Python網路爬蟲實戰專案程式碼大全(長期更新,歡迎補充)

Python網路爬蟲實戰專案程式碼大全(長期更新,歡迎補充)
WechatSogou [1]- 微信公眾號爬蟲。基於搜狗微信搜尋的微信公眾號爬蟲介面,可以擴充套件成基於搜狗搜尋的爬蟲,返回結果是列表,每一項均是公眾號具體資訊字典。
DouBanSpider [2]- 豆瓣讀書爬蟲。可以爬下豆瓣讀書標籤下的所有圖書,按評分排名依次儲存,儲存到Excel中,可方便大家篩選蒐羅,比如篩選評價人數>1000的高分書籍;可依據不同的主題儲存到Excel不同的Sheet ,採用User Agent偽裝為瀏覽器進行爬取,並加入隨機延時來更好的模仿瀏覽器行為,避免爬蟲被封。
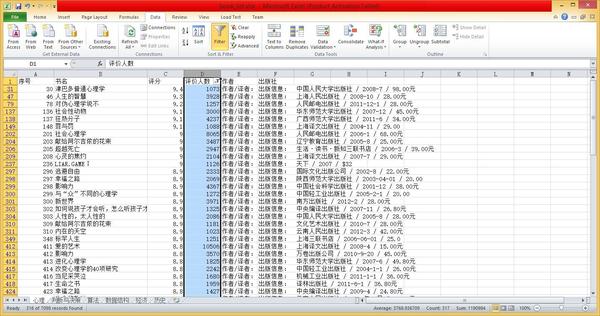
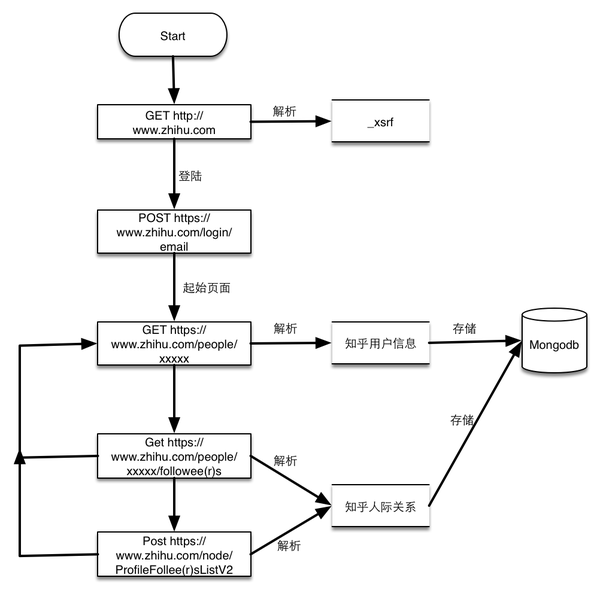
zhihu_spider [3]- 知乎爬蟲。此專案的功能是爬取知乎使用者資訊以及人際拓撲關係,爬蟲框架使用scrapy,資料儲存使用mongo
bilibili-user [4]- Bilibili使用者爬蟲。總資料數:20119918,抓取欄位:使用者id,暱稱,性別,頭像,等級,經驗值,粉絲數,生日,地址,註冊時間,簽名,等級與經驗值等。抓取之後生成B站使用者資料包告。
SinaSpider [5]- 新浪微博爬蟲。主要爬取新浪微博使用者的個人資訊、微博資訊、粉絲和關注。程式碼獲取新浪微博Cookie進行登入,可通過多賬號登入來防止新浪的反扒。主要使用 scrapy 爬蟲框架。
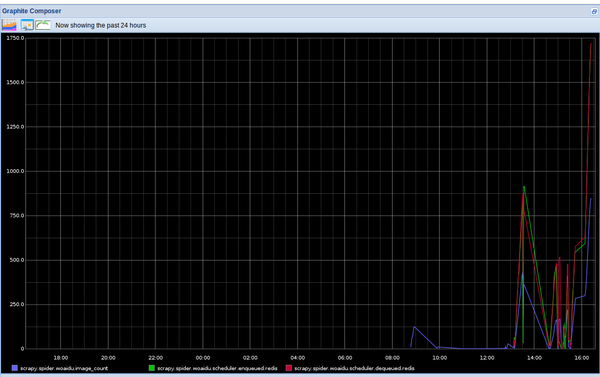
distribute_crawler [6]- 小說下載分散式爬蟲。使用scrapy,redis, mongodb,graphite實現的一個分散式網路爬蟲,底層儲存mongodb叢集,分散式使用redis實現,爬蟲狀態顯示使用graphite實現,主要針對一個小說站點。
CnkiSpider [7]- 中國知網爬蟲。設定檢索條件後,執行src/CnkiSpider.py抓取資料,抓取資料儲存在/data目錄下,每個資料檔案的第一行為欄位名稱。
LianJiaSpider [8]- 鏈家網爬蟲。爬取北京地區鏈家歷年二手房成交記錄。涵蓋鏈家爬蟲一文的全部程式碼,包括鏈家模擬登入程式碼。
scrapy_jingdong [9]- 京東爬蟲。基於scrapy的京東網站爬蟲,儲存格式為csv。
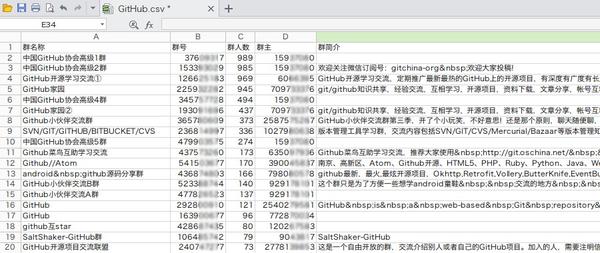
QQ-Groups-Spider [10]- QQ 群爬蟲。批量抓取 QQ 群資訊,包括群名稱、群號、群人數、群主、群簡介等內容,最終生成 XLS(X) / CSV 結果檔案。
 wooyun_public [11]-烏雲爬蟲。 烏雲公開漏洞、知識庫爬蟲和搜尋。全部公開漏洞的列表和每個漏洞的文字內容存在mongodb中,大概約2G內容;如果整站爬全部文字和圖片作為離線查詢,大概需要10G空間、2小時(10M電信頻寬);爬取全部知識庫,總共約500M空間。漏洞搜尋使用了Flask作為web server,bootstrap作為前端。
wooyun_public [11]-烏雲爬蟲。 烏雲公開漏洞、知識庫爬蟲和搜尋。全部公開漏洞的列表和每個漏洞的文字內容存在mongodb中,大概約2G內容;如果整站爬全部文字和圖片作為離線查詢,大概需要10G空間、2小時(10M電信頻寬);爬取全部知識庫,總共約500M空間。漏洞搜尋使用了Flask作為web server,bootstrap作為前端。
2016.9.11補充:
QunarSpider [12]- 去哪兒網爬蟲。 網路爬蟲之Selenium使用代理登陸:爬取去哪兒網站,使用selenium模擬瀏覽器登陸,獲取翻頁操作。代理可以存入一個檔案,程式讀取並使用。支援多程式抓取。
findtrip [13]- 機票爬蟲(去哪兒和攜程網)。Findtrip是一個基於Scrapy的機票爬蟲,目前整合了國內兩大機票網站(去哪兒 + 攜程)。
163spider [14] - 基於requests、MySQLdb、torndb的網易客戶端內容爬蟲
doubanspiders [15]- 豆瓣電影、書籍、小組、相簿、東西等爬蟲集
QQSpider [16]- QQ空間爬蟲,包括日誌、說說、個人資訊等,一天可抓取 400 萬條資料。
baidu-music-spider [17]- 百度mp3全站爬蟲,使用redis支援斷點續傳。
tbcrawler [18]- 淘寶和天貓的爬蟲,可以根據搜尋關鍵詞,物品id來抓去頁面的資訊,資料儲存在mongodb。
stockholm [19]- 一個股票資料(滬深)爬蟲和選股策略測試框架。根據選定的日期範圍抓取所有滬深兩市股票的行情資料。支援使用表示式定義選股策略。支援多執行緒處理。儲存資料到JSON檔案、CSV檔案。
BaiduyunSpider[20]-百度雲盤爬蟲。
[1]: GitHub - Chyroc/WechatSogou: 基於搜狗微信搜尋的微信公眾號爬蟲介面
[2]: GitHub - lanbing510/DouBanSpider: 豆瓣讀書的爬蟲
[3]: GitHub - LiuRoy/zhihu_spider: 知乎爬蟲
[4]: GitHub - airingursb/bilibili-user: Bilibili使用者爬蟲
[5]: GitHub - LiuXingMing/SinaSpider: 新浪微博爬蟲(Scrapy、Redis)
[6]: GitHub - gnemoug/distribute_crawler: 使用scrapy,redis, mongodb,graphite實現的一個分散式網路爬蟲,底層儲存mongodb叢集,分散式使用redis實現,爬蟲狀態顯示使用graphite實現
[7]: GitHub - yanzhou/CnkiSpider: 中國知網爬蟲
[8]: GitHub - lanbing510/LianJiaSpider: 鏈家爬蟲
[9]: GitHub - taizilongxu/scrapy_jingdong: 用scrapy寫的京東爬蟲
[10]: GitHub - caspartse/QQ-Groups-Spider: QQ Groups Spider(QQ 群爬蟲)
[12]: GitHub - lining0806/QunarSpider: 網路爬蟲之Selenium使用代理登陸:爬取去哪兒網站
[14]: GitHub - leyle/163spider: 爬取網易客戶端內容的小爬蟲。
[15]: GitHub - dontcontactme/doubanspiders: 豆瓣電影、書籍、小組、相簿、東西等爬蟲集 writen in Python
[16]: GitHub - LiuXingMing/QQSpider: QQ空間爬蟲(日誌、說說、個人資訊)
[17]: GitHub - Shu-Ji/baidu-music-spider: 百度mp3全站爬蟲
[18]: GitHub - pakoo/tbcrawler: 淘寶天貓 商品 爬蟲
[19]: GitHub - benitoro/stockholm: 一個股票資料(滬深)爬蟲和選股策略測試框架
