概要
storm cluster可以想像成為一個工廠,nimbus主要負責從外部接收訂單和任務分配。除了從外部接單,nimbus還要將這些外部訂單轉換成為內部工作分配,這個時候nimbus充當了排程室的角色。supervisor作為中層幹部,職責就是生產車間的主任,他的日常工作就是時刻等待著排程到給他下達新的工作。作為車間主任,supervisor領到的活是不用自己親力親為去作的,他手下有著一班的普通工人。supervisor對這些工人只會喊兩句話,開工,收工。注意,講收工的時候並不意味著worker手上的活已經幹完了,只是進入休息狀態而已。
topology的提交過程涉及到以下角色。
- storm client 負責將使用者建立的topology提交到nimbus
- nimbus 通過thrift介面接收使用者提交的topology
- supervisor 根據zk介面上提示的訊息下載最新的任務安排,並負責啟動worker
- worker worker內可以執行task,這些task要麼屬於bolt型別,要麼屬於spout型別
- executor executor是一個個執行的執行緒,同一個executor內可以執行同一種型別的task,即一個執行緒中的task要麼全部是bolt型別,要麼全部是spout型別
一個worker等同於一個程式,一個executor等同於一個執行緒,同一個執行緒中能夠執行一或多個tasks。在0.8.0版之前,一個task是對應於一個執行緒的,在0.8.0版本中引入了executor概念,變化引入之後,task與thread之間的一一對應關係就取消了,同時在zookeeper server中原本存在的tasks-subtree也消失了,有關這個變化,可以參考http://storm-project.net/2012/08/02/storm080-released.html
storm client
storm client需要執行下面這句指令將要提交的topology提交給storm cluster 假設jar檔名為storm-starter-0.0.1-snapshot-standalone.jar,啟動程式為 storm.starter.ExclamationTopology,給這個topology起的名稱為exclamationTopology.
#./storm jar $HOME/working/storm-starter/target/storm-starter-0.0.1-SNAPSHOT-standalone.jar storm.starter.ExclamationTopology exclamationTopology
這麼短短的一句話對於storm client來說,究竟意味著什麼呢? 原始碼面前是沒有任何祕密可言的,那好開啟storm client的原始碼檔案
def jar(jarfile, klass, *args): """Syntax: [storm jar topology-jar-path class ...] Runs the main method of class with the specified arguments. The storm jars and configs in ~/.storm are put on the classpath. The process is configured so that StormSubmitter (http://nathanmarz.github.com/storm/doc/backtype/storm/StormSubmitter.html) will upload the jar at topology-jar-path when the topology is submitted. """ exec_storm_class( klass, jvmtype="-client", extrajars=[jarfile, USER_CONF_DIR, STORM_DIR + "/bin"], args=args, jvmopts=["-Dstorm.jar=" + jarfile])
def exec_storm_class(klass, jvmtype="-server", jvmopts=[], extrajars=[], args=[], fork=False): global CONFFILE all_args = [ "java", jvmtype, get_config_opts(), "-Dstorm.home=" + STORM_DIR, "-Djava.library.path=" + confvalue("java.library.path", extrajars), "-Dstorm.conf.file=" + CONFFILE, "-cp", get_classpath(extrajars), ] + jvmopts + [klass] + list(args) print "Running: " + " ".join(all_args) if fork: os.spawnvp(os.P_WAIT, "java", all_args) else: os.execvp("java", all_args) # replaces the current process and never returns
exec_storm_class說白了就是要執行傳進來了的WordCountTopology類中main函式,再看看main函式的實現
public static void main(String[] args) throws Exception { TopologyBuilder builder = new TopologyBuilder(); builder.setSpout("spout", new RandomSentenceSpout(), 5); builder.setBolt("split", new SplitSentence(), 8).shuffleGrouping("spout"); builder.setBolt("count", new WordCount(), 12).fieldsGrouping("split", new Fields("word")); Config conf = new Config(); conf.setDebug(true); if (args != null && args.length > 0) { conf.setNumWorkers(3); StormSubmitter.submitTopology(args[0], conf, builder.createTopology()); } }
對於storm client側來說,最主要的函式StormSubmitter露出了真面目,submitTopology才是我們真正要研究的重點。
