
以機器學習為代表的人工智慧領域目前是科技領域最熱門的方向之一,它被稱為新時代的水電煤,會為所有產業帶來基礎性的革命。但對於一家公司、一個部門、一款產品和一位產品經理來說,他們需要一個簡單而重要的答案:我真的需要機器學習嗎?
你真的需要機器學習嗎?
很多公司和科技部落格都在一直鼓吹“人工智慧”代表未來,並提出他們會如何運用“機器學習”來改進科技,在競爭中脫穎而出。但是機器學習到底是什麼,你應該怎麼使用它?又或者它只是2017年的一個時髦熱詞而已?
長話短說,以上問題的答案是肯定的,在大多數情況下 – 但是在它可以提供幫助的地方,機器學習可以是革命性的。
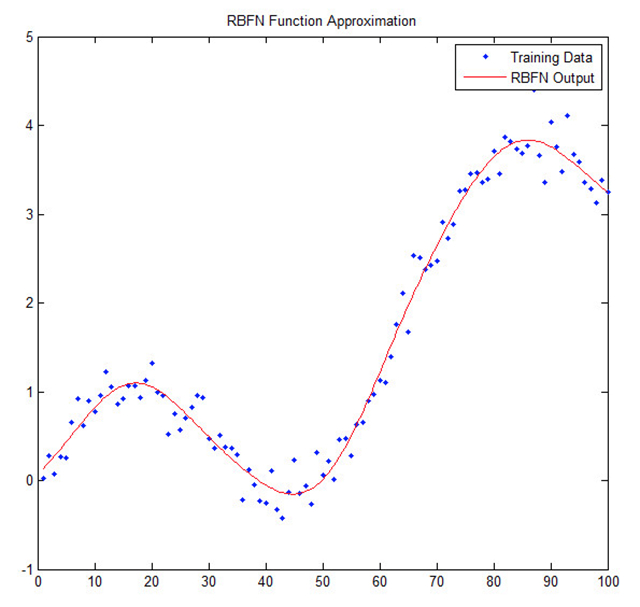
所以機器學習到底是什麼?以它最原始的形式來說,機器學習是一項實踐函式逼近(function approximation)的藝術,或者說是要做出有根據的推測。它和專業人員的經驗是相同的概念,比如管道工擁有根據房屋中漏水情況快速、準確地判斷造成漏水原因的經驗。在機器學習中,我們稱這樣的經驗為“大資料”。在遇到和解決的每一個問題之後,管道工會得到一個新的資料點,她可以使用這些知識來解決將來會遇到的、相似的問題。
上面提到的這些看起來都很棒,但是對於近期機器學習熱度的躍升,我敢於稱其為時髦術語也是有原因的。機器學習幾乎從來都不是問題的終極答案。機器學習會很容易讓簡單的問題變的異常複雜 – 比如想要重新發明for迴圈的想法是完全站不住腳的。大多數所謂使用“機器學習”的公司或者是沒有真的使用機器學習的技術,或者是把普通的演算法開發稱作機器學習來達到市場宣傳的效果,又或者是在產出過度複雜、計算量巨大、價格昂貴並且根本不必要的解決方案,想要解決一些本來可以使用常規手段解決的問題。
這並不意味著機器學習永遠都沒有用處。事實上,當把它正確地運用在適合的問題上,機器學習可以是一件不可思議的工具。但什麼是一個適合的問題哪?雖然不是一個機器學習問題蓋棺定論的定義,這裡有一個簡便的清單,來確定一個問題是否值得使用機器學習的方式,還是說更適合用標準的解析辦法。
作為一個機器學習問題:
- 會有“大資料” – 許多許多資料點(一個大型的專案如果沒有上百萬個資料點的話,也許不會見到很好的效果)
- 是一個複雜的問題 – 一般是一個以標準模式非常難以解決的問題,經常會需要一個領域中的專家
- 是具備不確定性的 – 一樣的輸入不一定產生一樣的輸出
- 是有多維度的 – 經驗法則是資料點的採集是從最少9各方面來做的時候,這樣的問題會更適合機器學習方式
一些符合這個清單的、流行的機器學習問題的例子包括:醫療圖片處理,產品推薦,語音理解,文字分析,面部識別,搜尋引擎,自動駕駛車輛,擴增現實,預測人類行為。
機器學習面臨的其中一項最大的挑戰是如何處理系統中的不確定性,不確定性是指同樣的輸入不一定會產生一樣的輸出結果。針對這個問題,我們會在這篇文章中以例子的形式來解釋,這個例子是預測多倫多的天氣。在這個例子中,我們有大資料 – 包括上百年的多倫多的天氣資料。 這個問題足夠複雜,準確的天氣預測需要具備氣象科學訓練和經驗的專家。這個問題是具備不確定性的,2016年2月23日天氣冷並不意味著2017年2月23日天氣也會是一樣的,儘管他們分享一樣的歷史資料。這個問題同時也是多維度的 – 風向模式,雨量模式和任何一個會影響天氣的因素都可以成為解決問題的一個新的維度。因為這個問題是具備不確定性的,我們必須使用我們有的資訊,儘量好的去預測系統的輸出結果(預測天氣)- 我們要做出最合理的猜測。