[20]:GitHub - k1995/BaiduyunSpider: 愛百應,百度雲網盤搜尋引擎,爬蟲+網站
--------------------------
本專案收錄各種Python網路爬蟲實戰開原始碼,並長期更新,歡迎補充。
更多Python乾貨歡迎關注:
微信公眾號:Python中文社群
Python初級技術交流QQ群:152745094
Python高階技術交流QQ群:273186166
Python網路爬蟲組QQ群:206241755
PythonWeb開發組QQ群:577672548
Python量化交易策略組QQ群:264204289
Python資料分析挖掘組QQ群:539956362
Python自然語言處理組QQ群:570364809
--------------------------
Python學習資源下載:
Python學習思維腦圖大全彙總打包 (密碼請關注微信公眾號“Python中文社群”後回覆“思維”二字獲取)
相關文章
- Python網路爬蟲實戰專案大全!Python爬蟲
- Python網路爬蟲實戰專案大全 32個Python爬蟲專案demoPython爬蟲
- Python網路爬蟲實戰小專案Python爬蟲
- 網際網路流行詞~歡迎補充
- Python大型網路爬蟲專案開發實戰(全套)Python爬蟲
- Python網路爬蟲實戰Python爬蟲
- 專案--python網路爬蟲Python爬蟲
- 網路爬蟲(python專案)爬蟲Python
- 最新《30小時搞定Python網路爬蟲專案實戰》Python爬蟲
- Python3 大型網路爬蟲實戰 — 給 scrapy 爬蟲專案設定為防反爬Python爬蟲
- Python靜態網頁爬蟲專案實戰Python網頁爬蟲
- python網路爬蟲應用_python網路爬蟲應用實戰Python爬蟲
- Linux命令大全 歡迎補充 評論新增~Linux
- 資料抽取技術大全--歡迎大家補充
- 網路爬蟲——爬蟲實戰(一)爬蟲
- 【Python爬蟲9】Python網路爬蟲例項實戰Python爬蟲
- 精通 Python 網路爬蟲:核心技術、框架與專案實戰Python爬蟲框架
- python爬蟲例項專案大全Python爬蟲
- 視訊教程-Python網路爬蟲開發與專案實戰-PythonPython爬蟲
- python爬蟲-33個Python爬蟲專案實戰(推薦)Python爬蟲
- 網路爬蟲——Urllib模組實戰專案(含程式碼)爬取你的第一個網站爬蟲網站
- python3網路爬蟲開發實戰_Python3 爬蟲實戰Python爬蟲
- 網路爬蟲專案爬蟲
- python爬蟲實操專案_Python爬蟲開發與專案實戰 1.6 小結Python爬蟲
- webpack使用優化(持續更新,歡迎補充)Web優化
- 網路爬蟲——專案實戰(爬取糗事百科所有文章)爬蟲
- 大型商城網站爬蟲專案實戰網站爬蟲
- 爬蟲專案實戰(一)爬蟲
- 爬蟲實戰專案集合爬蟲
- 爬蟲實戰專案合集爬蟲
- 2019最新《網路爬蟲JAVA專案實戰》爬蟲Java
- Python爬蟲開發與專案實戰--分散式程式Python爬蟲分散式
- 網路爬蟲(六):實戰爬蟲
- python爬蟲例項專案大全-GitHub 上有哪些優秀的 Python 爬蟲專案?Python爬蟲Github
- 《Python3網路爬蟲開發實戰程式碼》基本庫使用Python爬蟲
- Python爬蟲開發與專案實戰——基礎爬蟲分析Python爬蟲
- Python爬蟲開發與專案實戰 3: 初識爬蟲Python爬蟲
- 乾貨分享!Python網路爬蟲實戰Python爬蟲