自從大資料這個詞出來以後,資料已經成為一個非常明確的科學領域。在這當中很少有人詳細地探討資料科學的結構和它面臨的問題,包括我們行業面臨的問題。
資料科學有三個非常重要的層次:資料的獲取、資料的描述和資料的分析,這三件事是不同的,不要把它混淆了。
1.資料的獲取
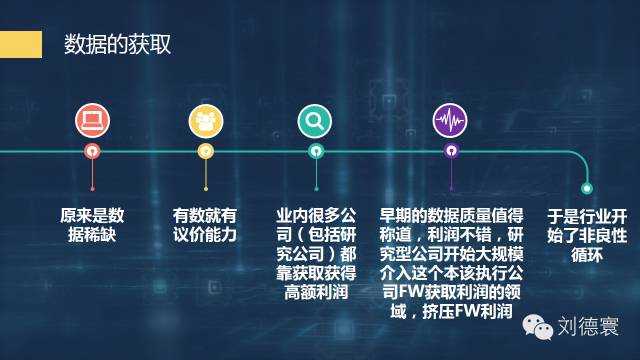
以前資料的稀缺導致行業內出現非常大的非良性迴圈。
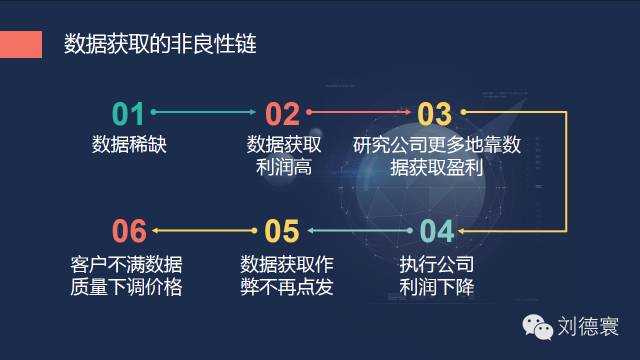
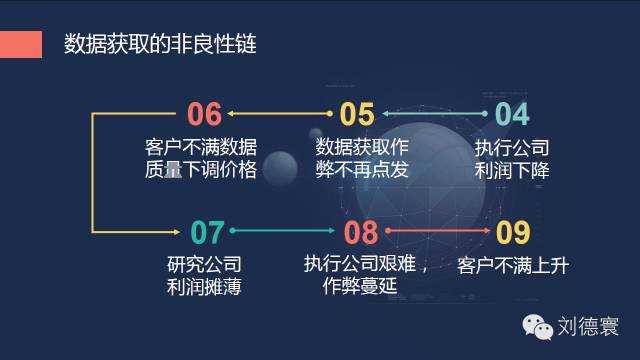
在這個過程當中,又正好趕上了一個新的時代——機器化資料橫空出世,突然之間,甚至一夜之間資料不再稀缺了。單靠獲得資料,你能拿到高額利潤的可能性微乎其微,這樣就必然導致執行公司如果要繼續作弊必死無疑,未來五年內我們可以清楚的看到,研究公司不好好做研究,也照樣是必死無疑,無論你是國際的,還是國內的,因為時代變了。所以資料獲取這一塊,要有非常清醒的認識。
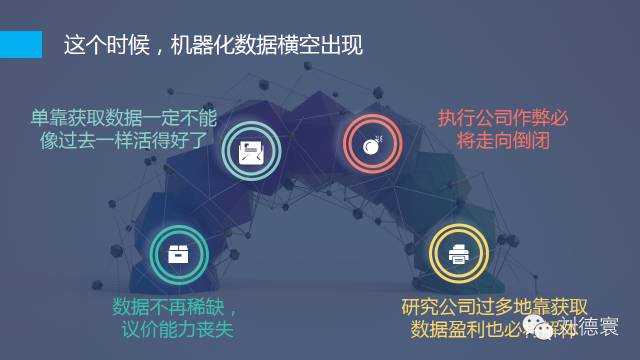
在這個時候大資料,正常的講叫機器化資料已經被神話,而市場研究公司被積壓在這裡,市場研究資料的結構化,它必須滿足兩個條件,一是真的,二是價格是低的,這兩件事造成的後果是什麼,我相信業內的所有公司都會有體會。

2.資料的描述
再看資料的描述,由於整個社會大環境巨大的變化,在描述環節上出現了非常大的問題,這個問題中你會發現形成了新的、不同的非良性迴圈。為什麼?資料不稀缺了。而在這個時候,機器化資料出來的東西做點頻率表,做點互動表很簡單。如果資料描述能夠替代資料分析,這個世界一定會毀掉,因為資料想騙人太容易了。

