補充有兩個:
- 一個是系列(五)中講到的事件程式設計(網址連結),該文提及到了事件程式設計的幾種方式以及容易引起的一些異常,本文補充“多執行緒事件程式設計”這一塊。
- 第二個是前三篇部落格中提及到的“泵”結構在程式設計中的應用,我稍微做一點補充。
總結有一個:
- 如果您善於總結和類比,您會發現世界好多東西其實都是一樣的。這部分主要理清楚框架時代中的框架和我們coder所寫程式碼之間的關聯。
下面是正文:
多執行緒事件程式設計
系列(五)中提及到了事件在註冊和登出時,系統已經做了多執行緒處理,只是不太完美(以this為鎖物件,this是public的,鎖物件是不能對外公開的),後來透過自己定義鎖物件加鎖來實現的。可是該篇文章並沒有提到在類內部激發事件時可能引發的異常:


1 class Subject 2 { 3 XXEventHandler _xx; 4 object _xxSync = new Object(); 5 public event XXEventHandler XX 6 { 7 add 8 { 9 lock(_xxSync) 10 { 11 _xx = (XXEventHandler)Delegate.Combine(_xx,value); 12 } 13 } 14 remove 15 { 16 lock(_xxSync) 17 { 18 _xx = (XXEventHandler)Delegate.Remove(_xx,value); 19 } 20 } 21 } 22 protected virtual void OnXX(XXEventArgs e) 23 { 24 if(_xx != null) 25 { 26 _xx(this,e); 27 } 28 } 29 public void DoSomething() 30 { 31 // … 32 OnXX(new XXEventArgs(…)); 33 } 34 }
如上程式碼所述,在多執行緒情況下,if(_xx != null)這行程式碼執行為true後,在執行下一行_xx(this,e);之前,_xx可能已經為null,引發異常理所當然。解決方法很簡單,照葫蘆畫瓢,在OnXX中加鎖,原始碼變為:
1 protected virtual void OnXX(XXEventArgs e) 2 { 3 lock(_xxSync) 4 { 5 if(_xx != null) 6 { 7 _xx(this,e); 8 } 9 } 10 }
沒錯,這樣確實能解決激發事件時有可能引發的異常,但如果僅僅是為了說明該方法可以解決問題的話,我是不會特大篇幅來說明它的。我們來看另外一種巧妙解決方法:
1 protected virtual void OnXX(XXEventArgs e) 2 { 3 XXEventHandler xx = _xx; 4 if(xx != null) 5 { 6 xx(this,e); 7 } 8 }
如上程式碼所述,在判斷_xx是否為null之前,我們先用一個臨時變數代替它,之後將使用_xx的地方全部替換為xx。這樣,就不用擔心xx會由其它執行緒改變為null了,因為xx對其他執行緒不可見。這個原理很簡單,委託鏈是不可改變的(Delegates is immutable),也就是說,我們註冊或者登出事件時,並不是在原來的委託連結串列基礎上進行增加或者刪除節點,而是每次都是重新生成了一個全新連結串列再賦給委託變數。其實這個諸位可以找到規律,我們在註冊登出事件時,一般obj.Event+=…或者Event = Delegate.Combine(…) Event = Delegate.Remove(),可以看出,每次都是將一個全新的值賦給原來委託變數,並沒有在原來連結串列基礎上進行操作,因此,_xx和xx雖然同是指向同一連結串列,但是我們登出註冊事件時,只是讓_xx指向另外一個連結串列而已,原連結串列(xx)並沒有變。
這個其實就是我們剛學習程式設計的時候,使用值傳遞呼叫方法時,實參將值傳遞給了形參,形參如果改變了(被重新賦值),實參的值是不會變的。指標(引用)也一樣,形參指向了另外一個物件,實參還是指向原來的物件。
“泵”結構的另外一種方式
系列(十三)中(網址連結)講到,在泵結構中,如果在獲取資料環節直接處理資料容易降低獲取資料的效率,也就是說,最好不要一獲取到資料就處理它,因為處理資料大多數情況下是一個耗時過程,資料處理結束前,下一次“資料獲取”不能開始,影響獲取資料的效率。如下圖:

圖1
如圖所示,處理資料在泵迴圈體內,資料處理結束之前,緩衝區中的資料就會大量積累。我們當時的做法是,獲取資料後不馬上進行分析處理,而是先將資料寫入一個有序緩衝區,然後另建立“泵”去分析處理這些資料,這樣一來,不會影響資料獲取環節的效率。因此,諸位可以看見有三個“泵”(資料接收,資料分析,資料處理)聯合工作。
事實上,太多“泵”協作工作也是會影響整個系統效率的,這就像多個人協同工作,雖然人多力量大,但是人多需要考慮同步共享資源、人跟人之間的協作能力等情況,這個好比“生產者消費者模式”,

圖2
當“生產者-緩衝區-消費者”這一結構過多時,資料從接收到最終被處理,是需要一個漫長的過程,因此,我們需要尋找一個平衡點。有兩種改進方式:
1)

