這是一個好訊息,如果你希望在2016年找一份資料科學的工作—在該領域職位空缺的數量正在不斷增加,企業希望利用大資料來獲得競爭優勢。但事實上,找一份夢寐以求的資料科學工作就意味著你要具備一些技能的組合,你可能會驚訝學習哪些技能是僱主所最需要的。
最近,人們在CrowdFlower上針對Linkedin的3490個資料科學職位做了分析,並對最常出現的21個技能進行了排序。有些結果並不那麼令人驚訝—SQL排在最前,而其它的結果可能是資料科學領域不斷髮展的領先指標。
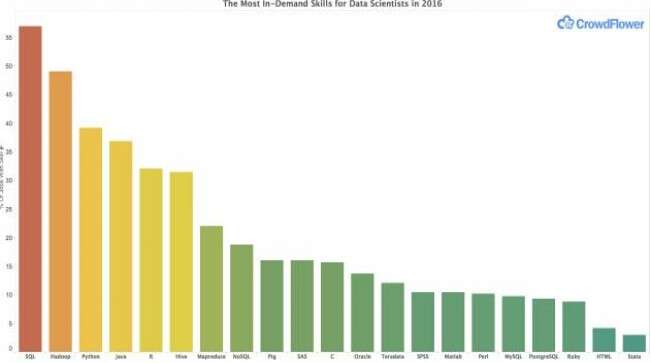
如上所述,SQL是最常見的技能,在Linkedin釋出的所有資料科學工作中佔比達到了57%。Hadoop排在第二,佔比49%。這並不出乎CrowdFlower公司CEO和創始人Lukas Biewald的意料。CrowdFlower是美國矽谷一家從事眾包資料處理的公司。
“SQL和Hadoop排在前兩位並沒什麼驚訝的,因為它們本身就是儲存資料的技術”Biewald告訴Datanami(本文轉譯自該網站)。“每個資料科學家必須知道如何獲取資料。如果你不知如何獲取資料,那你什麼都做不了。”
在所有資料科學的招聘資訊中,python是排在第三名的技能。在CrowdFlower去年關於資料科學家哪些技能是最重要的調查中,python排在R的後面。但在本次招聘資訊的調查中(這無疑是更具有前瞻性的範圍),python作為資料科學的一項關鍵性技能佔比達到了39%。相比之下,R是32%。
相比R來說,為什麼現在越來越多的僱主正在尋找具備python技能的資料科學家?Biewald提出了自己的看法:“python的工具集越來越好。已經有很多基於python的統計工具”。“還有一個認識是資料科學不僅僅是統計學”。
設想一下,資料科學家80%的時間花費在資料清理和資料準備上,而只有20%的時間是用來做分析。這或許可以解釋python突然出現的原因。
“我認為Python是做資料清理的語言,而R是做分析的”,Biewald說到。在創辦CrowdFlower之前,他負責領導Yahoo的搜尋相關團隊。“由於資料科學更多的是做資料清洗和準備,python正變得越來越重要。它無疑是將資料整理成適合做分析的資料格式最好的語言”。
事實上,Java排在第四位讓人有點摸不著頭腦。因為Java本身不是資料科學所要求的掌握一門語言,當你在java中寫Hadoop的時候,它的高配就顯得有道理了。其它跟Hadoop相關的工具都排在前10,包括Hive(31%),MapReduce(22%)和Pig(16%)。
對於這份CrowdFlower從Linkedin編輯過來的職位列表,多少有些遺漏。Apache Spark,在上面給出的資料科學技能要求中沒有出現過。Scala也沒有出現過,它是在Spark框架內處理資料的主要途徑之一。
這可能是因為Spark還比較前沿,大家對它知之甚少。“現在周圍對它有很多炒作,但可能還是太早了”Biewald說到。“在CrowdFlower,我們已經開始使用它了。我認為這門技術很棒,但在企業真正使用它的時候會有些滯後”。
Spark和Scala可能是資料科學的未來(它們在Alphabet[NASDAQ:GOOGL]公司中得到大力支援,矽谷的許多高科技公司也在廣泛的使用它們)。但不是每個資料科學專案或團隊都需要走在技術的最前沿才能實現他們的大資料成果。“令人驚訝的是現在很多人都在尋找資料科學家,但是我認為他們中的很多人是不想走在最前沿的”Biewald說到。
這份CrowdFlower列表中包含了許多知名的資料分析工具,包括SAS(佔比16%),SPSS(10%),Matlab(10%)和Stata(佔比3%)。Biewald認為這些工具仍是有價值的並且在未來一段時間內還會繼續使用。但是他希望它們的市場份額逐漸被那些專門為大資料設計的新工具所奪走。
“資料科學的角色大於統計學家”他說。“在我們的腦海裡,這些舊的語言更多的是建立在統計學家的基礎上,它們只是對少量的資料進行分析。而排名在前的Hadoop,python和Java則可以執行TB級的資料。你可以用SAS,SPSS,Matlab來做大資料分析,但這不是它們設計的目的”。
不是每個人都同意“資料科學”或“資料科學家”應該做什麼以及應該掌握什麼樣技能的定義。事實上,一些人反對使用術語“科學”,而寧願用諸如“應用統計”的短語。(想起了哈佛商業評論稱應用統計學家是21世紀最性感的職業)
但在Biewald和其他人眼中,處理資料的能力和統計分析的能力同等重要。這就是他對資料科學家進一步給出的定義。
“在過去,我們處理幾千條記錄的時候不是特別難。但是,當資料量達到數十億條記錄的時候我們就需要真本事來得到一個規範的格式,以便我們進一步做迴歸或機器學習”他說。“對於這種情況,我想要聘請的是一名掌握python或者是C、Perl、Ruby亦或是一門更多做資料處理而不是做資料分析的語言的資料科學家”。