接下來的過程當中,機器化資料由於資料收集簡單,整理資料的過程非常容易。所以直接面向銷售,這個面向銷售就出現了充滿荊棘的歷程。

再看研究公司的結構化資料,大型公司由於沒有應對,我在行業這麼多年,一直在這些時期,有機會就在呼籲洞察這個詞。實際上我們的研究員正在日益變成填數工具,而不是洞察。資料不再稀缺,你在機器化資料面前,你填數的過程當中,資料的真假還在存疑,這時候你不敗誰敗,必然敗。而且別忘了機器化資料的成本趨近於零,所以大中型研究公司的解體、兼併、重組在不遠的將來一定會頻現,這是沒有辦法的趨勢。

現在資料科學有七大危險趨勢:





::__IHACKLOG_REMOTE_IMAGE_AUTODOWN_BLOCK__::13

3.資料的分析
以上七個危險趨勢將直接導致資料分析中的危險,什麼是資料分析?我先從最簡單的案例說起。
案例一:簡單表格的危險
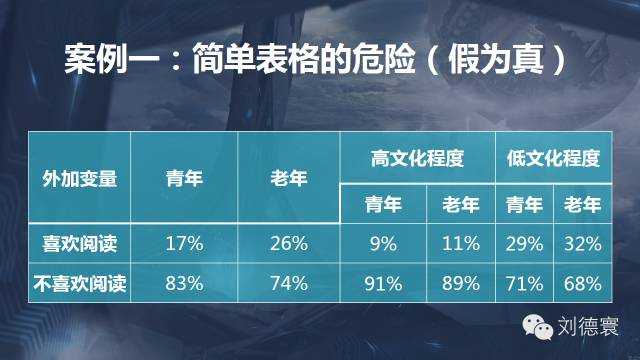
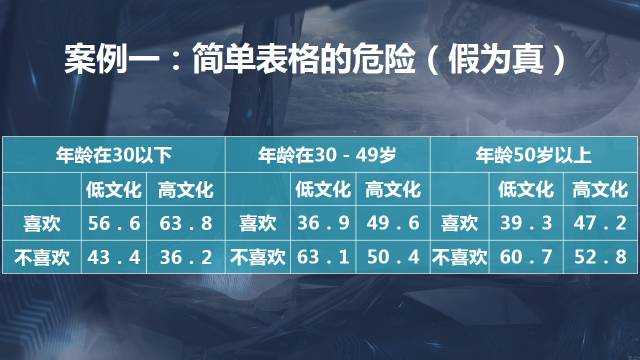
這個資料的結果,意味著什麼?老年人比年輕人更喜歡這個東西。實際的結果呢?老年人和年輕人沒有任何差異。高低文化之間有差別嗎?所有的結果都顯示高文化程度的比低文化程度的人更喜歡,總體上它就是相同的。
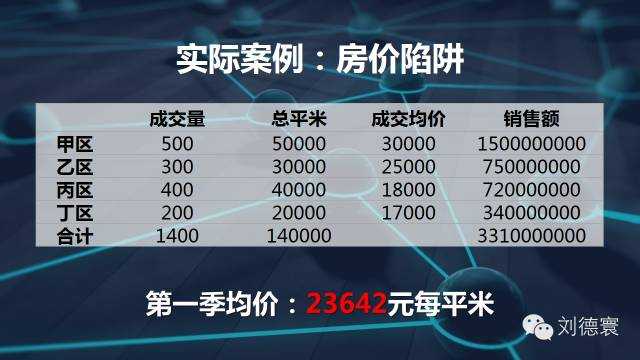
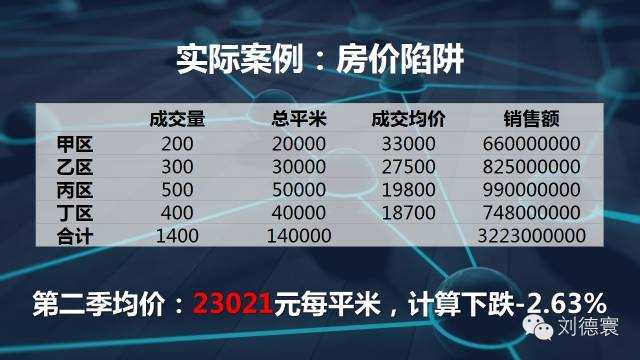
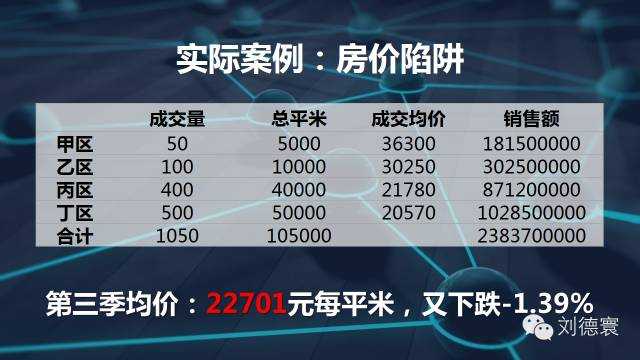
再看一個更加實際的案例。我們知道房價是怎麼算的,房價是加權算術平均數。現在看一看房價,房子的均價跟房子的成交價格沒有關係,跟銷售結構有關係。所以在這個時候,房價的均價大約是這樣的,我告訴大家房價在下一個季度全面上漲10%,但是銷售結構略微有一點變化。房價下跌2.63%,大看清楚定價了嗎?任何一個地方都上漲了10%,接下來銷售結構一定會再變,房價又漲了10%,房價又下跌了,但是統計數字會告訴你下跌4%。
案例二:無關轉相關係列
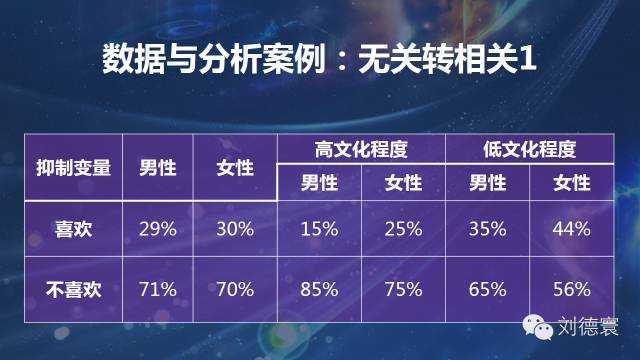
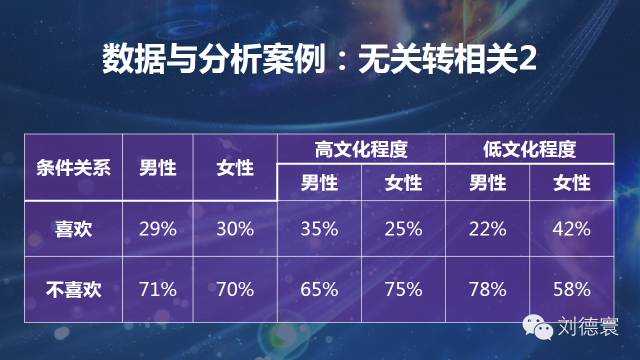
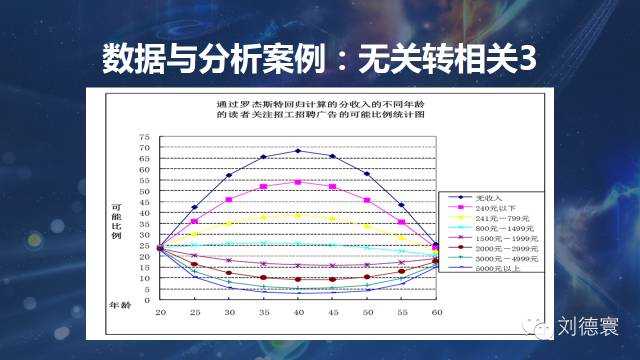
這是我1998年獲寶潔論文獎的時候得到的模型,表面上一大堆無差別、無差異的情況,導致了什麼情況呢?看起來沒有差異,一個是男的比女的喜歡,一個是女的比男的喜歡,整體上沒有差異。但是差別大嗎?規律性強嗎?
案例三:建模預測