圖3
如上圖,接收資料後,直接開啟非同步分析和處理過程。
2)
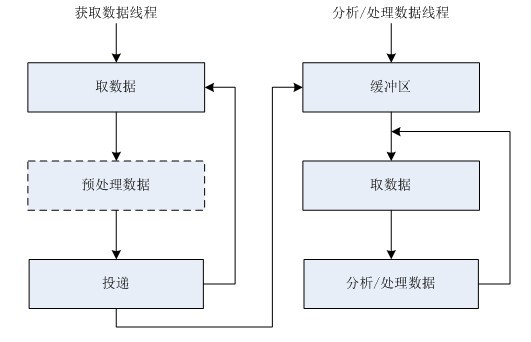
圖4
如上圖,資料接收後,將其寫入緩衝區,然後另外再開啟執行緒分析和處理資料,這個就把“資料分析”和“資料處理”合併在一塊了。這兩個嚴格來說耦合度比原來那個要高。
注:在通訊程式設計中,圖3適合UDP通訊,因為UDP每次接受到的資料都是一個完整的資料包,資料接收後直接開始分析處理,圖4適合TCP通訊,因為TCP傳輸資料是以“流”格式傳輸的,並且每次接收到的資料不一定是完整的,我們必須先將接收到的資料按順序寫入一個有序的緩衝區中,然後再從緩衝區中提取完整的資料進行分析處理。
框架與客戶端程式碼之間的關係
總結這個的主要原因是上次在網上看見有一個人問,使用基類引用指向一個派生類例項時,為什麼不能透過該引用訪問派生類中使用new關鍵字覆蓋基類的方法,而只能訪問到基類中的方法。我看了他給出的例項程式碼,發現其實根本就沒必要使用基類引用去指向派生類例項,純屬濫用。是的,好多時候我們不知道為什麼要那麼使用,只因為我們看見別人那樣用過,程式碼:
1 class People 2 { 3 string _name; 4 string _sex; 5 // … 6 public void Info() 7 { 8 ShowInfo(); 9 } 10 protected virtual void ShowInfo() 11 { 12 Console.WriteLine(“基本資訊 姓名:”+_name+” 性別:”+_sex); 13 } 14 } 15 class Student:People 16 { 17 //… 18 protected override void ShowInfo() 19 { 20 base.ShowInfo(); 21 Console.WriteLine(“附加資訊 職業:學生”); 22 } 23 } 24 25 class Teacher:People 26 { 27 //… 28 protected override void ShowInfo() 29 { 30 base.ShowInfo(); 31 Console.WriteLine(“附加資訊 職業:教師”); 32 } 33 }
以上三個型別,現在假設我要輸出某一型別物件的資訊,該怎麼寫?
public void Func(People p)
{
p.Info();
}
這是大多數人的寫法,理由很簡單,它既可以輸出Student的資訊也可以輸出Teacher的資訊,確實是這樣的,但是當你確定要輸出資訊的物件型別時(而且很多時候屬於這種情況),是沒必要這樣寫的,比如你確定要輸出資訊的物件型別為Student,那麼你完全可以這樣:
public void Func(Student s)
{
s.Info();
}
我真不明白為什麼你明明非常確定要使用哪個型別,卻偏偏要用基類引用代替派生類引用,就是因為大家常說的“依賴於抽象而非具體”嗎?這個話沒錯,但要看場合,當你不確定要使用哪個型別時,你可以用一個抽象引用(基類引用),當你已經非常確定了使用哪個型別時,你就沒必要再去使用一個抽象引用了,直接使用具體引用(派生類引用)。抽象引用能完成的東西,具體引用都能做到,反過來卻不成立,如果Student類中有一個public DoHomework(),你能用People型別的引用去訪問它嗎?你根本不能。
因此,可以很大膽地說,“依賴於抽象而非具體”是一個迫不得已的結論,如果程式設計世界裡沒有那麼多的不確定,完全不需要這個結論,誰會去使用一個不確定性的東西呢?可是,事實上程式設計世界裡有太多的不確定,表現最為明顯的就是框架中,之所以框架中有那麼多的不確定性,那是因為通常情況下,框架具有“通用性”(沒有通用性的也就不叫框架了),也就是說,框架可以使用在多個場合下,而框架編寫者則完全不知道每個具體場合是什麼樣的,有哪些功能,每個功能怎麼實現的,既然不知道具體情況,那麼框架編寫者只有使用一系列抽象引用臨時代替了。
現在既然不確定性無可避免,那麼,怎麼才能讓框架本身與客戶端程式碼(框架使用者編寫的程式碼)能夠很好的“協同工作”呢?此時,我們開啟我們發達的大腦,開始拼命想象,噴血聯想,協同工作?好像通訊中經常聽到的詞語,兩個遠端主機如果想要協同工作,雙方必須遵守同一個通訊協議,如下圖:

圖5
那麼,我們完全可以把“框架”當做服務端,框架使用者編寫的程式碼就為客戶端了,他們之間協同工作也應該遵守相同的協議,如下圖:
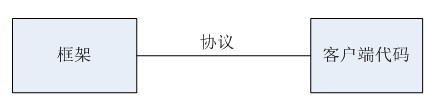
圖6
具體編碼中,這個協議就表現為介面(Interface)或基類(相對而言)這樣的東西,框架中使用這些東西訪問客戶端程式碼,客戶端程式碼也必須實現這些介面或者派生自這些基類。
像框架這種依賴於抽象的做法在解決通用性的同時,還能最大限度降低耦合度,框架編寫者完全不用關心使用者的具體實現,使用者只要遵守協議,怎麼實現不歸框架管。 當然也有缺陷,就是框架只能透過事先規定的協議去訪問客戶端程式碼,客戶端程式碼中如果有協議之外的東西,框架是訪問不到的。這就要求框架編寫者在編寫框架的時候考慮充分,將所有有可能涉及到的東西都歸納到協議之中。
本篇需結合前面三篇部落格(與“泵”有關的)一起閱讀。希望對各位有幫助。