public static void submitTopology(String name, Map stormConf, StormTopology topology, SubmitOptions opts) throws AlreadyAliveException, InvalidTopologyException { if(!Utils.isValidConf(stormConf)) { throw new IllegalArgumentException("Storm conf is not valid. Must be json-serializable"); } stormConf = new HashMap(stormConf); stormConf.putAll(Utils.readCommandLineOpts()); Map conf = Utils.readStormConfig(); conf.putAll(stormConf); try { String serConf = JSONValue.toJSONString(stormConf); if(localNimbus!=null) { LOG.info("Submitting topology " + name + " in local mode"); localNimbus.submitTopology(name, null, serConf, topology); } else { NimbusClient client = NimbusClient.getConfiguredClient(conf); if(topologyNameExists(conf, name)) { throw new RuntimeException("Topology with name `" + name + "` already exists on cluster"); } submitJar(conf); try { LOG.info("Submitting topology " + name + " in distributed mode with conf " + serConf); if(opts!=null) { client.getClient().submitTopologyWithOpts(name, submittedJar, serConf, topology, opts); } else { // this is for backwards compatibility client.getClient().submitTopology(name, submittedJar, serConf, topology); } } catch(InvalidTopologyException e) { LOG.warn("Topology submission exception", e); throw e; } catch(AlreadyAliveException e) { LOG.warn("Topology already alive exception", e); throw e; } finally { client.close(); } } LOG.info("Finished submitting topology: " + name); } catch(TException e) { throw new RuntimeException(e); } }
submitTopology函式其實主要就幹兩件事,一上傳jar檔案到storm cluster,另一件事通知storm cluster檔案已經上傳完畢,你可以執行某某某topology了.
先看上傳jar檔案對應的函式submitJar,其呼叫關係如下圖所示

再看第二步中的呼叫關係,圖是我用tikz/pgf寫的,生成的是pdf格式。

在上述兩幅呼叫關係圖中,處於子樹位置的函式都曾在storm.thrift中宣告,如果此刻已經忘記了的點話,可以翻看一下前面1.3節中有關storm.thrift的描述。client側的這些函式都是由thrift自動生成的。
由於篇幅和時間的關係,在storm client側submit topology的時候,非常重要的函式還有TopologyBuilder.java中的原始碼。
nimbus
storm client側通過thrift介面向nimbus傳送了了jar並且通過預先定義好的submitTopologyWithOpts來處理上傳的topology,那麼nimbus是如何一步步的進行檔案接收並將其任務細化最終下達給supervisor的呢。
submitTopologyWithOpts
一切還是要從thrift說起,supervisor.clj中的service-handler具體實現了thrift定義的Nimbus介面,程式碼這裡就不羅列了,太佔篇幅。主要看其是如何實現submitTopologyWithOpts
(^void submitTopologyWithOpts [this ^String storm-name ^String uploadedJarLocation ^String serializedConf ^StormTopology topology ^SubmitOptions submitOptions] (try (assert (not-nil? submitOptions)) (validate-topology-name! storm-name) (check-storm-active! nimbus storm-name false) (.validate ^backtype.storm.nimbus.ITopologyValidator (:validator nimbus) storm-name (from-json serializedConf) topology) (swap! (:submitted-count nimbus) inc) (let [storm-id (str storm-name "-" @(:submitted-count nimbus) "-" (current-time-secs)) storm-conf (normalize-conf conf (-> serializedConf from-json (assoc STORM-ID storm-id) (assoc TOPOLOGY-NAME storm-name)) topology) total-storm-conf (merge conf storm-conf) topology (normalize-topology total-storm-conf topology) topology (if (total-storm-conf TOPOLOGY-OPTIMIZE) (optimize-topology topology) topology) storm-cluster-state (:storm-cluster-state nimbus)] (system-topology! total-storm-conf topology) ;; this validates the structure of the topology (log-message "Received topology submission for " storm-name " with conf " storm-conf) ;; lock protects against multiple topologies being submitted at once and ;; cleanup thread killing topology in b/w assignment and starting the topology (locking (:submit-lock nimbus) (setup-storm-code conf storm-id uploadedJarLocation storm-conf topology) (.setup-heartbeats! storm-cluster-state storm-id) (let [thrift-status->kw-status {TopologyInitialStatus/INACTIVE :inactive TopologyInitialStatus/ACTIVE :active}] (start-storm nimbus storm-name storm-id (thrift-status->kw-status (.get_initial_status submitOptions)))) (mk-assignments nimbus))) (catch Throwable e (log-warn-error e "Topology submission exception. (topology name='" storm-name "')") (throw e))))
storm cluster在zookeeper server上建立的目錄結構。目錄結構相關的原始檔是config.clj.
白話一下上面這個函式的執行邏輯,對上傳的topology作必要的檢測,包括名字,檔案內容及格式,好比你進一家公司上班之前做的體檢。這些工作都完成之後進入關鍵區域,是進入關鍵區域所以上鎖,呵呵。
normalize-topology
(defn all-components [^StormTopology topology] (apply merge {} (for [f thrift/STORM-TOPOLOGY-FIELDS] (.getFieldValue topology f) )))
一旦列出所有的components,就可以讀出這些component的配置資訊。
mk-assignments
在這關鍵區域內執行的重點就是函式mk-assignments,mk-assignment有兩個主要任務,第一是計算出有多少task,即有多少個spout,多少個bolt,第二就是在剛才的計算基礎上通過呼叫zookeeper應用介面,寫入assignment,以便supervisor感知到有新的任務需要認領。
先說第二點,因為邏輯簡單。在mk-assignment中執行如下程式碼在zookeeper中設定相應的資料以便supervisor能夠感知到有新的任務產生
(doseq [[topology-id assignment] new-assignments :let [existing-assignment (get existing-assignments topology-id) topology-details (.getById topologies topology-id)]] (if (= existing-assignment assignment) (log-debug "Assignment for " topology-id " hasn't changed") (do (log-message "Setting new assignment for topology id " topology-id ": " (pr-str assignment)) (.set-assignment! storm-cluster-state topology-id assignment) )))
呼叫關係如下圖所示
而第一點涉及到的計算相對繁雜,需要一一仔細道來。其實第一點中非常重要的課題就是如何進行任務的分發,即scheduling.
也許你已經注意到目錄src/clj/backtype/storm/scheduler,或者注意到storm.yaml中與scheduler相關的配置項。那麼這個scheduler到底是在什麼時候起作用的呢。mk-assignments會間接呼叫到這麼一個名字看起來奇怪異常的函式。compute-new-topology->executor->node+por,也就是在這麼很奇怪的函式內,scheduler被呼叫
_ (.schedule (:scheduler nimbus) topologies cluster) new-scheduler-assignments (.getAssignments cluster) ;; add more information to convert SchedulerAssignment to Assignment new-topology->executor->node+port (compute-topology->executor->node+port new-scheduler-assignments)]
schedule計算出來的assignments儲存於Cluster.java中,這也是為什麼new-scheduler-assignment要從其中讀取資料的緣由所在。有了assignment,就可以計算出相應的node和port,其實就是這個任務應該交由哪個supervisor上的worker來執行。
storm在zookeeper server上建立的目錄結構如下圖所示
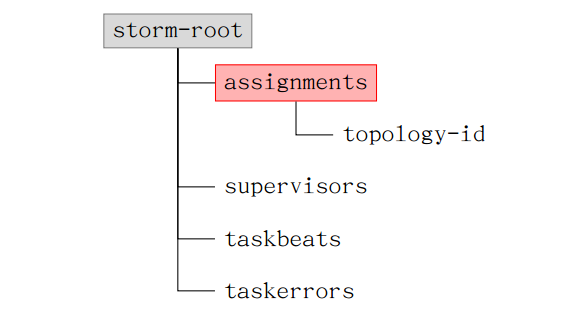
有了這個目錄結構,現在要解答的問題是在topology在提交的時候要寫哪幾個目錄?assignments目錄下會新建立一個新提交的topology的目錄,在這個topology中需要寫的資料,其資料結構是什麼樣子?
