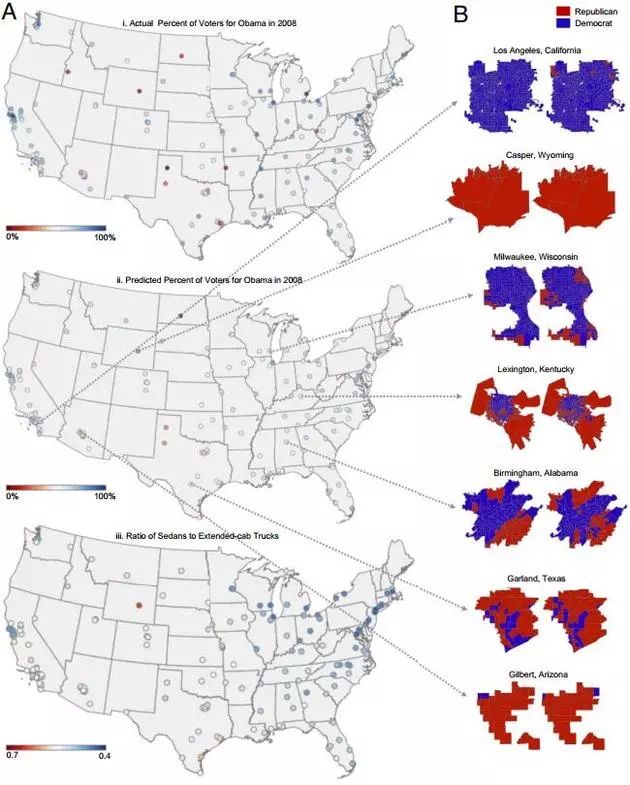
針對民主黨和共和黨選區的人們更喜歡轎車還是皮卡這些事,市場研究人員和政治分析師們已經研究了幾十年。不過近日,史丹佛大學研究人員們通過一個雄心勃勃的專案——分析谷歌街景上的5000萬張照片和地理位置資料——也得出了相同的結論。在新近發展的人工智慧技術的幫助下,研究人員能夠分析大量的影像、提取可以進行排序和挖掘的資料來預測一些事情,比如某個社群的收入水平、政治傾向、購物習慣等。
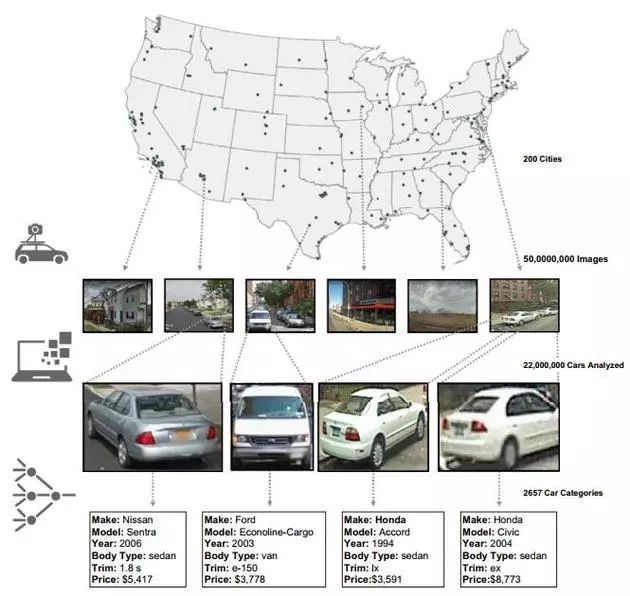
在史丹佛大學的這項研究中,計算機收集了數以百萬計的汽車影像,其中包含了製造商和具體型號等資訊。
為這項研究提供建議的貝勒醫學院基因組研究中心的電腦科學家Erez Lieberman Aiden指出:“剎那間,我們就可以對影像進行同樣的文字分析”。
Mr. Lieberman Aiden表示,計算機和人類一樣,都可以通過讀取和觀察這兩種截然不同的方式來理解世界。從這層意義上來說,‘計算機被捆綁在身後的雙手已經被釋放’。
對於人工智慧來說,文字是更容易處理的資訊,因為英語單詞就是由26個字母組成的離散字元。這讓它更接近計算機的自然語言,而不是面對一團混亂的影像。
近年來,由大型科技公司主導開發的影像識別技術已經迎來了很大的進步。而史丹佛大學的這項研究,讓我們得以一瞥這方面的潛力。
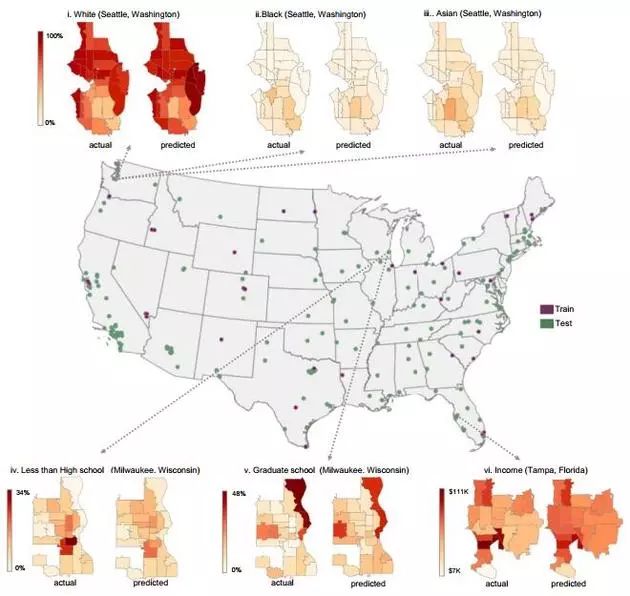
將車輛製造商、型號、年份等資訊從影像中提取出來,然後與其它資料來源進行聯絡,該專案得以預測許多“有趣的事實”,比如鄰里間的汙染和表決方式。
研究領導人Timnit Gebru表示:“影像資料的使用,將催生一套社會分析的新工具”。有關這項研究的詳情,已經分階段發表。
比如在最近的11月份,他們就在《美國國家科學院學報》上,發表了一篇題為《藉助深度學習和谷歌街景來預估全美社群人口組成》的文章。
附論文全文:





