相關文章連線:
程式設計之基礎:資料型別(一)
- 3.1 引用型別與值型別 41
- 3.1.1 記憶體分配 42
- 3.1.2 位元組序 44
- 3.1.3 裝箱與拆箱 45
- 3.2 物件相等判斷 46
- 3.2.1 引用型別判等 46
- 3.2.2 簡單值型別判等 47
- 3.2.3 複合值型別判等 47
- 3.3 賦值與複製 50
- 3.3.1 引用型別賦值 50
- 3.3.2 值型別賦值 51
- 3.3.3 傳參 52
- 3.3.4 淺複製 55
- 3.3.5 深複製 57
- 3.4 物件的不可改變性 60
- 3.4.1 不可改變性定義 60
- 3.4.2 定義不可改變型別 61
- 3.5 本章回顧 63
- 3.6 本章思考 63
資料型別是程式設計的基礎,每個程式設計師在使用一種平臺開發程式時,首先得知道平臺中有哪些資料型別,每種資料型別有哪些特點、又有著怎樣的記憶體分配等。熟練掌握每種型別不僅有利於提高我們的開發效率,還能使我們開發出來的程式更加穩定、健全。.NET中的資料型別共分為兩種:引用型別和值型別,它們無論在記憶體分配還是行為表現上,均有著非常大的差別。
3.1 引用型別與值型別
關於對引用型別和值型別的定義,聽得最多的是:值型別分配線上程棧中,而引用型別分配在堆中。這個定義並不準確(因為值型別也可以分配在堆中,而引用型別在某種場合也可以分配在棧中),或者說太抽象,它只是從記憶體分配的角度來區分值型別和引用型別,而對於記憶體分配,我們開發者是很難直觀地去辨別。如果從程式碼角度來講,.NET中的值型別是指"派生自System.ValueType的型別",而引用型別則指.NET中排除值型別在外的所有其它型別。下圖3-1顯示了.NET中的型別佈局:
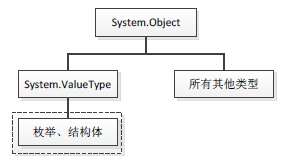
圖3-1 型別佈局
如上圖3-1所示,派生自System.ValueType的型別屬於值型別(圖中虛線部分,不包括System.ValueType),所有其它型別均為引用型別(包括System.Object、System.ValueType)。在以System.Object為根的龐大"繼承樹"中圈出一部分(圖中虛線框),那麼該小部分就屬於"值型別"。
注:以上對值型別和引用型別的解釋似乎有些難以理解,為什麼"根"是引用型別,而某些"枝葉"卻是值型別?這是因為.NET內部對派生自System.ValueType的型別做了些"手腳"(這些對我們來講是不可見的),使其跟其它型別(引用型別)具備不一樣的特性。另外,.NET中還有一些引用型別並不繼承自System.Object類,比如使用interface關鍵字定義的介面,它根本不在"繼承樹"的範圍之類,這樣看來,像我們平時聽見的"所有型別均派生自System.Object型別"的話似乎也不太準確,這些隱藏的不可告人的秘密都是.NET內部做的一些處理,大部分並沒有遵守主流規律。
通常值型別又分為兩部分:
1)簡單值型別:包括類似int、bool、long等.NET內建型別,它們本質上也是一種結構體;
2)複合值型別:使用Struct關鍵字定義的結構體,如System.Drawing.Point等。複合值型別可以由簡單值型別和引用型別組成,下面定義一個複合值型別:
1 //Code 3-1 2 3 struct MultipleValType 4 { 5 int a; //NO.1 6 object c; //NO.2 7 }
如上程式碼Code 3-1所示,MultipleValType型別包含兩個成員,一個簡單值型別(NO.1處),一個引用型別(NO.2處)。