supervisor
一旦有新的assignment被寫入到zookeeper中,supervisor中的回撥函式mk-synchronize-supervisor立馬被喚醒執行
主要執行邏輯就是讀入zookeeper server中新的assignments全集與已經執行與本機上的assignments作比較,區別出哪些是新增的。在sync-processes函式中將執行具體task的worker拉起。
要想講清楚topology提交過程中,supervisor需要做哪些動作,最主要的是去理解下面兩個函式的處理邏輯。
- mk-synchronize-supervisor 當在zookeeper server的assignments子目錄內容有所變化時,supervisor收到相應的notification, 處理這個notification的回撥函式即為mk-synchronize-supervisor,mk-sychronize-supervisor讀取所有的assignments即便它不是由自己處理,並將所有assignment的具體資訊讀出。爾後判斷分析出哪些assignment是分配給自己處理的,在這些分配的assignment中,哪些是新增的。知道了新增的assignment之後,從nimbus的相應目錄下載jar檔案,使用者自己的處理邏輯程式碼並沒有上傳到zookeeper server而是在nimbus所在的機器硬碟上。
- sync-processes mk-synchronize-supervisor預處理過完與assignment相關的操作後,將真正啟動worker的動作交給event-manager, event-manager執行在另一個獨立的執行緒中,這個執行緒中進行處理的一個主要函式即sync-processes. sync-processes會將當前執行著的worker全部kill,然後指定新的執行引數,重新拉起worker.
(defn mk-synchronize-supervisor [supervisor sync-processes event-manager processes-event-manager] (fn this [] (let [conf (:conf supervisor) storm-cluster-state (:storm-cluster-state supervisor) ^ISupervisor isupervisor (:isupervisor supervisor) ^LocalState local-state (:local-state supervisor) sync-callback (fn [& ignored] (.add event-manager this)) assignments-snapshot (assignments-snapshot storm-cluster-state sync-callback) storm-code-map (read-storm-code-locations assignments-snapshot) downloaded-storm-ids (set (read-downloaded-storm-ids conf)) ;;read assignments from zookeeper all-assignment (read-assignments assignments-snapshot (:assignment-id supervisor)) new-assignment (->> all-assignment (filter-key #(.confirmAssigned isupervisor %))) ;;task在assignment中 assigned-storm-ids (assigned-storm-ids-from-port-assignments new-assignment) existing-assignment (.get local-state LS-LOCAL-ASSIGNMENTS)] (log-debug "Synchronizing supervisor") (log-debug "Storm code map: " storm-code-map) (log-debug "Downloaded storm ids: " downloaded-storm-ids) (log-debug "All assignment: " all-assignment) (log-debug "New assignment: " new-assignment) ;; download code first ;; This might take awhile ;; - should this be done separately from usual monitoring? ;; should we only download when topology is assigned to this supervisor? (doseq [[storm-id master-code-dir] storm-code-map] (when (and (not (downloaded-storm-ids storm-id)) (assigned-storm-ids storm-id)) (log-message "Downloading code for storm id " storm-id " from " master-code-dir) (download-storm-code conf storm-id master-code-dir) (log-message "Finished downloading code for storm id " storm-id " from " master-code-dir) )) (log-debug "Writing new assignment " (pr-str new-assignment)) (doseq [p (set/difference (set (keys existing-assignment)) (set (keys new-assignment)))] (.killedWorker isupervisor (int p))) (.assigned isupervisor (keys new-assignment)) (.put local-state LS-LOCAL-ASSIGNMENTS new-assignment) (reset! (:curr-assignment supervisor) new-assignment) ;; remove any downloaded code that's no longer assigned or active ;; important that this happens after setting the local assignment so that ;; synchronize-supervisor doesn't try to launch workers for which the ;; resources don't exist (doseq [storm-id downloaded-storm-ids] (when-not (assigned-storm-ids storm-id) (log-message "Removing code for storm id " storm-id) (rmr (supervisor-stormdist-root conf storm-id)) )) (.add processes-event-manager sync-processes) )))