<strong>我們在2011年用的詞叫蘋果熟透了,蘋果在一個領域發展。2012年我在網際網路大會上,在我們這個會場上我都說過華為將崛起。2013年我說過三星必然下滑,去年2014年也是一樣的,這兩個大會我都說過小米將面臨問題,我不是神,但是模型能。2015年什麼情況?我不想對任何一個品牌現在來說,大家關注我們要釋出的手機人報告,那個時候我再開會,會詳細地把這個結果告訴大家。
我讓大家看一個結果,模型的基點預測點是這張圖:
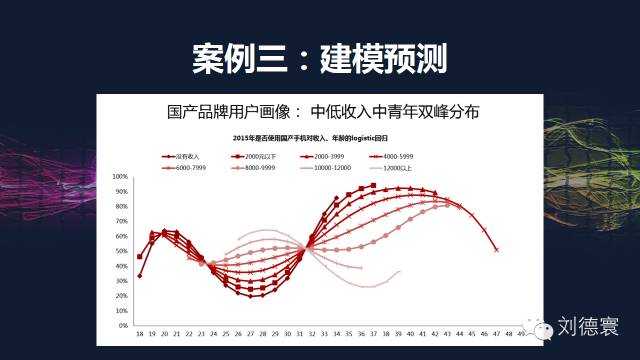
這個模型你能不能做出來?我一直在說,中國調查業從來不缺資料,從來不缺所謂的描述,只缺分析。如果被這些網際網路公司,被碼農牽著走,那不是笑話嗎?他們能代表中國的分析能力嗎?中國的分析能力不是他們,而一定是我們。
4.小結