值型別均預設派生自System.ValueType,又由於.NET不允許多繼承,因此我們既不可以在程式碼中顯示定義一個派生自System.ValueType的結構體,同時也不可以讓某個結構體繼承自其它結構體。
引用型別和值型別各有自己的特性,這具體表現在記憶體分配、型別賦值(複製)、型別判等幾個方面。
3.1.1 記憶體分配
本節開頭就談到,引用型別物件與值型別物件在記憶體中的儲存方式不相同,使用new關鍵字建立的引用型別物件儲存在(託管)堆中,而使用new關鍵字建立的值型別物件則分配在當前執行緒棧中。
注:堆和棧的具體概念請參見本書後面講"物件生命期"的第四章。另外,使用類似"int a = 0;"這種方式定義的簡單值型別變數,跟使用new關鍵字"Int32 a = new Int32();"效果一樣。
下面程式碼顯示建立一個引用型別物件和一個值型別物件:
1 //Code 3-2 2 3 class Ref //NO.1 4 { 5 int a; 6 Ref ref; 7 public Ref(int a,Ref ref) 8 { 9 this.a = a; 10 this.ref = ref; 11 } 12 } 13 struct Val1 //NO.2 14 { 15 int a; 16 bool b; 17 public Val1(int a,bool b) 18 { 19 this.a = a; 20 this.b =b; 21 } 22 } 23 struct Val2 //NO.3 24 { 25 int a; 26 Ref ref; 27 public Val2(int a,Ref ref) 28 { 29 this.a = a; 30 this.ref = ref; 31 } 32 } 33 class Program 34 { 35 static void Main() 36 { 37 Ref r = new Ref(0,new Ref(1,null)); //NO.4 38 Val1 v1 = new Val1(2,true); //NO.5 39 Val2 v2 = new Val2(3,r); //NO.6 40 } 41 }
如上程式碼Code 3-2所示,先定義了一個引用型別Ref(NO.1處),它包含一個值型別和一個引用型別成員;然後定義了兩個值型別(NO.2和NO.3處),前者只包含兩個簡單值型別成員(int和bool型別),後者包含一個簡單值型別和一個引用型別成員;最後分別各自建立一個物件(NO.4、NO.5以及NO.6處)。建立的三個物件在堆和棧中儲存情況見下圖3-2:
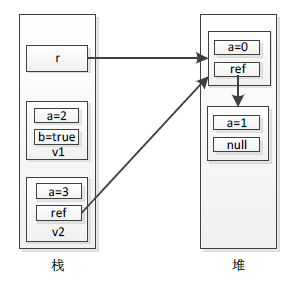
圖3-2 堆和棧中資料儲存情況
如上圖3-2所示,值型別物件v1和v2均存放在棧中,而引用型別物件均存放在堆中。
通常程式執行過程中,執行緒會讀寫各自對應的棧(因此有時候我們稱"執行緒棧"),也就是說,"棧"才是程式進行讀寫資料的地方,那麼程式怎麼訪問存放在堆中的資料(物件)呢?這就需要在棧中儲存一個對堆中物件的引用(索引),程式就可以透過該引用訪問到存放在堆中的物件。
注:引用型別物件一般分為兩部分:物件引用和物件例項,物件引用存放在棧中,程式使用該引用訪問堆中的物件例項;物件例項存放在堆中,裡面包含物件的資料內容,有關它們更詳細介紹,請參見本書後面有關"物件生命期"的第四章。
3.1.2 位元組序
我們知道,記憶體可以看作是一塊具有連續編號的儲存空間,編號有大有小,所以有高地址和低地址之分。如果以位元組為單元進行編號,那麼一塊記憶體可以用下圖3-3表示:
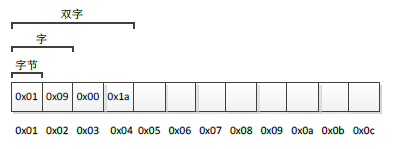