注意加亮行
assignments-snapshot是去zookeeper server中的assignments子目錄讀取所有的topology-ids及其內容,會使用zk/get-children及zk/get-data原語。呼叫關係如下
assignments-snapshot-->assignment-info-->clusterstate/get-data-->zk/get-data
程式碼下載 (download-storm-code conf storm-id master-code-dir),storm client將程式碼上傳到nimbus,nimbus將其放到自己指定的目錄,這個目錄結構在nimbus所在機器的檔案系統上可以找到。supervisor現在要做的事情就是去將nimbus上的程式碼下載複製到本地。
(.add processes-event-manager sync-processes) 新增事件到event-manager,event-manager是一個獨立執行的執行緒,新新增的事件處理函式為sync-processes, sync-processes的主要功能在本節開始處已經描述。
(defn sync-processes [supervisor] (let [conf (:conf supervisor) ^LocalState local-state (:local-state supervisor) assigned-executors (defaulted (.get local-state LS-LOCAL-ASSIGNMENTS) {}) now (current-time-secs) allocated (read-allocated-workers supervisor assigned-executors now) keepers (filter-val (fn [[state _]] (= state :valid)) allocated) keep-ports (set (for [[id [_ hb]] keepers] (:port hb))) reassign-executors (select-keys-pred (complement keep-ports) assigned-executors) new-worker-ids (into {} (for [port (keys reassign-executors)] [port (uuid)])) ] ;; 1. to kill are those in allocated that are dead or disallowed ;; 2. kill the ones that should be dead ;; - read pids, kill -9 and individually remove file ;; - rmr heartbeat dir, rmdir pid dir, rmdir id dir (catch exception and log) ;; 3. of the rest, figure out what assignments aren't yet satisfied ;; 4. generate new worker ids, write new "approved workers" to LS ;; 5. create local dir for worker id ;; 5. launch new workers (give worker-id, port, and supervisor-id) ;; 6. wait for workers launch (log-debug "Syncing processes") (log-debug "Assigned executors: " assigned-executors) (log-debug "Allocated: " allocated) (doseq [[id [state heartbeat]] allocated] (when (not= :valid state) (log-message "Shutting down and clearing state for id " id ". Current supervisor time: " now ". State: " state ", Heartbeat: " (pr-str heartbeat)) (shutdown-worker supervisor id) )) (doseq [id (vals new-worker-ids)] (local-mkdirs (worker-pids-root conf id))) (.put local-state LS-APPROVED-WORKERS (merge (select-keys (.get local-state LS-APPROVED-WORKERS) (keys keepers)) (zipmap (vals new-worker-ids) (keys new-worker-ids)) )) (wait-for-workers-launch conf (dofor [[port assignment] reassign-executors] (let [id (new-worker-ids port)] (log-message "Launching worker with assignment " (pr-str assignment) " for this supervisor " (:supervisor-id supervisor) " on port " port " with id " id ) (launch-worker supervisor (:storm-id assignment) port id) id))) ))
worker
worker是被supervisor通過函式launch-worker帶起來的。並沒有外部的指令顯示的啟動或停止worker,當然kill除外, :).