對於機器學習來講,我們的最合理猜測或者函式逼近幾乎總是關於對於數學的創造性運用 – 這可能包括統計學/概率論,向量學,優化或者其他數學的方法。存在著幾種核心的機器學習問題,他們可以幫助我們確定什麼樣的解決方法可以最好的解決一個問題:分類學,迴歸分析和聚類。在例子中,我們見到的是一個迴歸分析的問題 – 從資料中預測持續性的趨勢。存在著幾種核心的方法去訓練系統,或者說給系統提供經驗去學習,這些方法包括:有監督學習,無監督學習和強化學習。在我們的例子中展示的是有監督學習,在這個例子中,所有用來訓練的資料的輸入和輸入都是已知的。我們給出一個歷史日期(輸入)就可以知道當天多倫多的天氣(輸出)。定義問題和訓練模型讓決定使用什麼樣的方法去訓練機器學習演算法變的更加簡單。
到了這裡,你已經決定要預測天氣(或者解決一個不同的機器學習問題)而且你已經使用上面的清單確定了這是一個真實有意義的問題。但是應該是從哪裡入手哪?下面是一個關於解決機器學習問題步驟的簡便指南:
- 定義有意義的資料
- 定義問題
- 定義解決問題的方法
- 產出訓練和測試資料 – 從經驗來講,應該保持70%的訓練資料量,30%的測試資料量
- 訓練和測試演算法
讓我們用我們天氣預測的問題來實踐一下上面提到的步驟:
第一步是定義有意義的資料。什麼樣的屬性是有意義的,怎麼樣去定義一個“好”的資料點和“壞”的資料點?我們可以拿幾個我們例子中的屬性來解釋一下,比如讓我們取溫度,降雨量和風速這三個屬性,把這三個屬性放在一起,我們可以基本瞭解到特定的一天天氣如何。如果同時有像特定一天多倫多人年齡中位數這樣的屬性,我們就應該把這樣的屬性排除在有效資料之外,因為這樣的屬性跟我們要解決的問題並沒有關係,而且有可能會影響最終的結果。
第二步,我們已經確定問題是一個迴歸分析的問題,並且應該使用有監督學習的方法。第三步需要選擇一個真正的機器學習方法,在這我們不會討論太多細節,簡單來說讓我們選擇線性迴歸。第四步是取得訓練資料(留下30%的資料做測試之用)。第五步就是 實際的訓練和測試。
也許你已經從上面的步驟中發現了,實際去訓練演算法是最後也只是最不重要的一步。創造一個強大的機器學習的重要的一步是在程式設計之前,就確保你擁有有意義的資料,一個定義清晰、明確的問題和解決方案。
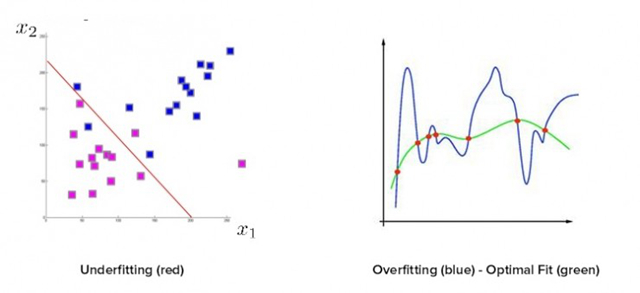
即使你有了定義清晰、分類準確的解決方案,有意義的資料,正確的測試資料,在資料趨勢中包括了異常值,仍然有很多地方可能出錯。在很多機器方案背後,最常見也是最致命的錯誤是低度擬合/過度擬合。低度擬合,或者也叫過高偏差,意味著最終的近似函式太過簡單,不能很好地代表資料的趨勢。想象一下我們試圖畫一條直線穿過多倫多一年溫度的圖表,這條直線很難撞到任何一個資料點。在低度擬合和過度擬合兩者中,更常見也更危險的是過度擬合,或者也叫過高方差。在這個情況中,最後的近似函式會太過複雜,也不能很好地表現資料趨勢。過度擬合經常產生比低度擬合更差的結果,大家也很容易落入這樣的陷阱。
這篇文章只是一個關於機器學習的基本介紹,更多的學習資料正變的更加普遍,在很多語言和GUIs中(目前一些最好的機器學習的資料是用Python寫就的),已經出現非常多即用型的機器學習演算法和測試資料可以被用來做實驗,其中包括Theano, Tensorflow, Weka甚至包括Octave和Matlab。