圖3-3 記憶體結構
如上圖3-3所示,從左往右,地址編號依次增大,左側稱為"低地址",右側稱為"高地址"。編號為0x01位元組中儲存數值為0x01,編號為0x02位元組中儲存數值為0x09,編號為0x03位元組中儲存數值為0x00,編號為0x04位元組中儲存數值為0x1a,每個位元組中均可存放一個0~255之間的數值。那麼這時候,如果我問你,圖3-3中最左側四個位元組表示的一個int型整數為多少?你可能會這樣去計算:0x01*2的24次方+0x09*2的16次方+0x00*2的8次方+0x1a*2的0次方,然後這樣解釋:高位位元組在左邊,低位位元組在右邊,將這樣的一個二進位制數轉換成十進位制數當然是這樣計算。事實上,這種計算方法不一定正確,因為沒有人告訴你高位位元組一定在左邊(低地址),而低位位元組一定在右邊(高地址)。
當佔用超過一個位元組的數值存放在記憶體中時,位元組之間必然會有一個排列順序,我們稱之為"位元組序",這種順序會因不同的硬體平臺而不同。高位位元組存放在低地址,而低位位元組存放在高地址(如剛才那樣),我們稱之為"Big-Endian";相反,高位位元組存放在高地址,而低位位元組存放在低地址,我們稱之為"Little-Endian"。在使用高階語言程式設計的今天,我們大部分時間不用去在意"位元組序"的差別,因為這些都有系統底層支撐模組幫我們判斷完成。
.NET中的值型別物件和引用型別物件在記憶體中同樣遵循"位元組序"的規律,如下面一段程式碼:
1 //Code 3-3 2 3 class Program 4 { 5 static void Main() 6 { 7 int a = 0x1a09; 8 int b = 0x2e22; 9 int c = b; 10 } 11 }
如上程式碼Code 3-3所示,變數a、b、c在棧中儲存結構如下圖3-4:
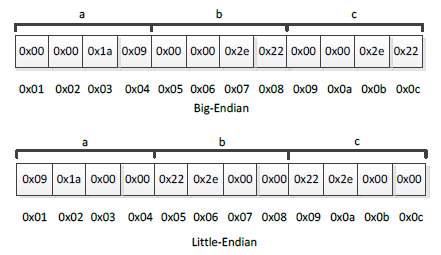
圖3-4 整型變數在棧中的儲存結構
如上圖3-4所示,圖中右邊為棧底(注意這裡,通常情況下,棧底位於高地址,棧頂位於低地址)。依次將c、b和a壓入棧,圖中上部分為按"Big-Endian"的位元組序存放資料,而圖中下部分為按"Little-Endian"位元組序存放資料。
3.1.3 裝箱與拆箱
前面講到,new出來的值型別物件存放在棧中,new出來的引用型別物件存放在堆中(棧中有引用指向堆中的例項)。如果我們把棧中的值型別轉存到堆中,然後透過一個引用訪問它,那麼這種操作叫"裝箱";相反,如果我們把裝箱後在堆中的值型別轉存到棧中,那麼就叫"拆箱"。下面程式碼Code 3-4表示裝箱和拆箱操作:
1 //Code 3-4 2 3 class Program 4 { 5 static void Main() 6 { 7 int a = 1; //NO.1 8 object b = a; //NO.2 9 int c = (int)b; //NO.3 10 } 11 }
如上程式碼Code 3-4所示,NO.1定義一個整型變數a,它存放在棧中,NO.2處進行裝箱操作,將棧中的a的值複製一份到堆中,並且使用b引用指向它,NO.3處將裝箱後堆中的值複製一份到棧中,整個過程棧和堆中的變化情況見下圖3-5:
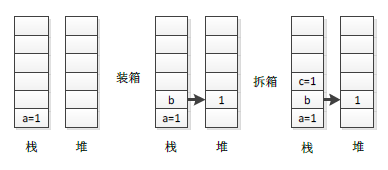
圖3-5 裝/拆箱棧和堆中變化過程
如上圖3-5所示,裝箱時將棧中值複製到堆中,拆箱時再將堆中的值複製到棧中。
使用時間短、主要是為了儲存資料的型別應該定義為值型別,存放在棧中,隨著執行緒中方法的呼叫完成,棧中的資料會不停地自動清理出棧,再加上棧一般情況下容量都比較有限,因此,建議型別設計的時候,值型別不要過大,而把那種體積大、程式需要長時間使用的型別定義為引用型別,存放在堆中,交給GC統一管理。同時,拆裝箱涉及到頻繁的資料移動,影響程式效能,應儘量避免頻繁的拆裝箱操作發生。