worker的主要任務有
- 傳送心跳訊息
- 接收外部tuple的訊息
- 向外傳送tuple訊息
這些工作集中在mk-worker指定處理控制程式碼。原始碼在此處就不一一列出了。
executor
executor是通過worker執行mk-executor完成初始化過程。
(defn mk-executor [worker executor-id] (let [executor-data (mk-executor-data worker executor-id) _ (log-message "Loading executor " (:component-id executor-data) ":" (pr-str executor-id)) task-datas (->> executor-data :task-ids (map (fn [t] [t (task/mk-task executor-data t)])) (into {}) (HashMap.)) _ (log-message "Loaded executor tasks " (:component-id executor-data) ":" (pr-str executor-id)) report-error-and-die (:report-error-and-die executor-data) component-id (:component-id executor-data) ;; starting the batch-transfer->worker ensures that anything publishing to that queue ;; doesn't block (because it's a single threaded queue and the caching/consumer started ;; trick isn't thread-safe) system-threads [(start-batch-transfer->worker-handler! worker executor-data)] handlers (with-error-reaction report-error-and-die (mk-threads executor-data task-datas)) threads (concat handlers system-threads)] (setup-ticks! worker executor-data) (log-message "Finished loading executor " component-id ":" (pr-str executor-id)) ;; TODO: add method here to get rendered stats... have worker call that when heartbeating (reify RunningExecutor (render-stats [this] (stats/render-stats! (:stats executor-data))) (get-executor-id [this] executor-id ) Shutdownable (shutdown [this] (log-message "Shutting down executor " component-id ":" (pr-str executor-id)) (disruptor/halt-with-interrupt! (:receive-queue executor-data)) (disruptor/halt-with-interrupt! (:batch-transfer-queue executor-data)) (doseq [t threads] (.interrupt t) (.join t)) (doseq [user-context (map :user-context (vals task-datas))] (doseq [hook (.getHooks user-context)] (.cleanup hook))) (.disconnect (:storm-cluster-state executor-data)) (when @(:open-or-prepare-was-called? executor-data) (doseq [obj (map :object (vals task-datas))] (close-component executor-data obj))) (log-message "Shut down executor " component-id ":" (pr-str executor-id))) )))
上述程式碼中mk-threads用來為spout或者bolt建立thread.
mk-threads使用到了clojure的函式過載機制,借用一下java或c++的術語吧。在clojure中使用defmulti來宣告一個重名函式。
mk-threads函式有點長而且邏輯變得更為複雜,還是先從大體上有個概念為好,再去慢慢檢視細節。
- async-loop 執行緒執行的主函式,類似於pthread_create中的引數start_routine
- tuple-action-fn spout和bolt都會收到tuple,處理tuple的邏輯不同但有一個同名的處理函式即是tuple-action-fn
- event-handler 在這個建立的執行緒中又使用了disruptor模式,disruptor模式一個重要的概念就是要定義相應的event-handler。上面所講的tupleaction-fn就是在event-handler中被處理。
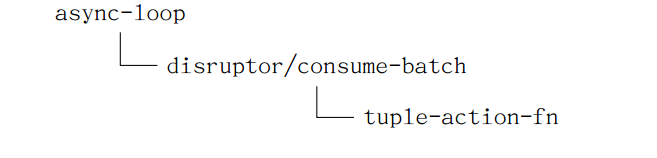
呼叫邏輯如下圖所示
spout
先來看看如果是spout,mk-threads的處理步驟是啥樣的,先說這個async-loops
[(async-loop (fn [] ;; If topology was started in inactive state, don't call (.open spout) until it's activated first. (while (not @(:storm-active-atom executor-data)) (Thread/sleep 100)) (log-message "Opening spout " component-id ":" (keys task-datas)) (doseq [[task-id task-data] task-datas :let [^ISpout spout-obj (:object task-data) tasks-fn (:tasks-fn task-data) send-spout-msg (fn [out-stream-id values message-id out-task-id] (.increment emitted-count) (let [out-tasks (if out-task-id (tasks-fn out-task-id out-stream-id values) (tasks-fn out-stream-id values)) rooted? (and message-id has-ackers?) root-id (if rooted? (MessageId/generateId rand)) out-ids (fast-list-for [t out-tasks] (if rooted? (MessageId/generateId rand)))] (fast-list-iter [out-task out-tasks id out-ids] (let [tuple-id (if rooted? (MessageId/makeRootId root-id id) (MessageId/makeUnanchored)) out-tuple (TupleImpl. worker-context values task-id out-stream-id tuple-id)] (transfer-fn out-task out-tuple overflow-buffer) )) (if rooted? (do (.put pending root-id [task-id message-id {:stream out-stream-id :values