析來做預測,輔以人工判斷。這兩種方法主要使用的都是地面監測點提供的資料,並沒有用到衛星資料。同時國內排放清單資料存在時效性弱的弊端,並且地面監測點分佈不均且資料容易受到人為因素的影響。這樣所得到的預測結果存在著極大的偏差和侷限,準確度較低。
相比這兩種傳統方法,佳格“霾圖”所開發的預測方法和模型具有自己的特點:首先,佳格做預測的資料是更精確均勻的衛星資料。其次,佳格運用模型最優化方法,綜合考慮多種國際上最先進的氣候預測模型,通過演算法選出動態的最合適的預測模型,用於預測未來五天內的空氣質量情況。
張弓在最後的演講中也提到,大資料的潛力還沒有被完全挖掘出來,這需要時間和不斷的嘗試才能發揮它最大的價值,更好的改善我們的日常生活環境。