注:圖3-5中棧的儲存是連續的,而堆中儲存可以是隨機的,具體原因參見本書後續有關"物件生命期"的第四章。
3.2 物件相等判斷
在物件導向的世界裡,隨處充滿著"物件"的影子,那麼怎麼去判斷物件的相等性呢?所謂相等,指具有相同的組成、屬性、表現行為等,兩個物件相等並不一定要求相同。.NET物件的相等性判斷主要包括以下三個方面:
3.2.1 引用型別判等
引用型別分配在堆中,棧中只存放對堆中例項的一個引用,程式只能透過該引用才能訪問到堆中的物件例項。對引用型別來講,只有棧中的兩個引用指向堆中的同一個例項時,才能說這兩個物件相等(其實是同一個物件),其餘任何時候,物件都不相等,就算兩個物件中包含的資料一模一樣。用圖3-6表示為:
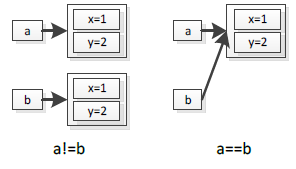
圖3-6 引用型別判等
如上圖3-6所示,左邊的a和b分別指向堆中不同的物件例項,雖然例項中包含相同的內容,但是它兩不相等;右邊的a和b指向堆中同一個例項,因此它們相等。
可以看出,對於引用型別來講,判斷兩個物件是否相等很簡單,直接判斷兩個物件引用是否指向堆中同一個例項,若是,則相等;其餘任何情況都不相等。
注:熟悉C/C++中指標的讀者應該很清楚,兩個不同的整型變數a和b,雖然a的值和b的值相等(比如都為1),但是它們兩的地址肯定不相等(參見前面講到的"位元組序")。.NET中引用型別判等其實就是比較物件在堆中的地址,不同的物件地址肯定不相等(就算內容相等)。另外,.NET中的String型別是一種特殊的引用型別,它不遵守引用型別的判等標準,只要兩個String包含相同的字串,那麼就相等,String型別判等更符合值型別的判等標準。
3.2.2 簡單值型別判等
簡單值型別包括.NET內建型別,比如int、bool、long等,這一類的比較準則跟現實中所說到的"相等"概念相似,只要兩者的值相等,那麼兩者就相等,見如下程式碼:
1 //Code 3-5 2 3 class Program 4 { 5 static void Main() 6 { 7 int a = 10; 8 int b = 11; 9 int c = 10; 10 } 11 }
如上程式碼Code 3-5所示,a和c相等,與b不相等。為了與引用型別判等進行區分,見下圖3-7:

圖3-7 簡單值型別在棧中的儲存情況
如上圖3-7所示,假設按照"Big-Endian"的位元組序排列,右邊是棧底,程式依次將c、b以及a壓入棧。我們可以看到,如果比較a和c的內容,"a==c"成立;但是如果比較a和c的地址,很明顯,a的(起始)地址為0x01,而c的(起始)地址為0x09,它兩的地址不相等。
簡單值型別的比較只關注兩者包含的內容,而不去關心兩者的地址,只要它們的內容相等,那麼它們就相等。複合值型別也是比較兩者包含的內容,只是複合值型別可能包含多個成員,需要挨個成員進行一一比較,詳見下一小節。
注:雖然筆者很不想在.NET的書籍中提到有關指標(地址)的話題,但是為了說明"引用型別判等"的標準與"值型別判等"的標準有何區別,還是稍微提到了指標。我們可以很容易對比發現,引用型別判等其實就是比較物件在堆中的地址,而物件在堆中的地址就是由棧中的引用來表示的,地址不同,棧中引用的值肯定不相等,把棧中引用想象成一個儲存堆中地址的變數,完全可以用簡單值型別的判等標準去判斷引用是否相等。
3.2.3 複合值型別判等