values} (if (sampler) (System/currentTimeMillis))]) (task/send-unanchored task-data ACKER-INIT-STREAM-ID [root-id (bit-xor-vals out-ids) task-id] overflow-buffer)) (when message-id (ack-spout-msg executor-data task-data message-id {:stream out-stream-id :values values} (if (sampler) 0)))) (or out-tasks []) ))]] (builtin-metrics/register-all (:builtin-metrics task-data) storm-conf (:user-context task-data)) (builtin-metrics/register-queue-metrics {:sendqueue (:batch-transfer-queue executor-data) :receive receive-queue} storm-conf (:user-context task-data)) (.open spout-obj storm-conf (:user-context task-data) (SpoutOutputCollector. (reify ISpoutOutputCollector (^List emit [this ^String stream-id ^List tuple ^Object message-id] (send-spout-msg stream-id tuple message-id nil) ) (^void emitDirect [this ^int out-task-id ^String stream-id ^List tuple ^Object message-id] (send-spout-msg stream-id tuple message-id out-task-id) ) (reportError [this error] (report-error error) ))))) (reset! open-or-prepare-was-called? true) (log-message "Opened spout " component-id ":" (keys task-datas)) (setup-metrics! executor-data) (disruptor/consumer-started! (:receive-queue executor-data)) (fn [] ;; This design requires that spouts be non-blocking (disruptor/consume-batch receive-queue event-handler) ;; try to clear the overflow-buffer (try-cause (while (not (.isEmpty overflow-buffer)) (let [[out-task out-tuple] (.peek overflow-buffer)] (transfer-fn out-task out-tuple false nil) (.removeFirst overflow-buffer))) (catch InsufficientCapacityException e )) (let [active? @(:storm-active-atom executor-data) curr-count (.get emitted-count)] (if (and (.isEmpty overflow-buffer) (or (not max-spout-pending) (< (.size pending) max-spout-pending))) (if active? (do (when-not @last-active (reset! last-active true) (log-message "Activating spout " component-id ":" (keys task-datas)) (fast-list-iter [^ISpout spout spouts] (.activate spout))) (fast-list-iter [^ISpout spout spouts] (.nextTuple spout))) (do (when @last-active (reset! last-active false) (log-message "Deactivating spout " component-id ":" (keys task-datas)) (fast-list-iter [^ISpout spout spouts] (.deactivate spout))) ;; TODO: log that it's getting throttled (Time/sleep 100)))) (if (and (= curr-count (.get emitted-count)) active?) (do (.increment empty-emit-streak) (.emptyEmit spout-wait-strategy (.get empty-emit-streak))) (.set empty-emit-streak 0) )) 0)) :kill-fn (:report-error-and-die executor-data) :factory? true :thread-name component-id)]))
對於spout來說,如何處理收到的資料呢,這一切都要與disruptor/consume-batch關聯起來,注意上述程式碼紅色加亮部分內容。
再看event-handler的定義, event-handler (mk-task-receiver executor-data tuple-action-fn)。上面的呼叫關係圖就可以串起來了。
spout中的tuple-action-fn定義如下,這個tuple-action-fn很重要,如果諸位看官還記得本博前一篇講解tuple訊息傳送途徑文章內容的話,tuple接收的處理邏輯盡在於此了。
(fn [task-id ^TupleImpl tuple] [stream-id (.getSourceStreamId tuple)] ondp = stream-id Constants/SYSTEM_TICK_STREAM_ID (.rotate pending) Constants/METRICS_TICK_STREAM_ID (metrics-tick executor-data task-datas tuple) (let [id (.getValue tuple 0) [stored-task-id spout-id tuple-finished-info start-time-ms] (.remove pending id)] (when spout-id (when-not (= stored-task-id task-id) (throw-runtime "Fatal error, mismatched task ids: " task-id " " stored-task-id)) (let [time-delta (if start-time-ms (time-delta-ms start-time-ms))] (condp = stream-id ACKER-ACK-STREAM-ID (ack-spout-msg executor-data (get task-datas task-id) spout-id tuple-finished-info time-delta) ACKER-FAIL-STREAM-ID (fail-spout-msg executor-data (get task-datas task-id) spout-id tuple-finished-info time-delta) ))) ;; TODO: on failure, emit tuple to failure stream ))))
有關bolt相關thread的建立與訊息接收處理函式就不一一羅列了,各位自行分析應該沒有問題了。