前面講過,複合值型別由簡單值型別、引用型別組成。既然也是值型別的一種,那麼它的判等標準和簡單值型別一樣,只要兩個物件包含的內容依次相等,那麼它們就相等。下面程式碼Code 3-6定義了兩種複合值型別,一種只由簡單值型別組成,一種由簡單值型別和引用型別組成:
1 //Code 3-6 2 3 struct MultipleValType1 //NO.1 4 { 5 int _a; 6 int _b; 7 public MultipleValType1(int a,int b) 8 { 9 _a = a; 10 _b = b; 11 } 12 } 13 struct MultipleValType2 //NO.2 14 { 15 int _a; 16 int[] _ref; 17 public MultipleValType2(int a,int[] ref) 18 { 19 _a = a; 20 _ref = ref; 21 } 22 } 23 class Program 24 { 25 static void Main() 26 { 27 MultipleValType1 mvt1 = new MultipleValType1(1,2); //NO.3 28 29 MultipleValType1 mvt2 = new MultipleValType1(1,2); //NO.4 30 // mvt1 equals mvt2 return true; 31 MultipleValType2 mvt3 = new MultipleValType2(2,new int[]{1,2,3}); //NO.5 32 MultipleValType2 mvt4 = new MultipleValType2(2,new int[]{1,2,3}); //NO.6 33 //mvt3 equals mvt4 retturn false; 34 } 35 }
如上程式碼Code 3-6所示,建立兩個複合值型別,一個只包含簡單值型別成員(NO.1處),另一個包含簡單值型別成員和引用型別成員(NO.2處),最後建立了兩對物件mvt1和mvt2(NO.3和NO.4處)、mvt3和mvt4(NO.5和NO.6處),它們都存放在棧中。mvt1和mvt2相等,因為它兩包含相等的成員(_a都等於1,_b都等於2),相反,mvt3和mvt4卻不相等,雖然看起來它兩初始化是一樣的(_a都等於1,_ref都指向堆中一個int[]陣列,並且陣列中的值也相等),原因很簡單,按照前面關於"引用型別判等"的標準,mvt3中的_ref和mvt4中的_ref根本就不是指向堆中同一個物件例項(即mvt3._ref!=mvt4._ref)。為了更好地理解這其中的區別,請見下圖3-8:
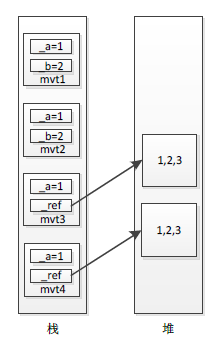
圖3-8 複合值型別記憶體分配
如上圖3-8所示,建立的4個物件均存放在棧中,mvt1和mvt2包含相等的成員,因此它兩相等,但是mvt3和mvt4包含的引用型別成員_ref並不相等,它們指向堆中不同的物件例項,因此mvt3和mvt4不相等。
對於值型別而言,判斷物件是否相等需要按以下幾個步驟:
(1)若是簡單值型別,則直接比較兩者內容,如int、bool等;
(2)若是複合值型別,則遍歷對應成員:
1)若成員是簡單值型別,則按照"簡單值型別判等"的標準進行比較;
2)若成員是引用型別,則按照"引用型別判等"的標準進行比較;
3)若成員是複合值型別,則遞迴判斷。
值型別判等是一個"遞迴"的過程,只要遞迴過程中有一次比較不相等,那麼整個物件就不相等。詳見下圖3-9:
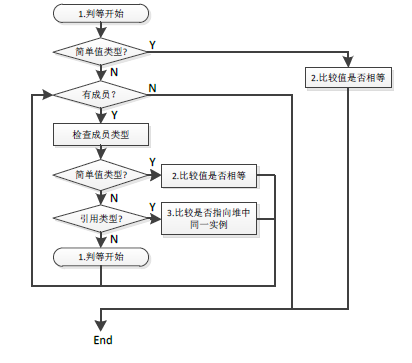
圖3-9 值型別判等流程
(本章未完)